📝 Guest post: "ML Data": The past, present and future*
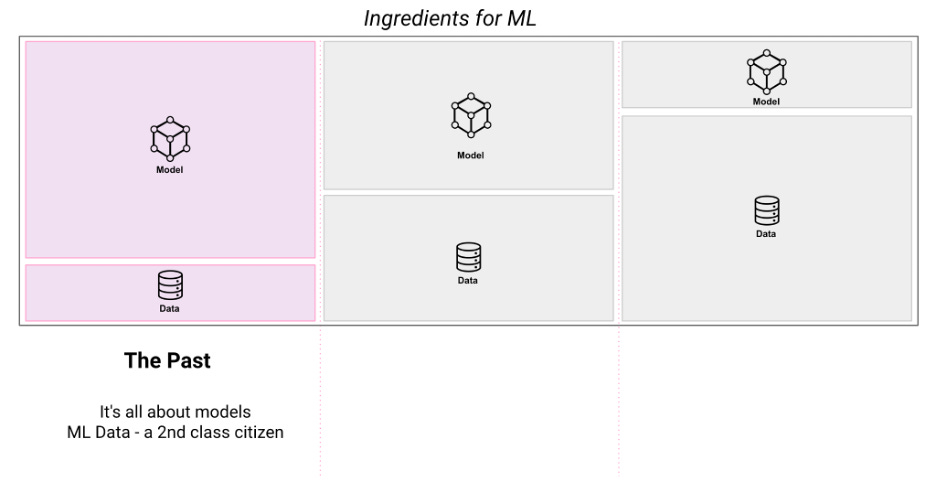
Was this email forwarded to you? Sign up here In this article, co-founder and CTO of Galileo Atindriyo Sanyal gives a fascinating overview of the ‘ML data intelligence’ evolution and shares a few insights on why the organizations that obsess on their ML data quality will quickly greatly outperform those that focus on the model alone. Over the past decade, I’ve had the privilege to have been part of teams building the foundational technology behind some of the biggest ML platforms – as an early engineer building the foundations of Siri, building and scaling the world’s first Feature Store, building data quality systems for one of the largest ML Platforms on the planet at Uber (learning: shine a light on your data; you will be shocked by how bad it is!), wrote a paper with the fine folks at the Stanford AI Lab to evangelize the concept of Embeddings Stores (unstructured data ML adoption is exploding!), and now building the first ML Data Intelligence platform at Galileo. Through these experiences, I’ve seen an evolution in how we think about data for ML. I wanted to share my thoughts on how the criticality of ML data has evolved and why I think organizations that obsess on their ML data quality will quickly greatly outperform those that focus on the model alone. Let’s dive into this, but like everything else, it’s easier when we first step back and peer into the past. The Past: Commoditization of storage and compute, and the rise of ML PlatformsBy the time the 2010s hit, data engineers had access to immense data and batch compute resources at their disposal – with Hadoop, MapReduce and eventually Spark – leading to the Big data revolution. During this time, analytics systems became the prime consumers of vast amounts of data as it became critical for organizations executing on data-driven insights. Large compute platforms evolved to have SQL-like interfaces as well as programmatic SDKs on top of the frameworks, which would allow a user to do complex transformations on gigabytes of data. At Apple, for example, we wrote dozens of batch analytics jobs that would run daily and collate reports on usage of Siri across millions of Apple devices around the globe and generate reports. An outcome of this was the Data Sprawl problem - where the proliferation of ad-hoc jobs without a layer of proper data management led to large amounts of duplication in compute, data redundancy and general disarray in how data processing was organized. The problem became rampant at scale, leading to data warehouses turning into data landfills.
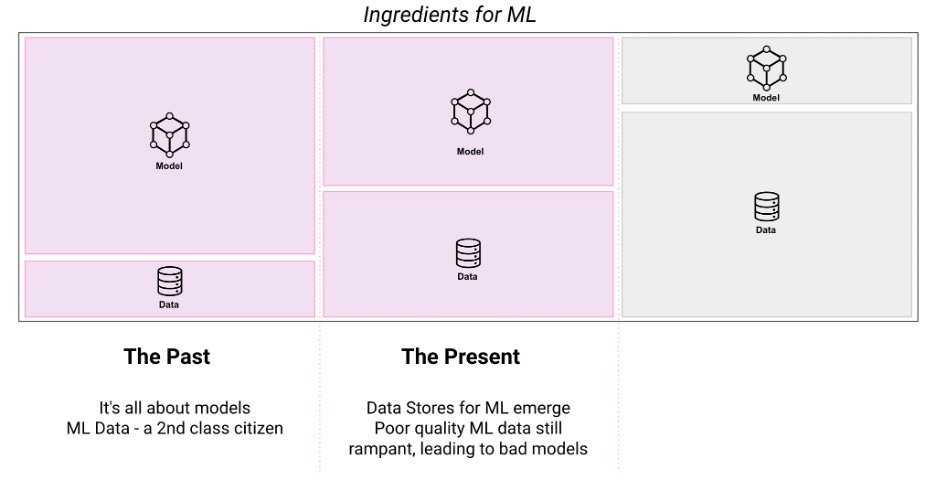
In recent years, similar problems manifested themselves in ML platforms where ad-hoc data generation jobs built from batch and streaming sources created a messy ML data ecosystem. Choosing the right, error-free, representative data for your ML task became equivalent to finding a needle in a haystack. Parallelly during this time, advancements were made in machine learning techniques, and frameworks like TensorFlow became popular, exposing easy-to-use SDKs for developers to build complex NeuralNets and tune hyperparameters easily. This advancement was further accentuated with PyTorch, which facilitated the low-code creation of deep learning models. Similar advancements were made in classical machine learning techniques. Standard Decision Tree based techniques were replaced by Gradient Boosted Trees, which significantly improved the efficacy of their older counterparts. Around this time, the world of ML collided with big data and the problems previously encountered in non-ML big data systems manifested themselves in ML systems. My team at Uber, for example, was one of the first to publicly evangelize potential solutions to this problem when we created and evangelized a large-scale ML Platform, Michelangelo, that served all data scientists at Uber to train and deploy models. The Present: “Data powers ML. How to tame the beast?” The rise of ‘ML data’ storesThe Data Sprawl issue in ML became such a big pain point that it led to the next phase of advancements in ML platforms, centered around managing the lifecycle of the data that models consumed across training, evaluation and inference, leading to the rise of ‘ML Data stores’. As ML platforms (e.g. C3, Sagemaker, DataRobot etc) grew into becoming one-stop shops for larger organizations to manage all their ML models, the simultaneous training and deployment jobs of multiple models combined with a general lack of management of the data these models consumed, led to massive data bottlenecks. This led to the need for robust ML data management solutions that could streamline the easy consumption of data across multiple models without duplicating the compute and storage, reducing data fan-out issues as well as operational costs. The solution to these key challenges came in the form of Feature Stores for structured and semi-structured data, as well as unstructured data (embeddings), which massively simplified the authoring and consumption of ML features across the different stages of the ML workflow.
The past few years have seen a proliferation of Feature Store technologies being a part of various popular ML Platforms (Google Cloud Vertex AI, Amazon Sagemaker, Databricks), but also a vast number of mid-sized firms focused on building such ML Data stores as stand-alone services. With the advent of Transformers and unstructured data machine learning taking off, we will see these ML data management and storage technologies expand to house pre-trained embeddings in one place—large organizations such as Google and Uber, have had teams managing re-usable embedding stores for a while. With unstructured ML data proliferating within businesses, these technologies are soon to be commoditized. The Future: “Lesser, high-quality data strongly preferred over more, poor quality data” – The rise of ‘ML data intelligence’To recap, three key advancements have chartered the MLOps revolution over the last few years – better management of ML data, the commoditization of off-the-shelf pre-trained models, and the advent of powerful ML frameworks, making model development a breeze. Despite these advancements, the quality of ML systems still suffers from 3 critical challenges:
The core of the aforementioned problems fundamentally rests in the fact that there is little attention paid to the quality and relevance of the ML data being used to train and assess these models, which has been a key learning after my many years of developing ML platforms. The criticality of observing what data a model is interacting with at different stages of its lifecycle is a major differentiating factor between productionizing high-quality models that can be trusted. A lack of this practice leads to ML being perceived as a blackbox, which in the long run can bring down the quality of downstream applications that consume their outputs.
At Uber, we built advanced observability tooling which bolstered thousands of ML and Feature pipelines running every day that:
This resulted in significant improvements across thousands of models running in Uber’s production environment. The saliency of downstream applications consuming model outputs improved, thereby driving up key business metrics across different product verticals. Today, the growing rate of adoption of AI in the rest of the industry seems to be pointing to the same trend we’ve seen at larger, more technologically advanced companies. The rapid adoption of ML platforms will lead to a significant increase in the ML footprint across more products. But the more the number of models being productionized, the larger the need for ensuring that models get trained and evaluated on high-quality data. And this will only gain more significance in the coming years. This is why the next challenge for ML practitioners to solve will primarily be centering around two processes:
For businesses that want to put artificial intelligence (AI) first, ML Data Intelligence is the means through which this may be accomplished. To learn more, reach out to me, Atindriyo Sanyal. I will be happy to discuss how we solve the challenges of ML data Intelligence with Galileo. *This post was written by Atindriyo Sanyal, the co-founder and CTO of Galileo. We thank Galileo for their support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2022 Jesus Rodriguez, Ksenia Semenova
|



Older messages
🗣🤖 Edge#218: Meta AI's BlenderBot 3, A 175B Parameter Model that can Chat About Every Topic and Organically Impr…
Thursday, August 18, 2022
The new release represents a major improvement compared to previous versions
🔂 Edge#217: ML Testing Series – Recap
Tuesday, August 16, 2022
Last week we finished our mini-series about ML testing, one of the most critical elements of the ML models' lifecycle. Here is a full recap for you to catch up with the topics we covered. As the
📙 Free book: Meet the Data Science Innovators
Monday, August 15, 2022
Learn from top data science leaders, who share their insights on their groundbreaking innovations, their careers, and the data science profession. Who's doing the most innovative things in data
😴 ❌ Don’t Sleep on JAX
Sunday, August 14, 2022
Weekly news digest curated by the industry insiders
📌 Event: Last chance to register for conference on scalable AI – Aug 23-24 in San Francisco!
Friday, August 12, 2022
The world's top minds in AI and distributed computing are coming to Ray Summit — August 23-24 in San Francisco. Join the global Ray community for two days of keynotes, training, and technical
You Might Also Like
How to know if your data has been exposed
Monday, November 25, 2024
How do you know if your personal data has been leaked? Imagine getting an instant notification if your SSN, credit card, or password has been exposed on the dark web — so you can take action
⚙️ Amazon and Anthropic
Monday, November 25, 2024
Plus: The hidden market of body-centric data
⚡ THN Recap: Top Cybersecurity Threats, Tools & Tips (Nov 18-24)
Monday, November 25, 2024
Don't miss the vital updates you need to stay secure. Read the full recap now. The Hacker News THN Recap: Top Cybersecurity Threats, Tools, and Practices (Nov 18 - Nov 24) We hear terms like “state
Researchers Uncover Malware Using BYOVD to Bypass Antivirus Protections
Monday, November 25, 2024
THN Daily Updates Newsletter cover Generative AI For Dummies ($18.00 Value) FREE for a Limited Time Generate a personal assistant with generative AI Download Now Sponsored LATEST NEWS Nov 25, 2024 THN
Post from Syncfusion Blogs on 11/25/2024
Monday, November 25, 2024
New blogs from Syncfusion Build World-Class Flutter Apps with Globalization and Localization By Lavanya Anaimuthu This blog explains the globalization and localization features supported in the
Is there more to your iPhone?
Monday, November 25, 2024
Have you ever wondered if there's more to your iPhone than meets the eye? Maybe you've been using it for years, but certain powerful features and settings remain hidden. That's why we'
🎉 Black Friday Early Access: 50% OFF
Monday, November 25, 2024
Black Friday discount is now live! Do you want to master Clean Architecture? Only this week, access the 50% Black Friday discount. Here's what's inside: 7+ hours of lessons .NET Aspire coming
Open Pull Request #59
Monday, November 25, 2024
LightRAG, anything-llm, llm, transformers.js and an Intro to monads for software devs ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Last chance to register: SecOps made smarter
Monday, November 25, 2024
Don't miss this opportunity to learn how gen AI can transform your security workflowsㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ elastic | Search. Observe. Protect
SRE Weekly Issue #452
Monday, November 25, 2024
View on sreweekly.com A message from our sponsor, FireHydrant: Practice Makes Prepared: Why Every Minor System Hiccup Is Your Team's Secret Training Ground. https://firehydrant.com/blog/the-hidden-