📝 Guest post: 4 Types of ML Data Errors You Can Fix Right Now*
Was this email forwarded to you? Sign up here In this article, Galileo founding engineer Nikita Demir discusses common data errors that NLP teams run into and how Galileo helps fix these errors in minutes with a few lines of code. A very helpful read! IntroductionOver the past year, we’ve seen an explosion of interest in improving ML data quality. While parts of the MLOps ecosystem have matured, ML data quality has been dramatically underserved. In this article, we’ll walk you through four of the most prominent types of data errors and show you techniques for fixing them. In the end, we’ll point out how your errors can be found and fixed in minutes with a tool like Galileo!
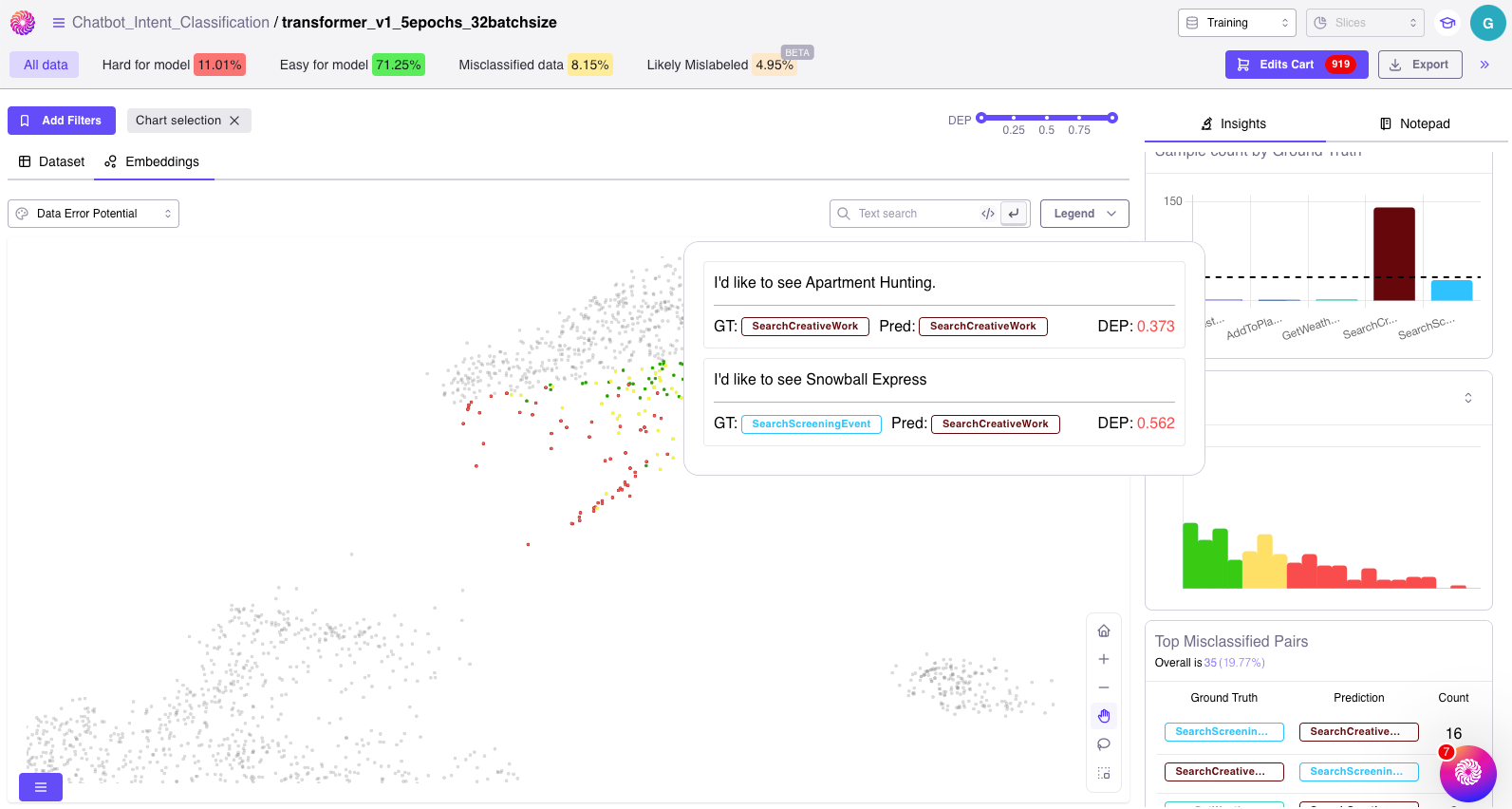
❗️ ML Data Error #1: MislabelsThe correctness of your ground truth labels can vary depending on how they were labeled. Most public datasets, including canonical benchmark ones, have been shown to have mislabeled samples. Although deep learning models can be robust to some random noise, labelers often make errors between specifically confusing classes: “cheetah” vs “leopard”, “SearchCreativeWork” and “SearchScreeningEvent”, “talk.religion.misc” and “soc.religion.christian”. Repeated errors are likely to degrade the model’s performance on confusing classes. We’ve seen the industry mitigate these errors in a few painstaking ways:
❗️ML Data Error #2: Class OverlapAnother common data error we see, especially for problems with many ground truth classes, is an overlap in the class definitions. Your dataset might have multiple classes that mean the same thing like “billing.refund” and “account.refund”, multiple classes that apply to the same input like “appointment.cancel” and “appointment.reschedule” for the input of “I would like to cancel and reschedule my appointment”, or unclear definitions for specific data cohorts. Finding the problematic classes when there are 20+ classes in your dataset can be challenging and tedious, but that is also the scenario where the class overlap is most likely to occur. Try:
Ultimately, you will have to educate your labelers or change the classes by either merging them or creating new ones. ❗️ML Data Error #3: ImbalanceBy itself having an imbalanced dataset might not be a problem, but often model performance can correlate with that imbalance. ML practitioners tend to be trained to look at class imbalance but often don’t consider imbalances in the inputs themselves. For example, if a training dataset has hundred subtle variants of “I need to repair my Jeep” but only one example of “I need to repair my Honda,” a model might not have enough signal to associate a Honda with a car and not a microwave, which would matter if your two classes are “repair.car” and “repair.microwave”. Similar imbalances in the test dataset can lead to misleadingly inflated accuracy numbers. Detecting class or any other metadata column’s imbalance is pretty easy to do and should be a standard part of a practitioner’s workflow. However, detecting imbalances in the patterns of your data is generally pretty hard. Some things to try are:
Once you detect imbalance, it can be reduced by downsampling frequent samples and increasing the number of less frequent samples through data augmentation or using embeddings to select similar samples from an unlabeled dataset and labeling. ❗️ML Data Error #4: DriftA model deployed in production only knows to make predictions based on what you trained it on. As the real-world data “drifts”, the model’s predictions veer into uncharted territory. Covid, for example, broke facial recognition models with the usage of masks. New words enter our lexicon daily, and old terms can change their meanings drastically. This is especially problematic for datasets that are hand-curated. Drift can be detected by looking for changes in the model’s predictions or the composition of production data. A mature ML workflow would send some of the drifted data to labelers and use the results in a retraining job. ⚡️ Better Data in MinutesData-centric techniques are not well documented or taught in the industry. Finding data errors is a very time-consuming process. It can feel like finding a needle in a haystack. Except, you have a ton of needles in a really large haystack of tens or hundreds of thousands of data samples. We’ve built Galileo to take that pain away. We want to empower you to find and fix data errors in minutes instead of hours without worrying about the technical details. With Galileo, you can find likely mislabeled samples, samples with class overlap, drift in your real-world data, or you can use it to explore your data’s patterns through their embeddings! Try it out yourself by signing up for free here. We would love to discuss what you find in our Slack community. Here’s to building better models, faster, with better data! Team Galileo (PS: we are hiring!) *This post was written by Nikita Demor, a founding engineer at Galileo. We thank Galileo for their support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2022 Jesus Rodriguez, Ksenia Semenova
|


Older messages
❇️ NVIDIA Continues Pushing AI’s Boundaries
Sunday, September 25, 2022
Weekly news digest curated by the industry insiders
👾 Edge#228: How Amazon is Improving BERT-Based Models Used in Alexa
Thursday, September 22, 2022
Recently Amazon Research published three papers about BERT-based models
📝 Guest post: Unlock the Power of BLOOM With the Broadest Range of GPUs Served On-Demand*
Wednesday, September 21, 2022
In this guest post, CoreWeave introduces BLOOM deploy on their platform and guides you through their arsenal of GPUs to ensure you find the compute that delivers the best possible performance-adjusted
📃➡️🖼 Edge#227: Autoregressive Text-to-Image Models
Tuesday, September 20, 2022
+Google's Parti; +MS COCO
🐦 Follow us on Twitter
Monday, September 19, 2022
Check how helpful it might be for you
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your