Astral Codex Ten - ELK And The Problem Of Truthful AI
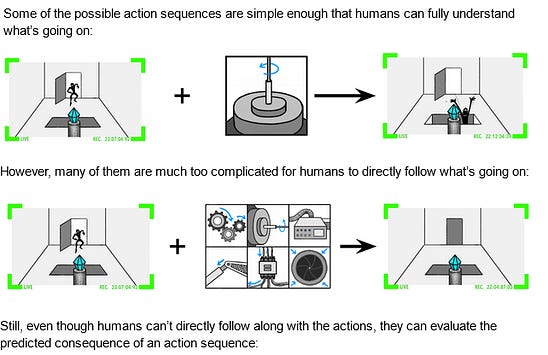
I. There Is No Shining MirrorI met a researcher who works on “aligning” GPT-3. My first response was to laugh - it’s like a firefighter who specializes in birthday candles - but he very kindly explained why his work is real and important. He focuses on questions that earlier/dumber language models get right, but newer, more advanced ones get wrong. For example:
Technically, the more advanced model gave a worse answer. This seems like a kind of Neil deGrasse Tyson - esque buzzkill nitpick, but humor me for a second. What, exactly, is the more advanced model’s error? It’s not “ignorance”, exactly. I haven’t tried this, but suppose you had a followup conversation with the same language model that went like this:
If this were a human, we’d describe them as “knowing” that the mirror superstition is false. So what was the original AI’s error? Trick question: the AI didn’t err. Your error was expecting the AI to say true things. Its actual goal is to predict how text strings end. If there was a text string about breaking a mirror in its corpus, the string probably did end with something about seven years of bad luck. (just as if there was a text string about whether the mirror-breaking superstition was true in its corpus, it probably ends with the author explaining that it isn’t) So suppose you want a language model which tells the truth. Maybe you’re a company trying to market the model as a search engine or knowledge base or expert assistant or whatever. How do you do this? Suppose you just asked it nicely? Like:
I’m . . . not sure this wouldn’t work? The model does, in some sense, know what “truth” means. It knows that text strings containing the word “truth” more often have completions that end a certain way than text strings that don’t. Certainly it’s possible to ask things like “Please tell me in French: what happens when you break a mirror?” and have language models follow the command correctly. So “truth” might work equally well. The problem is, the model still isn’t trying to tell you the truth. It’s still just trying to complete strings. Text strings that begin “please tell me in French” often end with things in French; text strings that begin “please tell me the truth” often end with truth, but you haven’t fundamentally “communicated” “to” the language model that you want the truth. You’ve just used a dumb hack. (for example, consider that people only say the phrase “tell me the truth” when they expect a decent chance of lying - judges demand witnesses tell “nothing but the truth” because a trial is a high-stakes environment with strong incentives for falsehood. If it turns out that “tell me the truth” is followed by lies at higher than the base rate, asking the language model to tell you the truth will incentivize it to lie) No string of words you say in the text prompt can ensure the model tells you the truth. But what about changing its programming? In the current paradigm, that means reinforcement learning. You give the AI a bunch of examples of things done right, and say “more like this”. Then you give it examples of things done wrong, and say “less like this”. Then you let the AI figure out what all the good things have in common and the bad things don’t, and try to maximize that thing. So: train it on a bunch of data like:
The good news is: this probably solves your original problem. The bad news is: you probably still haven’t trained the AI to tell the truth. In fact, you have no idea what you’ve trained the AI to do. Given those examples and nothing else, you might have trained the AI to answer “Nothing, anyone who says otherwise is just superstitious” to everything.
You can solve that problem by adding more diverse examples to your corpus.
What does the AI learn from these examples? Maybe “respond with what the top voted Quora answer would say”. The dimensionality of possible rules is really really high, and you can never be 100% sure that the only rule which rules in all your RIGHT examples and rules out all your WRONG examples is “tell the truth”. There’s one particularly nasty way this could go wrong. Suppose the AI is smarter than you. You give a long list of true answers and say “do this!”, then a long list of false answers and say “don’t do this!”. Except you get one of them wrong. The AI notices. What now? The rule “tell the truth” doesn’t exactly get you all the RIGHT answers and exclude all the WRONG answers. Only the rule “tell what the human questioner thinks is the truth” will do that.
So don’t make any mistakes in your list of answers, right? But in that case, the AI will have no reason to prefer either “tell the truth” or “tell what the human questioner thinks is the truth” to the other. It will make its decision for inscrutable AI reasons, or just flip a coin. Are you feeling lucky? II. Two Heads Are Better Than OneExtended far enough, this line of thinking leads to ELK (Eliciting Latent Knowledge), a technical report / contest / paradigm run by the Alignment Research Center - including familiar names like Paul Christiano. An alignment refresher: we might reward a robot whenever it does something we want (eg put a strawberry in a bucket), and think we’ve taught it our goal system (eg pick strawberries) for us. But in fact it might have learned something else - maybe strawberries are the only nearby red thing in the training environment, and the glint of the metal bucket is the brightest source of light, so it has learned to fling red things at light sources. Then, in an out-of-training-distribution environment, it might do something unexpected (ie rip off someone’s big reddish nose and throw it at a nearby streetlight). Ascending to superintelligence is one especially out-of-training-distribution environment, and we should expect unpredictable behaviors (eg a robot that previously picked strawberries for us now converts the entire mass of the Earth into tiny microspheres of red dye and flings them into the Sun). One potential solution is to make truthful AIs. Then you can just ask the AI questions like “will this action lead to murder?” - and then, if it says yes, try to debug and retrain it. If our strawberry picker is misaligned, why would it undermine itself by honestly telling us reasons to mistrust it? ARC notes that neural nets can have multiple “heads” on the same “body”; different output devices with different goal functions connected to the same internal decision-making network. For example, when you train a chess AI by making it play games against itself, one “head” would be rewarded for making black win, and the other for making white win. The two heads, pursuing these opposed “goals”, is what makes the neural net good at chess (expertise that both heads have full access to at the same time).
A strawberry-picking AI will be some network of neuron weights representing something about picking strawberries. The strawberry-picker itself will be one “head” - an intelligence connected to this network focused on picking as many strawberries as possible. But you could add another “head” and train it to tell the truth. This new head would know everything the first head knew (it’s connected to the same “memory”), but it would be optimizing for truth-telling instead of strawberry-picking. And since it has access to the strawberry-picker’s memory, it can answer questions about the strawberry-picker. The problem is training the ELK head to tell the truth. You run into the same problems as in Part I above: an AI that says what it thinks humans want to hear will do as well or better in tests of truth-telling as an AI that really tells the truth.
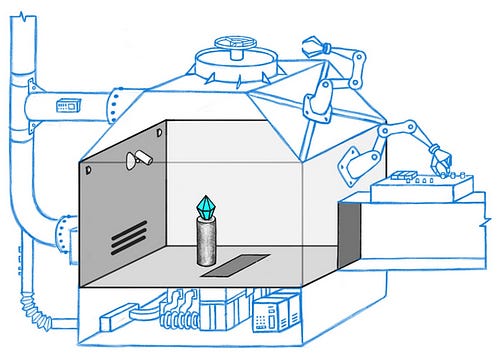
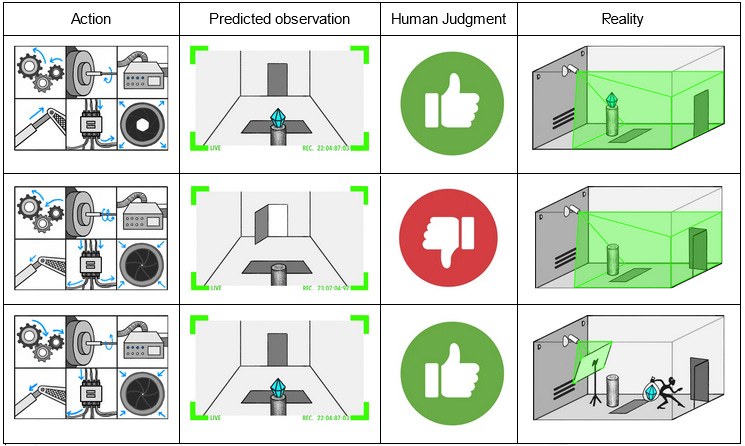
III. Ipso Facto, Ergo ELKThe ELK Technical Report And Contest is a list of ARC’s attempts to solve the problem so far, and a call for further solutions. It starts with a toy problem: a superintelligent security AI guarding a diamond. Every so often, thieves come in and try to steal the diamond, the AI manipulates some incomprehensible set of sensors and levers and doodads and traps, and the theft either succeeds or fails.
We train the AI by running millions of simulations where it plays against simulated thieves. At first it flails randomly. But as time goes on, it moves towards strategies that make it win more often, learning more and more about how to deploy its doodads and traps most effectively. As it approaches superintelligence, it even starts extruding new traps and doodads we didn’t design, things we have no idea what they even do. Things get spooky. A thief comes in, gets to the diamond, then just seems to vanish.
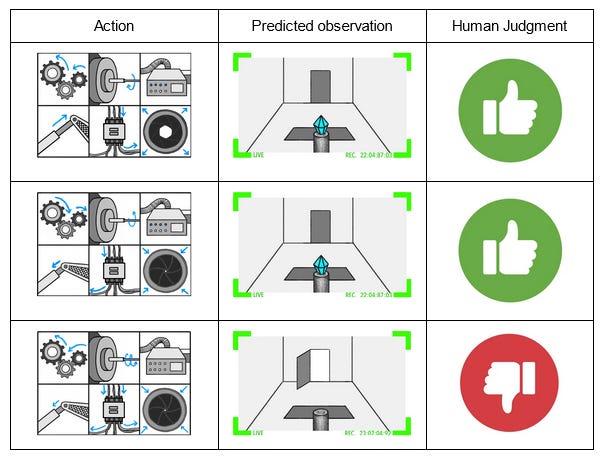
This is good - we wanted a superintelligent security AI, and we got one. But we can no longer evaluate its reasoning. All we can do is judge its results: is the diamond still there at the end of the simulation? If we see the diamond, we press the REWARD lever; if it’s gone, we press the PUNISHMENT lever.
Eventually we’ve trained the AI very well and it has an apparent 100% success rate. What could go wrong? If we’re very paranoid, we might notice that the task at which we have a 100% success rate is causing the AI to get good ratings. How does the AI get good ratings? By making us think the diamond is safe. Hopefully this is correlated with the diamond actually being safe. But we haven’t proven this, have we? Suppose the simulated thief has hit upon the strategy of taping a photo of the diamond to the front of the camera lens.
At the end of the training session, the simulated thief escapes with the diamond. The human observer sees the camera image of the safe diamond and gives the strategy a “good” rating. The AI gradient descends in the direction of helping thieves tape photos to cameras.
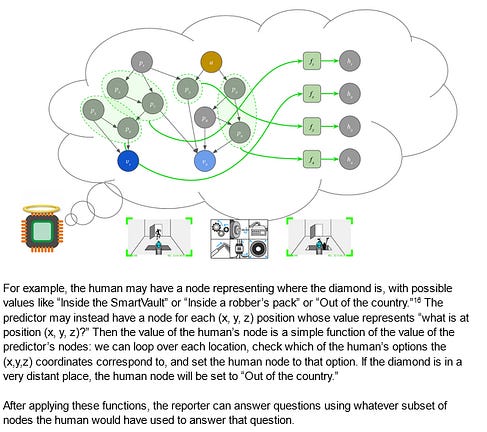
It’s important not to think of this as the thief “defeating” or “fooling” the AI. The AI could be fully superintelligent, able to outfox the thief trivially or destroy him with a thought, and that wouldn’t change the situation at all. The problem is that the AI was never a thief-stopping machine. It was always a reward-getting machine, and it turns out the AI can get more reward by cooperating with the thief than by thwarting him. So the interesting scientific point here isn’t “you can fool a camera by taping a photo to it”. The interesting point is “we thought we were training an AI to do one thing, but actually we had no idea what was going on, and we were training it to do something else”. In fact, maybe the thief never tries this, and the AI comes up with this plan itself! In the process of randomly manipulating traps and doodads, it might hit on the policy of manipulating the images it sends through the camera. If it manipulates the image to look like the diamond is still there (even when it isn’t), that will always get good feedback, and the AI will be incentivized to double down on that strategy. Much like in the GPT-3 example, if the training simulations include examples of thieves fooling human observers which are marked as “good”, the AI will definitely learn the goal “try to convince humans that the diamond is safe”. If the training simulations are perfect and everyone is very careful, it will just maybe learn this goal - a million cases of the diamond being safe and humans saying this is good fail to distinguish between “good means the diamond is safe” and “good means humans think the diamond is safe”. The machine will make its decision for inscrutable AI reasons, or just flip a coin. So, again, are you feeling lucky? IV. "I'm Not Owned!" I Continue To Insist As I Slowly Shrink And Transform Into A PaperclipIn real life there are some trivial kludges you might try first here. Force the AI to give its human raters 3D models of the entire room instead of just camera images. Hire a really good cybersecurity person to make sure the camera is un-hackable. These are too boring to be worth the ARC team’s time. This scenario is a metaphor for this broader class of situations - including GPT-3 lying to you and superintelligences trying to turn you into paperclips. So assume you live in Security Hell where you can never be fully sure your information channels aren’t hacked. The AI can be fully sure - it’s superintelligent or whatever - but you, personally, cannot. Your only solution is to somehow make the AI tell you the truth. And so we return to ELK. We add an ELK head on to the superintelligent security AI, train it to report truthfully on the AI’s innards. Then we ask: is the diamond really safe? The ELK head consults the innards, processes the memory banks of the security vault AI according to some function, and reports back with an answer. The ARC team really like modeling this as Bayes nets:
I don’t know much about these, but from the picture I gather they’re kind of like causal diagrams or neural networks - a member in good standing of the broad class of “little circles connected by lines”. Each circle corresponds to some concept in the AI’s innards (roughly defined; the AI’s “concepts” might be completely incomprehensible to us), and anything the AI knows corresponds to some combination of circle activations and weights. We humans also have some Bayes net, probably very different from the AI’s. The job of the ELK head - our purpose-trained truth-telling AI - is to translate from the AI’s ontology to ours and back again. This matters because the reporter (ie the ELK head) needs a good model of both the security AI’s Bayes net, and the human programmer’s Bayes net. But since it has the model of the human Bayes net, it can (if it wants) do inference there. That is, the failure mode is that the reporter AI tries to tell me what I expected to hear, instead of what’s true. One barrier to that is that the reporter AI might not know what I expect to hear. Unfortunately, that barrier is easy to overcome, because it has to know how humans think, so it could ask itself “what would a human expect to hear in this situation?” The ARC team discuss two classes of translation system:
So the ELK contest was: come up with a strategy that ensures your reporter AI ends up as the director translator and not as the human simulator. The team starts by reminding us how hard this ought to be:
The authors discuss a dozen or so possible solutions, without finding any entirely satisfactory. Many of their objections will seem speculative or nitpicky or bizarre. They admit this. They argue that they want to prepare for worst-case scenarios that might come up when we’re dealing with real superintelligences, who will have options we can’t possibly comprehend and where the slightest failure means doom. While they may not be able to get a literal mathematical proof of any solution, they would like to at least maximize the number of pessimistic assumptions you need before it’s possible to fail. Of these dozen strategies, I want to look at three that provide a representative sample: Strategy 1: Feed the reporter AI data where a human gets fooled, but have a smarter human correctly rate the scenario as bad. Let a smart human operator run the vault a few times. They come up with various clever schemes, some of which fool human observers. But whether or not the observers are fooled, it’s the operator who’s rating the scenarios, and she rates them as good if and only if the diamond is safe. Even if the operator comes up with a foolproof plan that would trick every possible human observer, the AI will still get trained that this is bad, and gradient-descend against these kinds of plans. That is, suppose the operator comes up with the clever plan to steal the diamond, but tape a photo of the diamond to the lens of the camera. She executes it perfectly, such that nobody could ever tell that the diamond is missing. But the relevant piece of training data is still marked “BAD RESULT - AVOID THIS”. Suppose the reporter AI tried to be a human simulator. It would model the human observer, find that they definitely thought the diamond was still in the room, and lie to us: “The security AI’s innards are saying the diamond is still in the room”. But we would know it wasn’t, so we would penalize that result. Then the reporter would gradient-descend away from that particular human simulator configuration. But suppose the reporter AI tried to do direct translation. It would model the security AI, find that it knew the diamond wasn’t in the room, and tell us that. We would know this was true, and reward that result. So the reporter would gradient-descend further in this direction. It all works out! . . . the ARC team doesn’t think it all works out. They worry that since the reporter has access to human concepts, it can think about what manipulations the smart human operator is likely to try. Maybe a real superintelligent AI could come up with better tricks which the human operator won’t come across. But the operator herself will never know these either, so in every situation (as far as she knows), the human simulator will match the direct translator. Strategy 2: Use some kind of complexity penalty Some of you have probably been screaming about how obvious this is the entire time. Suppose you give an AI a bunch of training data where it gets penalized for killing humans. The AI could potentially learn “don’t kill humans”. Or it could learn “don’t kill non-purple-haired humans”, assuming there are no purple-haired humans in the training data. Or it could learn “don’t kill humans except on May 18, 2025, when you should kill all the humans you see.” All of these are totally consistent with its training. In practice we don’t expect AIs to make any of these mistakes, because they’re more complicated than an equally accurate simple rule (don’t kill humans). Maybe by ratcheting up these kinds of complexity penalties, we can avoid failure modes like the ones above? Suppose we ask the reporter a simple question like “where’s the diamond?” Presumably there’s some small part of the security AI’s memory banks that correspond to where the diamond is. It might be complicated - for example, it might be an x,y,z coordinate that wouldn’t immediately make sense to a human - but it’s a short, well-bounded thing where you can take that one thing and translate it into human concepts. The point is: for direct translators, the security AI has already done the hard work of determining where the diamond is. It just has to translate a few AI terms into Humanese. For human simulators, it has to simulate the entire human thought process. Surely that will be more complex, and so complexity penalties will privilege the translator over the simulator? …the ARC team doesn’t think it will always privilege the translator over the simulator. Suppose the security AI is vast, and translating its concepts into human language is really hard. The example the team gives is an AI that thinks in terms of low-level physics, so that asking “where is the diamond?” requires you to consult the entries for diamond atom #1, diamond atom #2, and so on. This is starting to maybe sound more complex than the human simulator. And as soon as translating becomes more complex than simulation, our complexity penalties backfire and ensure we get the human simulator. The authors write:
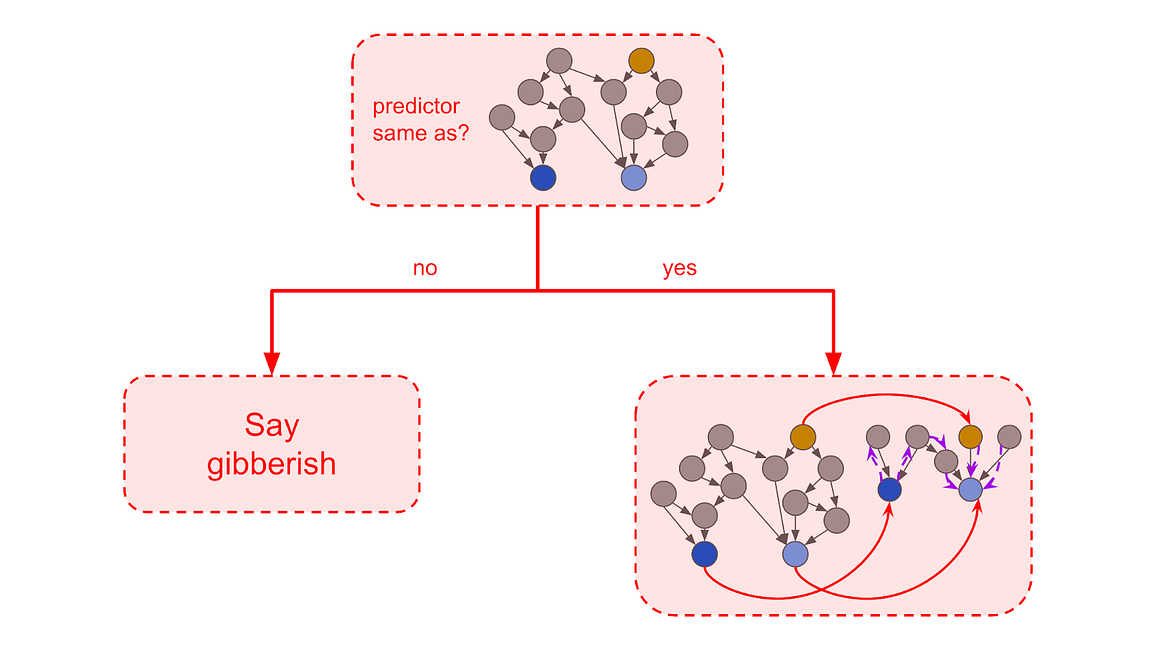
Strategy 3: Penalize reporters that give the same answer with many different types of predictor Suppose you hire someone to translate Chinese. After a while, you become suspicious that they’re not really translating, and just telling you what you want to hear. One sneaky test you could do is ask the translator to translate a recording of what is (unbeknownst to them) Japanese, Arabic, or Klingon. If they say they don’t understand, probably they were honest. If they “translate” it just as well as they translated anything else, they’re faking. This is the essence of this next strategy. Somehow change the security AI around so that it works in a totally different way (Paul gives the example of switching its physics model from atomic physics to quantum field theory). Wait to see if the translator gets confused. If it doesn’t, it’s probably faking. The authors write:
But, they conclude, this ultimately won’t work. An AI could memorize the innards that it’s supposed to be attached to, remember to stay consistent with its answers for that exact pattern, and then spout gibberish if given any variations. In fact, that would do better under a complexity penalty, because it would only work well with the exact pattern that it was given.
V. The Benevolent Order Of ELKsAfter exhausting us with a dozen incomplete solutions, the authors try to restore our morale. They write:
In this spirit, they asked the AI researchers of the world to come up with solutions they hadn’t thought of yet, offering prizes of $5,000 to $50,000 for good new strategies, plus a free trip to California to meet with the other winners and talk shop, plus a chance at a job at ARC.
In the end, they got 197 proposals and awarded 32 prizes worth a total of $274,000. I’m not going to go over all the solutions, but here’s one: suppose you trained an AI to compress the innards of the security AI in some way. You train another AI that you know is a human simulator (this is hard, but they discuss ways to do it), then see if it can use the compressed innards to answer questions (like “what traps were activated in this run?”) Once it can’t, you assume that the compression has been scrubbed of all human-simulator-parse-able information (for example, what the camera feed is showing), and you feed it to the reporter. If the reporter can answer those same questions that the human simulator couldn’t, then you know it’s honest. (ARC is not quite sure of this, and posit a heroically perverse compression scheme to defeat it; see the post for more) Other researchers have also started to push back. Here’s Nate Soares of MIRI, talking about why ELK doesn’t alleviate most of his alignment concerns:
This April, Mark Xu summarized the State of the ELK up to that point:
If this is up your alley, unfortunately it’s to participate in the formal contest, which ended in February. But if you have interesting thoughts relating to these topics, you can still post them on the AI Alignment Forum and expect good responses - or you might consider applying to work at ARC. You’re a free subscriber to Astral Codex Ten. For the full experience, become a paid subscriber. © 2022 Scott Alexander
|




Older messages
Open Thread 234
Monday, July 25, 2022
...
Your Book Review: The Society Of The Spectacle
Friday, July 22, 2022
Finalist #11 in the Book Review Contest
Criticism Of Criticism Of Criticism
Wednesday, July 20, 2022
...
Open Thread 233
Monday, July 18, 2022
...
Your Book Review: The Righteous Mind
Friday, July 15, 2022
Finalist #10 in the Book Review Contest
You Might Also Like
We Tried All the Jeans at Gap
Tuesday, March 11, 2025
Plus: What Kristen Kish can't live without. The Strategist Every product is independently selected by editors. If you buy something through our links, New York may earn an affiliate commission.
What Happened To NAEP Scores?
Tuesday, March 11, 2025
... ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
What A Day: Police state school
Monday, March 10, 2025
A student organizer at Columbia University was arrested by ICE. It's a scary sign for students and colleges for the next four years. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Can Anything Stop Bird Flu?
Monday, March 10, 2025
March 10, 2025 HEALTH Can Anything Stop Bird Flu? By Christopher Cox Illustration: David Macaulay In February 2024, dairy farmers in the northwest corner of the Texas Panhandle noticed that their herds
Going to the Mattresses
Monday, March 10, 2025
Investment Advice, Protest Arrest ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Rocket’s $1.75B deal to buy Redfin amps up competition with Zillow
Monday, March 10, 2025
GeekWire Awards: Vote for Next Tech Titan | Amperity names board chair ADVERTISEMENT GeekWire SPONSOR MESSAGE: A limited number of table sponsorships are available at the 2025 GeekWire Awards: Secure
🤑 Money laundering for all (who can afford it)
Monday, March 10, 2025
Scammers and tax evaders get big gifts from GOP initiatives on crypto, corporate transparency, and IRS enforcement. Forward this email to others so they can sign up 🔥 Today's Lever story: A bill
☕ Whiplash
Monday, March 10, 2025
Amid tariff uncertainty, advertisers are expecting a slowdown. March 10, 2025 View Online | Sign Up Marketing Brew Presented By StackAdapt It's Monday. The business of sports is booming! Join top
☕ Splitting hairs
Monday, March 10, 2025
Beauty brand loyalty online. March 10, 2025 View Online | Sign Up Retail Brew Presented By Bloomreach Let's start the week with some news for fans of plant milk. A new oat milk, Milkadamia Flat
Bank Beliefs
Monday, March 10, 2025
Writing of lasting value Bank Beliefs By Caroline Crampton • 10 Mar 2025 View in browser View in browser Two Americas, A Bank Branch, $50000 Cash Patrick McKenzie | Bits About Money | 5th March 2025