📝 Guest post: Testing feature logic, transformations, and feature pipelines with pytest*
Was this email forwarded to you? Sign up here Operational machine learning requires the offline and online testing of both features and models. In this guest post, our partner Hopsworks shows you how to design, build, and run offline tests for features with pytest and the Hopsworks feature store. The full version of the article on Hopsworks contains a detailed overview of the examples; their source code is available here on github.
IntroductionIt's no secret that in MLOps, data must be transformed into a suitable numerical format, and embeddings are becoming an increasingly popular way to compress large data sets into more manageable features – two things Python excels at. Automated testing of feature pipelines and training pipelines are must-haves for operationalizing machine learning using Enterprise data. Python has a huge role to play in feature engineering (not just model training), not least because it's the language of choice of data science, but also because feature engineering with tabular data is more than just computing aggregations with +SQL. So to this end, here are some useful guidelines and examples on how you can test your feature logic and your feature pipelines with pytest.
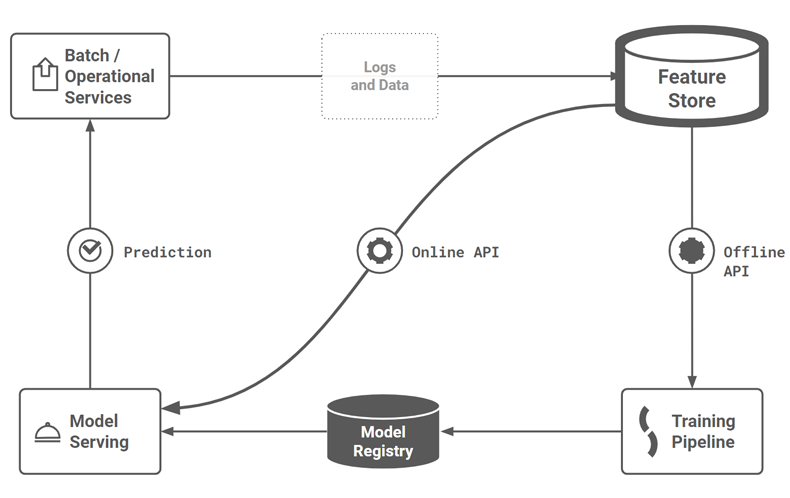
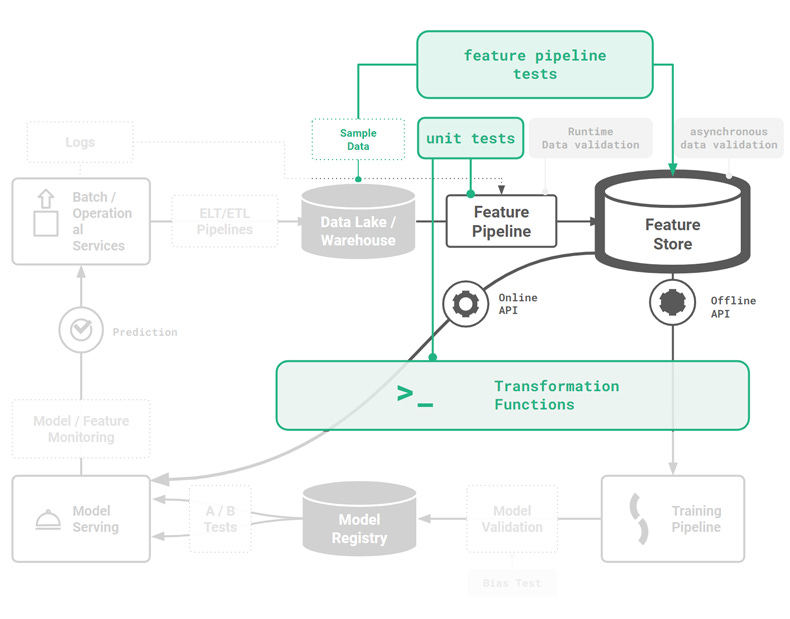
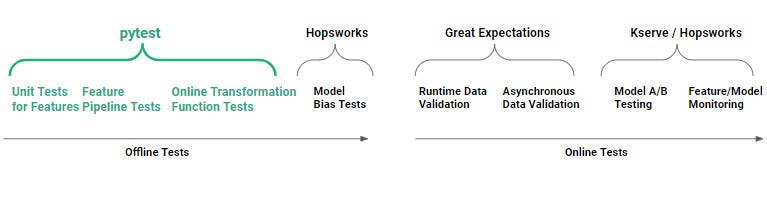
How can Pytest be used to execute unit tests for feature logicUnit tests for feature engineering validate that the code that computes your feature correctly implements the specification defined by the unit test itself. Unit tests are defined on functions. For feature engineering, this means that if you want to unit test a feature, you should factor your code so that the feature is computed by a single function. The unit test should be designed to guarantee invariants, preconditions and postconditions for the feature logic you wrote. With your unit tests in place, if somebody changes the implementation of the feature logic and it violates the feature specification, your unit test should detect the broken implementation of the feature logic with a failed assertion. This should help you catch errors before they affect downstream users of your features – the data scientists using the feature to create training data and the ML engineer using the feature to build feature vectors for online (operational) models. Pytest is a unit testing framework for Python that is mainly used for writing tests for APIs. You can install pytest as follows: pip install pytest Pytest is built on three main concepts: test functions, assertions, and test setup. In pytest, unit tests may be written either as functions or as methods in classes. Pytest has a naming convention to automatically discover test modules/classes/functions. A test class must be named “Test*”, and test functions or methods must be named “test_*”. The following figure shows that pytest is run during development as offline tests, not when feature pipelines have been deployed to production (online tests).
Python directory structureIt is typically a good idea to store your tests in separate files in a dedicated directory outside of your actual feature engineering code, as this separates the code for feature engineering from the code for testing. The following directory structure is a popular way to organize your feature engineering code and your tests, with your feature engineering in the features directory and your unit tests in the test_features directory: ┣ features ┃ ┣ transformation_functions.py ┃ ┗ feature_engineering.py ┣ test_features ┃ ┗ test_features.py ┗ If you use the above directory structure, but you don’t have a setup.py file (and you depend on default Python behavior of putting the current directory in sys.path), to run your unit tests, you will need to run the following from the root directory: python -m pytest A testing methodologyYou should start with a methodology for structuring test cases, such as the arrange, act, assert pattern that arranges the inputs and targets, acts on the target behavior, and asserts expected outcomes. This is the structure we use in the examples in this article. However, how do you know what to test and how to test it? Testing is not always required for all features. If the feature is a revenue driver at your company, then you probably should test it thoroughly, but if your feature is experimental, then maybe it requires minimal or no testing. That said, our preferred testing methodology for features is a simple recipe:
This methodology will help get you started, but it is not a panacea. For example, imagine you wrote a feature to compute monthly aggregations, but you forgot to include code handling the leap year. With the methodology, you would not see that the leap year code path was not covered in test code coverage. Only when you first discover the bug will you fix it, and then you should write a unit test to ensure that you don’t have a regression where the leap year bug appears again. What will help is testing with more edge cases in your input data and anticipating edge cases. Although there are different schools of thought regarding test-driven development, we do not think that test-first development is productive when you are experimenting. A good way to start is to list out what you want to test. Then decide if you want to test offline (using pytest) or at runtime (with data validation checks, such as Great Expectations). If you have a choice between offline and online tests, offline tests are generally preferred as problems can be identified during development and offline tests do not add runtime overhead. Unit test for a transformation functionIf your feature store stores your city names as a string (which is good for exploratory data analysis), you will still need to transform that string into a numerical format when you want to (1) train a model and (2) predict with the model (inference). A potential source of error here is when you have separate systems for model training and model inference. With two different systems, it may happen that you unwittingly have a different implementation of the (city-name to int) transformation function, as both systems are written in different programming languages or have different code bases. This problem is known as training-serving skew. Transformation functions prevent training-serving skew by providing a single piece of code to transform an input feature value into an output format used by the model for training and serving. For our city name, we can use the built-in LabelEncoder transformation functions to replace the categorical value (the city name) with a numeric value between 0 and the number of classes minus 1. However, let’s assume we also want to use the click_time datetime column, from our sample-click-logs.csv file, as a feature. We need to encode it in a numerical format. Unit test for feature naming conventionsAssume that you want uniformity in your feature naming, so that different teams can quickly understand the feature being computed and its origin. Downstream clients soon come to programmatically depend on the naming convention for features, so any changes in your naming convention could break downstream clients. It is possible to perform a runtime check that the name follows the correct format but in an orchestrated feature pipeline, it makes more sense to enforce correct feature names statically with functions. Then, your naming convention can be validated with unit tests, so that any unplanned changes to the naming convention are detected during development. Now, we have looked at pytest for unit tests, let us look at pytest to run integration or end-to-end tests for feature pipelines. Pytest for feature pipelinesA feature pipeline is a program that can be run on a schedule or continuously that reads new input data from some data source, computes features using that input data, and writes the features to the feature store. A more technical description of a feature pipeline is that it is a program that reads data from one or more data sources and then orchestrates the execution of a dataflow graph of feature engineering steps for the input data, including data validation, aggregation, and transformations. Finally, it writes the engineered features (the output DataFrame (Pandas or Spark)) to a feature group. We can test feature pipelines, end-to-end, with pytest. A feature pipeline test validates that your pipeline works correctly end-to-end – that it correctly plugs together different steps, such as reading and processing data, feature engineering, and writes the features to the feature store. A simple feature pipeline test reads some sample data, engineers features, writes to the feature store, and then validates that the data it reads from the feature store is the same as the data written, and that the number of rows written was as expected. Feature pipeline tests are slower to run compared to unit tests because they need to connect to services and process some sample data. They also require data and infrastructure. You will need some sample data and a “dev” (development) feature store. In Hopsworks, you can create a new private project for each developer, where each project has the developer’s own private feature store. You may need to subsample and even anonymize production data to create the sample data for your pipeline. The sample data should be representative of the production data for your pipeline. Pytest for Jupyter notebooksYou can also use pytest to test your feature engineering code in your Jupyter notebook provided that you (1) refactor your feature engineering code into functions, and (2) convert your notebook to python file before running pytest. Luckily, nbmake enables you to easily convert your notebook into a Python file, enabling you to run pytest: pip install nbmake In our github code repository, we have a Jupyter notebook with the same feature engineering source code as earlier for converting IP addresses between string/int format and for mapping an IP address to its source city name. The same notebook also contains the feature pipeline code, so that all code needed for the pipeline is in a single file. Some other good tips for testing notebooks are to add:
For a more detailed overview of this tutorial, check out the full article on pytest. *This post was written by the Hopsworks team. We thank Hopsworks for their ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2022 Jesus Rodriguez, Ksenia Semenova Unsubscribe
|

Older messages
🥢 Edge#187: The Different Types of Data Parallelism
Tuesday, May 3, 2022
In this issue: we overview the different types of data parallelism; we explain TF-Replicator, DeepMind's framework for distributed ML training; we explore FairScale, a PyTorch-based library for
📌 Event: SuperAnnotate’s Free Webinar Series on Automated CV Pipelines is Live
Monday, May 2, 2022
Join the Upcoming Session
🔎🧠 Improving Language Models by Learning from the Human Brain
Sunday, May 1, 2022
Weekly news digest curated by the industry insiders
📌 Event: Understanding performance and availability for feature stores
Saturday, April 30, 2022
Your time is precious, we made it real simple
📝 Guest post: 2022 State of Data Practice Report - Key Findings Revealed*
Friday, April 29, 2022
In this Guest post, our partner Molecula introduces the 2022 State of Data Practice Report and reveals why many companies still struggle to implement AI/ML successfully. What the report covers: Top 3
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your