🟧 Edge#192: Inside Predibase, the Enterprise Declarative ML Platform
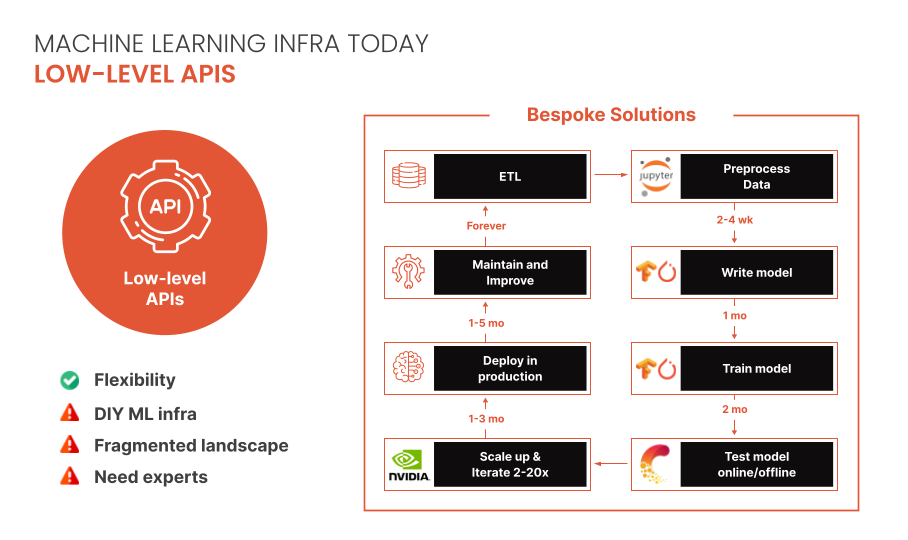
Was this email forwarded to you? Sign up here On Thursdays, we do deep dives into one of the freshest research papers or technology frameworks that is worth your attention. Our goal is to keep you up to date with new developments in AI and introduce to you the platforms that deal with the ML challenges. 💥 Deep Dive: Inside Predibase, the enterprise declarative machine learning platformLow-code ML platforms have received a lot of attention in the past few years, but haven’t yet achieved widespread adoption. Predibase looks to deliver a high-performance, low-code approach to machine learning (ML) for individuals and organizations who have tried operationalizing ML but found themselves re-inventing the wheel each step of the way. Like infrastructure-as-code simplified IT, Predibase’s declarative approach allows users to focus on the “what” of their ML tasks while leaving its system to figure out the “how”. Where things go wrong todayBuilding ML solutions at organizations today is time-consuming and requires specialized expertise. After several months of development, the result is typically a bespoke solution that is handed over to other engineers, is often hard to maintain in the long term and creates technical debt. The founders of Predibase see this as the COBOL era of machine learning, and believe the field needs its “SQL moment”.
This is a familiar pain for data science leaders, but many have been equally disenchanted by low-code/no-code automated machine learning solutions that haven’t scaled to the needs of their organization. Often, these tools are used for prototyping but fall short of being promoted to production.
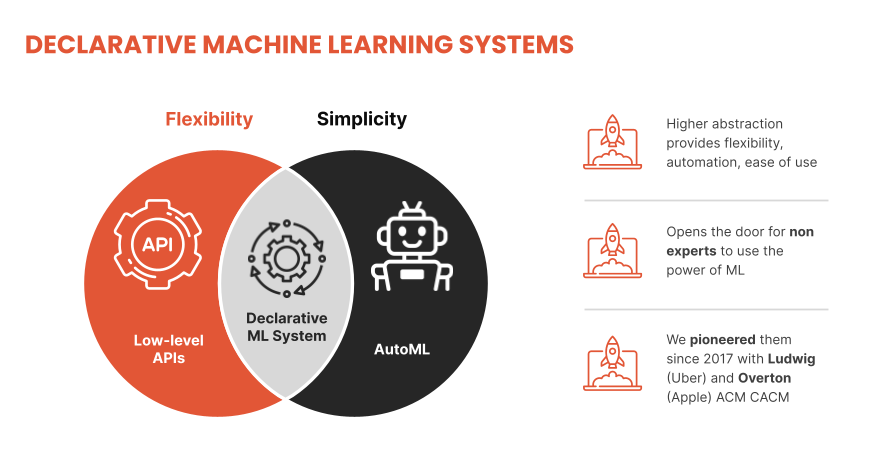
Furthermore, the tools that are built-for-scale (Spark, Airflow, Kubeflow) are not the same tools that are built-for experimentation. The path of least resistance in most data science teams becomes downloading some subset of the data to a local laptop and training a model using some amalgamation of Python libraries like Jupyter, Pandas, and PyTorch, and then throwing a model over the wall to an engineer tased with putting it in production. The solution is to strike the right abstraction for both ML modeling and infrastructure – one that provides an easy out-of-the-box experience while supporting increasingly complex use cases and allowing the users to iterate and improve their solutions. Declarative ML Systems: LEGO for Machine LearningThe basic idea behind declarative ML systems is to let users specify entire model pipelines as configurations and be intentional about the parts they care about while automating the rest. These configurations allow users to focus on the “what” rather than the “how” and have the potential to dramatically increase access and lower time-to-value.
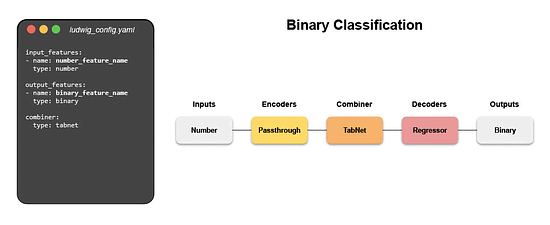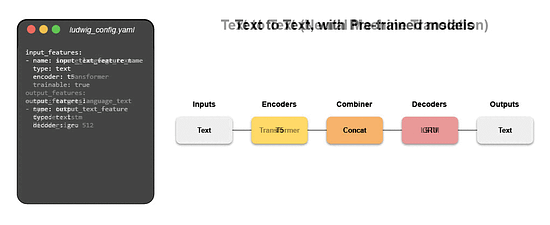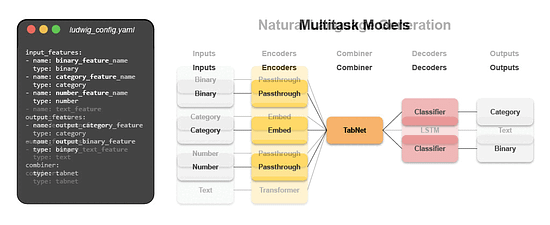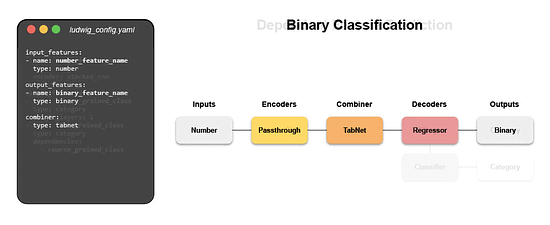
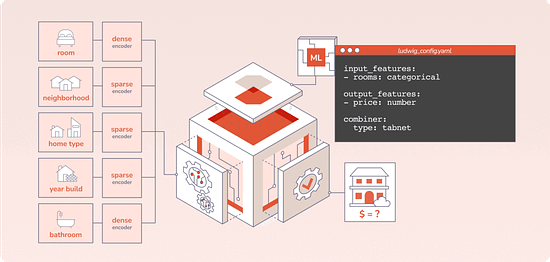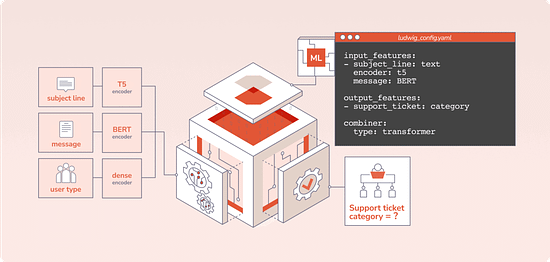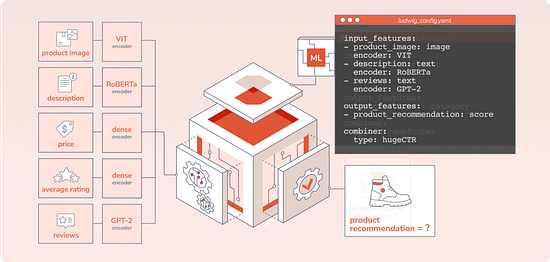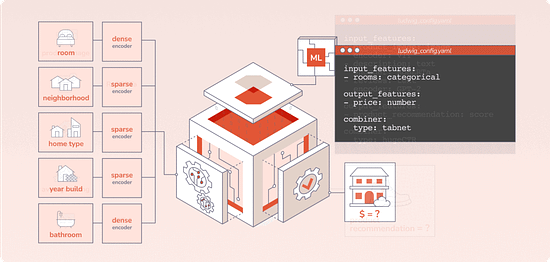
Declarative ML systems were pioneered by Ludwig at Uber and Overton at Apple. (check this interview about Ludwig and the importance of low-code ML we did with Piero Molino, creator of Ludwig, CEO of Predibase, last year). Ludwig served many different applications in production ranging from customer support automation, fraud detection and product recommendation while Overton processed billions of queries across multiple applications. Both frameworks made ML more accessible across stakeholders, especially engineers, and accelerated the pace of projects. Predibase is built on top of Ludwig, which allows users to define deep learning pipelines with a flexible and straightforward configuration system, suitable for a wide variety of tasks. Depending on the types of the data schema, users can compose and train state-of-the-art model pipelines on multiple modalities at once.
Writing a configuration file for Ludwig is easy, and provides users with ML best practices out-of-the-box, without sacrificing control. Users can choose which part of the pipeline they want to swap new pieces in for, including choosing among state-of-the-art model architectures and training parameters, deciding how to preprocess data and running a hyperparameter search, all via simple config changes. This declarative approach increases the speed of development, makes it easy to improve model quality through rapid iteration, and makes it effortless to reproduce results without the need to write any complex code. One of Ludwig’s open-source users referred to composing these configurations as “LEGO for deep learning”. But as any ML team knows, training a deep learning model alone isn’t the only hard part – building the infrastructure to operationalize the model from data to deployment is often even more complex. That’s where Predibase comes in. Predibase – Bringing declarative ML to the enterprise
Predibase brings the benefits of declarative ML systems to market with an enterprise-grade platform. There are three key things users do in Predibase:
Predibase's vision is to bring all the stakeholders of data & AI organizations together in one place, making collaboration seamless between data scientists working on models, data engineers working on deployments and product engineers using the models. The four pillars that were added on top of their open source foundations to make this reality are:
Predibase connects directly to your data sources, both structured data warehouses and unstructured data lakes. Any model trained in Predibase can be deployed to production with zero code changes and configured to automatically retrain as new data comes in because both experimentation and productionization go through the same unified declarative configuration.
Predibase features a cloud-native serverless infrastructure layer built on top of Horovod, Ray, and Kubernetes. It provides the ability to autoscale workloads across multi-node and multi-GPU systems in a way that is cost-effective and tailored to the model and dataset. This combines highly parallel data processing, distributed training, and hyperparameter optimization into a single workload, and supports both high throughput batch prediction as well as low-latency real-time prediction via REST.
The declarative abstraction that Predibase adopts makes it easy for users to modify model pipelines by editing their configuration. Defining models as configs allows Predibase to show differences between model versions over time in a concise way, making it easier to iterate and improve them. That also allows to introduce a unique alternative to AutoML: instead of running expensive experiments, Predibase suggests the best subsequent configurations to train depending on the explorations already conducted, creating a virtuous cycle of improvement.
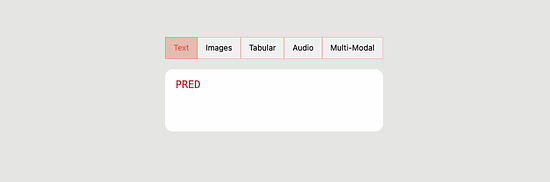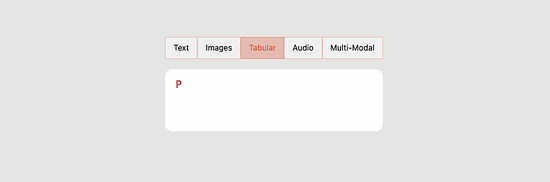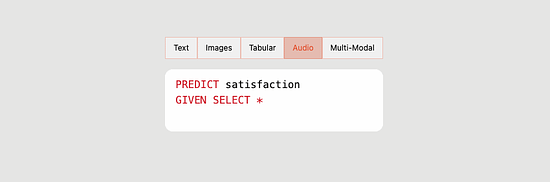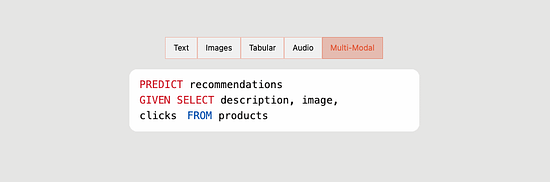
With the rise of the modern data stack, the number of data professionals comfortable with SQL has also grown. So, alongside its Python SDK and UI, Predibase also introduces PQL – Predictive Query Language – as an interface that brings ML closer to the data. Using PQL, users can train models and run predictive queries through a SQL-like syntax they are already familiar with. ConclusionDeclarative machine learning systems have dramatically increased the velocity and lowered the barrier-to-entry for machine learning projects at leading tech companies, and now Predibase is bringing the approach to all organizations with its enterprise platform built on open-source foundations. Predibase is currently available by invitation only, you can request a demo here: https://predibase.com/request-early-access You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2022 Jesus Rodriguez, Ksenia Semenova Unsubscribe
|



Older messages
📝 Guest post: How to Measure Your GPU Cluster Utilization, and Why That Matters*
Wednesday, May 18, 2022
In this article, Run:AI's team introduces rntop, a new super useful open-source tool that measures GPU cluster utilization. Learn why that's a critical measure for data scientists, as well as
📨 Edge#191: MPI – the Fundamental Enabler of Distributed Training
Tuesday, May 17, 2022
In this issue: we discuss the fundamental enabler of distributed training: message passing interface (MPI); +Google's paper about General and Scalable Parallelization for ML Computation Graphs; +
📌Event: Join the Largest Conference on MLOps: 3rd Annual MLOps World 2022! 🎉
Monday, May 16, 2022
We are happy to support the 3rd Annual MLOps World 2022! The MLOps World Committee would like to invite you this June 9-10th for a truly must-attend event, and an unforgettable experience in Toronto,
Google’s Big ML Week
Sunday, May 15, 2022
Weekly news digest curated by the industry insiders
📌 Last chance! Join us at apply() – the ML Data Engineering Conference
Friday, May 13, 2022
It's free
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your