📝 Guest Post: Using LLMs from Hugging Face? Fix your model failure points 10x faster with Galileo Data Intelligen…
Was this email forwarded to you? Sign up here
Large Language Models (LLMs) are powerful assets for data scientists to leverage within their applications – Hugging Face is a leading repository for LLMs today. However, while using LLMs, the practical reality is that the quality of the training data governs model performance, and data scientists often spend 80% of their time in Excel sheets and python scripts, trying to find the data that pulls the model performance down, whether while training a model, or for models in production. In this guest post, co-founder and CEO of Galileo Vikram Chatterji explains how to:
Want to try Galileo for yourself? Feel free to reach out here to get a personalized demo from a member of the Galileo Data Science team.
🚀Few Lines of Code: Using Galileo While Training a Hugging Face ModelWe’ll be using the popular CoNLLpp dataset. Using Galileo, we will quickly be able to find a host of data errors:
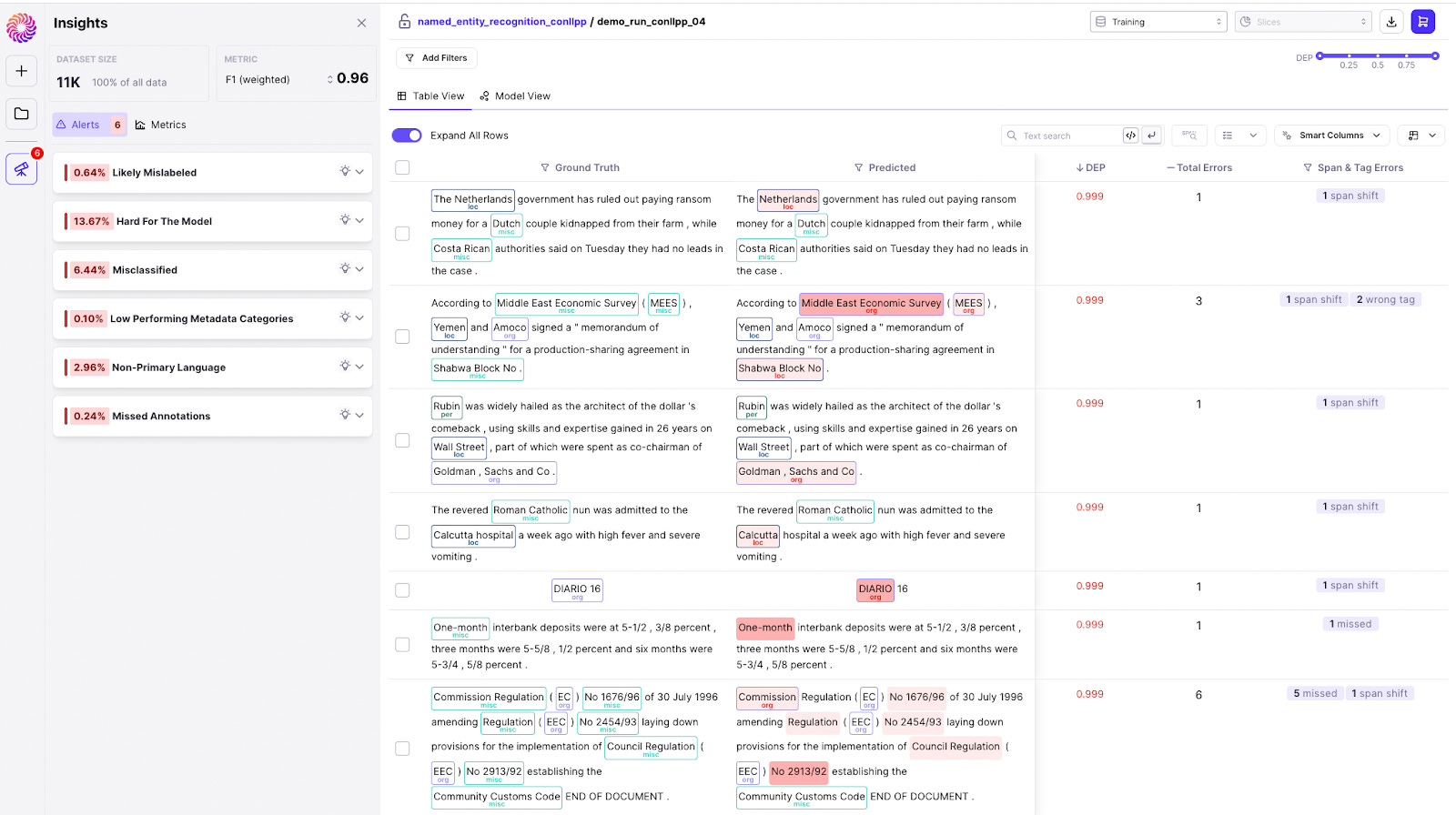
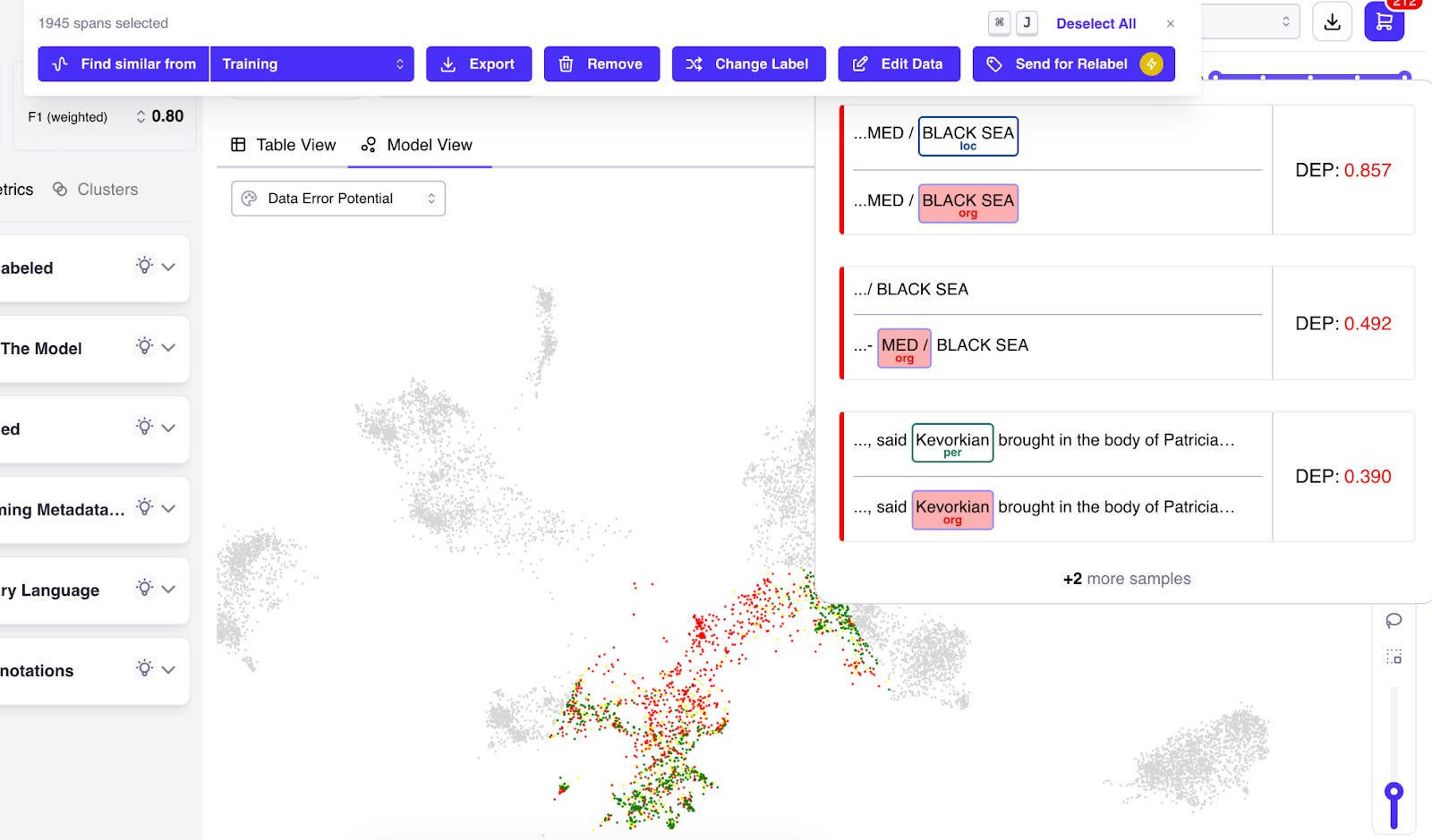
STEP 1: Install `dataquality` and initialize Galileo For this tutorial, you need at least Python 3.7. As a development environment, you can use Google Colaboratory. The first step is to install dataquality (Galileo's python client) and datasets, evaluate, and transformers (HuggingFace). STEP 2: Load, Tokenize and Log the Hugging Face 🤗Dataset The next step is to load your dataset. For this demo, we will use the popular `conllpp` dataset, which follows the same NER data format as any other HuggingFace dataset. Galileo provides Hugging Face integrations to allow tokenization and label alignment. Behind the scenes, it logs your input data automatically. STEP 3: Training the NER Model Now we're ready to train our HuggingFace model for a Named Entity Recognition task. You simply call trainer.train() and you'd be set. But we’re here to drill down into this dataset and find data errors or samples the model struggles with. To achieve that, we wrap the trainer in Galileo’s “watch” function and call dq.finish() at the end to publish the results to Galileo. It’s THAT simple! When the model finishes training, you’ll see a link to the Galileo Console. ⚠️⚠️Find and fix data errors instantly: Data-centric model inspection with GalileoWithin a glance, Galileo points out the data that is pulling your model performance down. The Galileo console is designed to allow you to perform deep exploration of your data while giving you alerts out of the box to act as jumping boards to find problematic pockets of data. On the right, you can view your dataset in table form, or in the embedding space. DATA ERROR 1: Regions of high Data Error Potential (DEP) – a high precision ML data quality metric The dataset is sorted by the Data Error Potential score of the sample - a metric built by Galileo to provide a holistic data quality score for each sample to identify samples in the dataset contributing to low or high model performance.
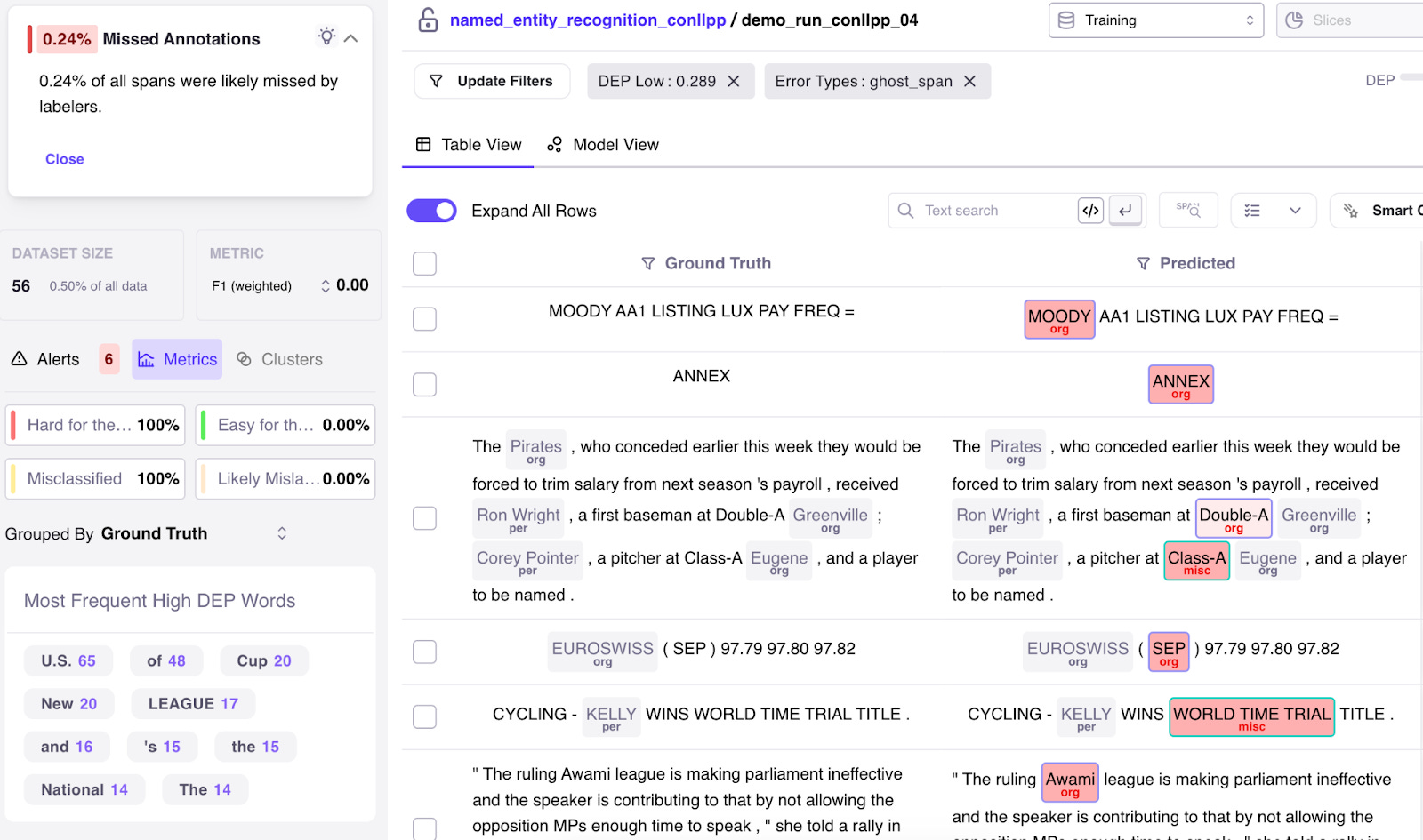
DATA ERROR 2: Missed Annotations Conllpp, despite being a massively peer-reviewed dataset, still has many missing annotations. Galileo surfaces these via the “Missed Annotations” alert. Clicking on it allows you to inspect further and in one-click add the annotations in-tool or send to your Labeling tool.
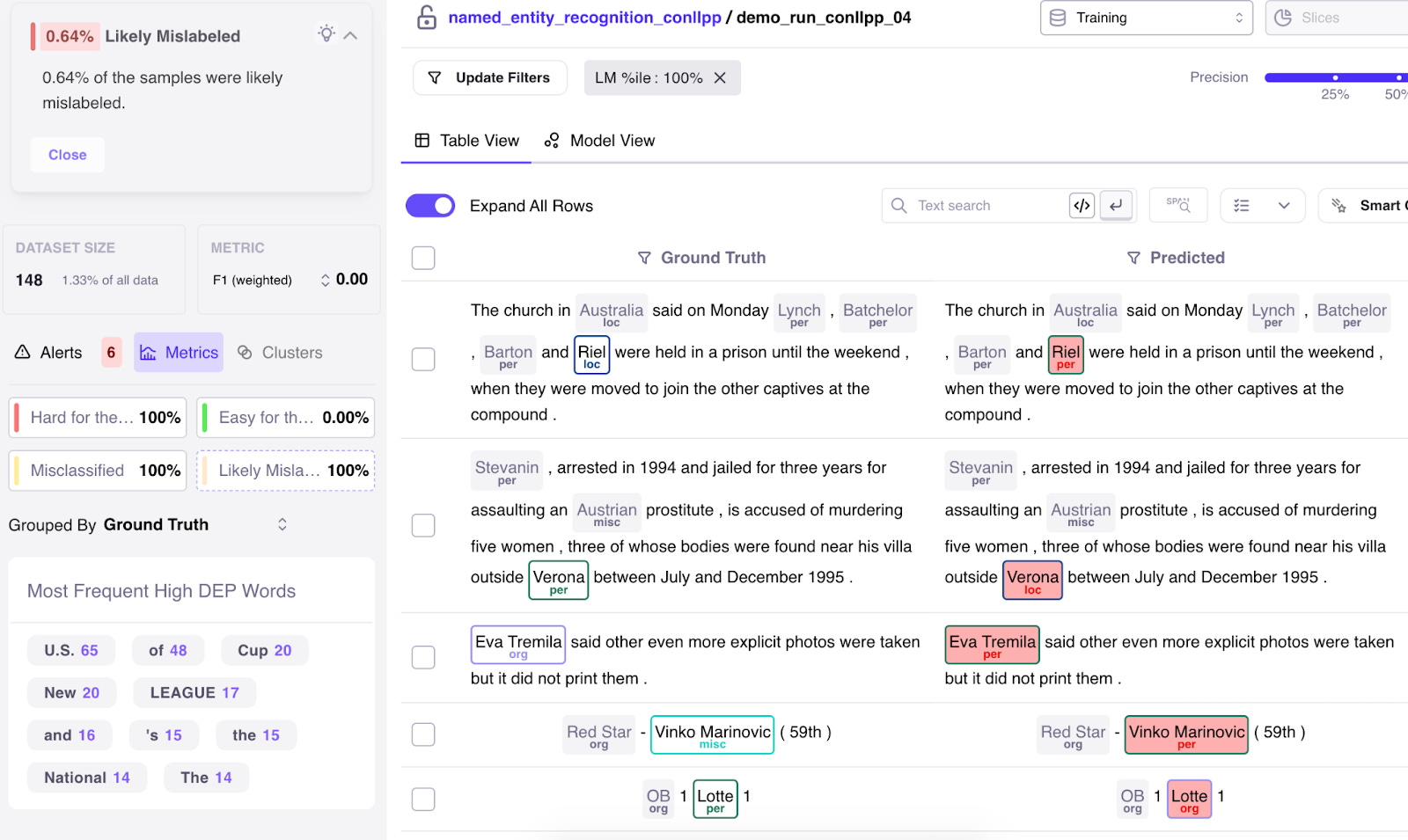
DATA ERROR 3: Errors in Labels Often, human labelers add the incorrect ground truth. Again, despite Conllpp being a corrected dataset, and there only being 4 classes (Location, Person, Organization, Misc), there are still a number of mislabels. Using Galileo’s “Likely Mislabeled” alert card, Galileo exposes the mislabeled data with high precision. Again, with one click, we can fix these samples by re-labeling within Galileo, or exporting a labeling tool through Galileo’s integrations.
ConclusionWe covered how to fine-tune a model for NER tasks using the powerful HuggingFace library and then use Galileo to inspect the quality of the model and dataset. This is only a fraction of what you can achieve using Galileo (more documentation here). Feel free to reach out here to get a personalized demo from a member of the Galileo data science team. Hope this proved useful, and happy building! *This post was written by Vikram Chatterji, the co-founder and CEO of Galileo. We thank Galileo for their support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
Read TheSequence in the app Listen to posts, join subscriber chats, and never miss an update from Ksenia Se.
|



Older messages
Inside Alpaca: The Language Model from Stanford University that can Follow Instructions and Match GPT-3.5
Thursday, April 6, 2023
The model is based on Meta AI's LLaMA and remains significatively smaller than GPT-3.5.
🎙 ML platform podcast: Season 2 of MLOps Live from neptune.ai*
Wednesday, April 5, 2023
*This post was written by neptune.ai's team. We thank neptune.ai for their ongoing support of TheSequence. We ran MLOps live podcast for over a year. 29 incredible Q&A sessions with people
Edge 279: Cross-Silo Federating Learning
Tuesday, April 4, 2023
Cross-silo federated learning(FL), Amazon's research on personalized FL and IBM's FL framework.
📝 Guest Post: An introduction to Similarity Search*
Monday, April 3, 2023
In this guest post, Frank Liu, Director of Operations & ML Architect @ Zilliz, conducts a quick tour of Similarity Search, comparing embeddings and vector search strategies. An introduction to
The Controversial AI Moratorium Letter
Sunday, April 2, 2023
Sundays, The Sequence Scope brings a summary of the most important research papers, technology releases and VC funding deals in the artificial intelligence space.
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your