📝 Guest post: Getting ML data labeling right*
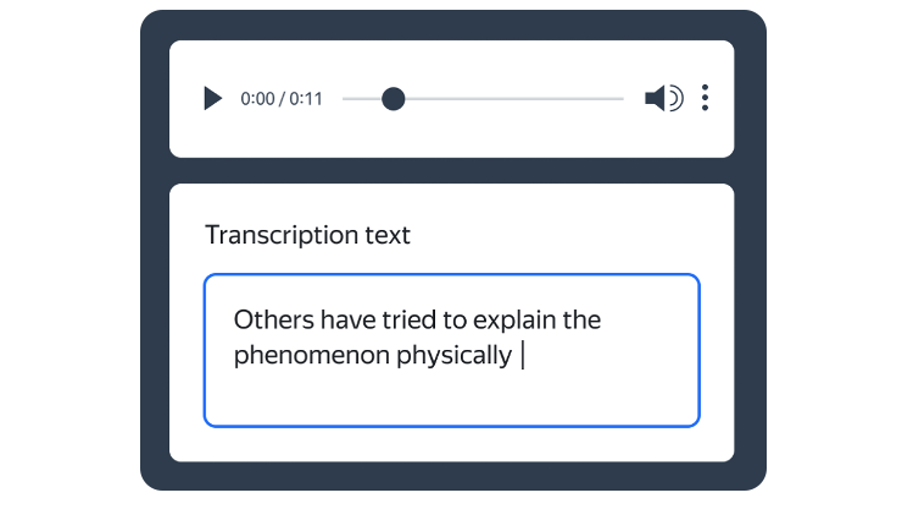
Was this email forwarded to you? Sign up here What’s the best way to gather and label your data? There’s no trivial answer as every project is unique. But you can get some ideas from a similar case to yours. In this article, Toloka’s team shares their data labeling experience, looking into three different case studies. IntroductionThe number of AI products is skyrocketing with each passing year. Just a few years ago, AI and ML were accessible mostly to the industry’s bigger players – little companies didn’t have the resources to build and release quality AI products. But that landscape has changed, and even small enterprises have entered the game. While building production-ready AI solutions is a long process, it starts with gathering and labeling the data used to train ML models. What’s the best way to make that happen? There’s no easy answer to that question since every project is unique. But this article will look at three different case studies we’ve worked on. 1. Audio transcriptionFor this project, we needed to transcribe large amounts of voice recordings to train an Automatic Speech Recognition (ASR) model. We divided the recordings into small audio clips and asked the Toloka crowd to transcribe what they heard. The interface was similar to what you can see below.
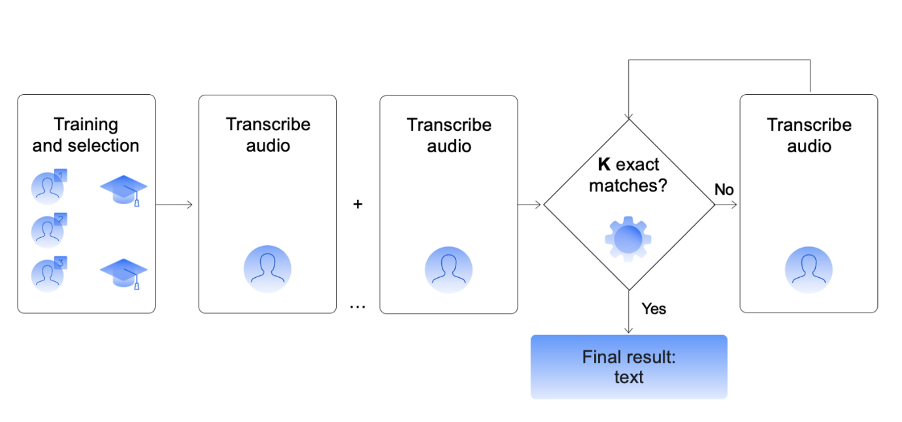
The transcriptions were easy to pause as needed. We also distributed the same audio clip to a large crowd to ensure quality, only accepting their work when there were a certain number of matches. The pipeline below visualizes that process.
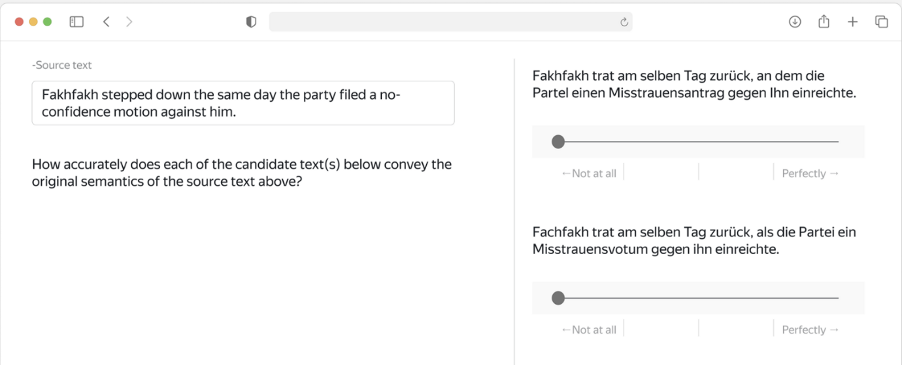
The annotators who took part in the project went through training as well. Almost no matter the project, we recommend including this step. The training can include tasks similar to the ones required for the project and offer a careful explanation when the annotators make mistakes. That teaches them what exactly they need to do. 2. Evaluating translationsAnother interesting project we worked on was evaluating translation systems for a major machine translation conference. Each annotator was given a source text and a couple of candidate translations. They were then asked how well each translation conveyed the semantics of the original text, the process shown in the interface below.
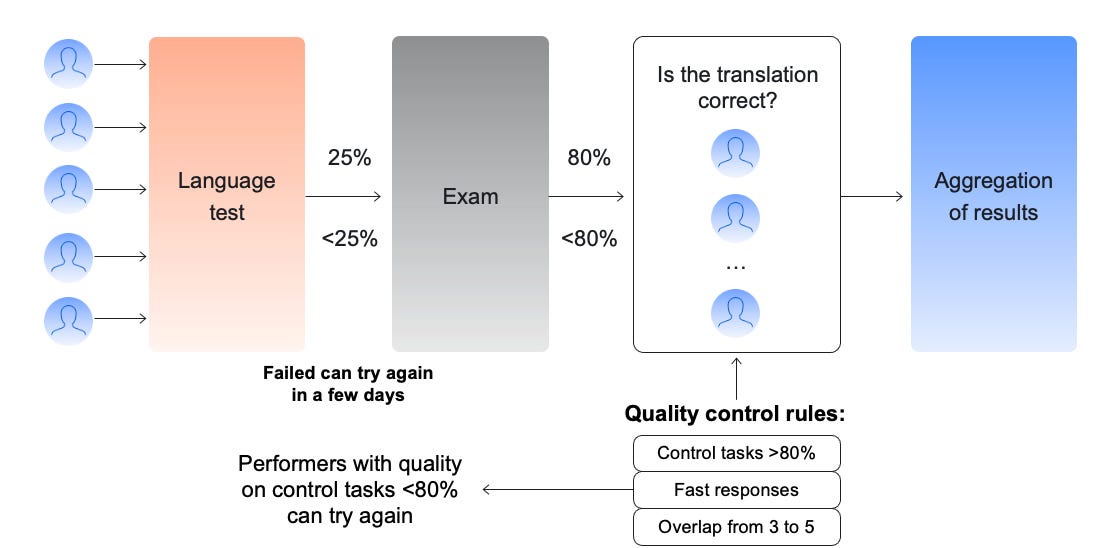
With this project, we were very careful about crowd selection, starting with a mandatory language test and exam.
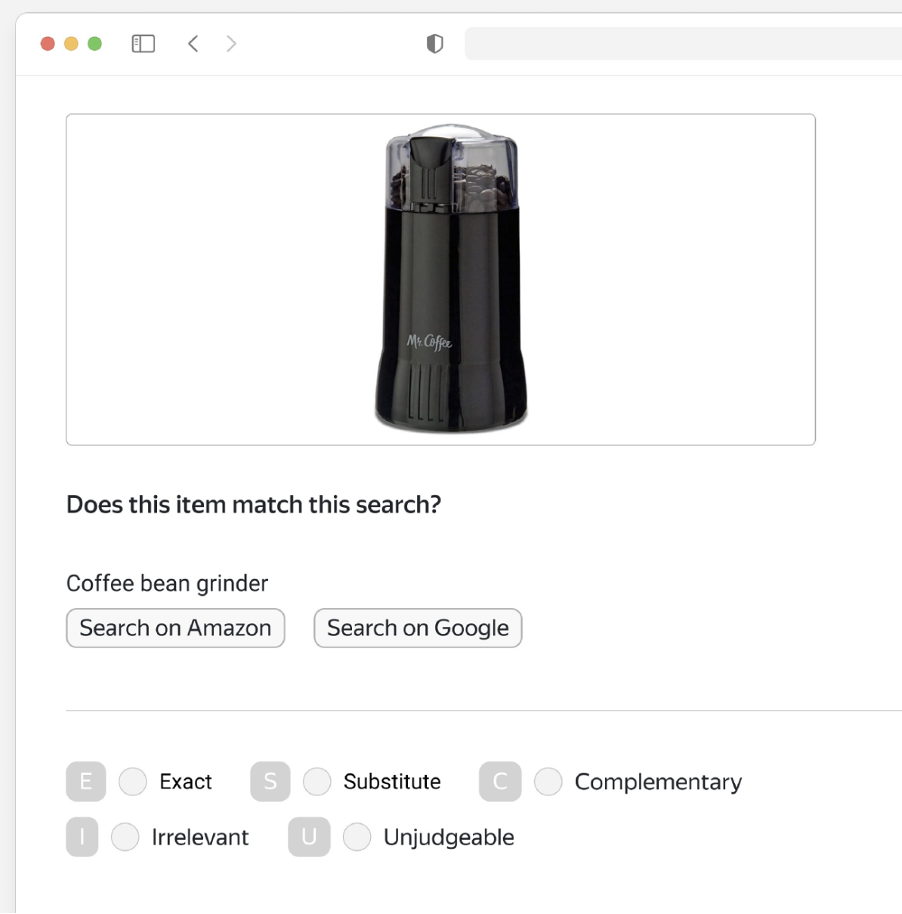
During the evaluation process, we constantly monitored participant performance using control tasks, which we knew the answer to. These tasks were mixed in with regular tasks so they couldn’t be detected. If annotator quality fell below 80%, they were required to pass the initial test again. As a result of this project, we have annotated more than one hundred language pairs, including some common ones but also covering more exotic cases such as Xhosa – Zulu or Bengali – Hindi. Those are especially challenging due to a limited number of annotators. 3. Search relevanceOne of the most popular use cases of Toloka is offline metrics evaluation of search relevance. Offline evaluation is needed since online feedback is not explicit, long-term, and hard to judge, for example, dwell-time & clicks. Offline metrics evaluation enables us to focus on separate search characteristics and receive explicit signals about search relevance. To do that, we show annotators a search query and a picture of a potentially matching item and ask them to rate relevance. The interface we use for this type of task is shown below.
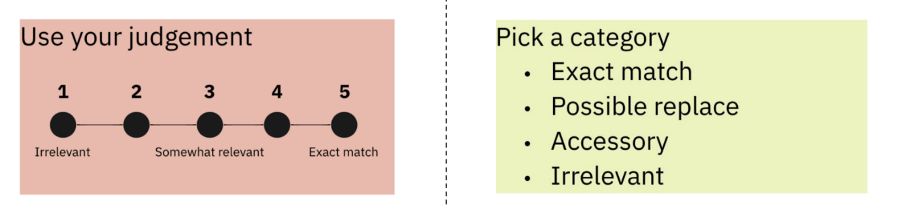
We add buttons to search on Google or Amazon. That helps when the query is a bit obscure or difficult to understand because the annotator can follow the links and see what products match the query in those search engines. Annotators often pick surprising answers. Intuitively, many clients go with a scale system like the one in the red box below when designing tasks.
With that said, our experiments have shown it is better to choose the categories seen in the green box: exact match, possible replace, accessory, and irrelevant. But that makes it incumbent on us to clearly define the categories in the instructions and during training. In this project, we had to provide detailed descriptions of what accessory and possible replace classes are. Additionally, each task was sent to multiple annotators whose quality was constantly checked using hidden control tasks. Our experience has shown that quality control checks are crucial components of each annotation project, and we always do it on projects we design. SummaryThis article has covered three case studies from our data labeling experience. We have shown you examples of data annotation projects for audio transcription, MT evaluation, and search engine evaluation. We hope they’ve given you a taste of how we approach this problem and an idea of how you can prepare data for your own ML project. But since every project is different, you’re welcome to join our slack channel if you have a challenge you’d like to discuss. *This post was written by Toloka’s team. We thank Toloka for their ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2022 Jesus Rodriguez, Ksenia Semenova
|


Older messages
👁 Edge#212: Inside the Masterful CLI Trainer, a low-code CV model development platform
Thursday, July 28, 2022
On Thursdays, we deep dive into one of the freshest research papers or technology frameworks that is worth your attention. Our goal is to keep you up to date with new AI developments and introduce the
🎙 Ran Romano/Qwak about bridging the gap between data science and ML engineering
Wednesday, July 27, 2022
It's so inspiring to learn from practitioners and thinkers. Getting to know the experience gained by researchers, engineers, and entrepreneurs doing real ML work is an excellent source of insight
🤷🏻 Edge#211: What to Test in ML Models
Tuesday, July 26, 2022
In this issue: we discuss what to test in ML models; we explain how Meta uses A/B testing to improve Facebook's newsfeed algorithm; we explore Meta's Ax, a framework for A/B testing in PyTorch.
🗄 A Model Compression Library You Need to Know About
Sunday, July 24, 2022
Weekly news digest curated by the industry insiders
📌 Event: Join us for this live webinar to learn how Tide reduced model deployment time by 50%!
Friday, July 22, 2022
A real use case you don't want to miss!
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your