📝 Guest Post: How to build a responsible code LLM with crowdsourcing*
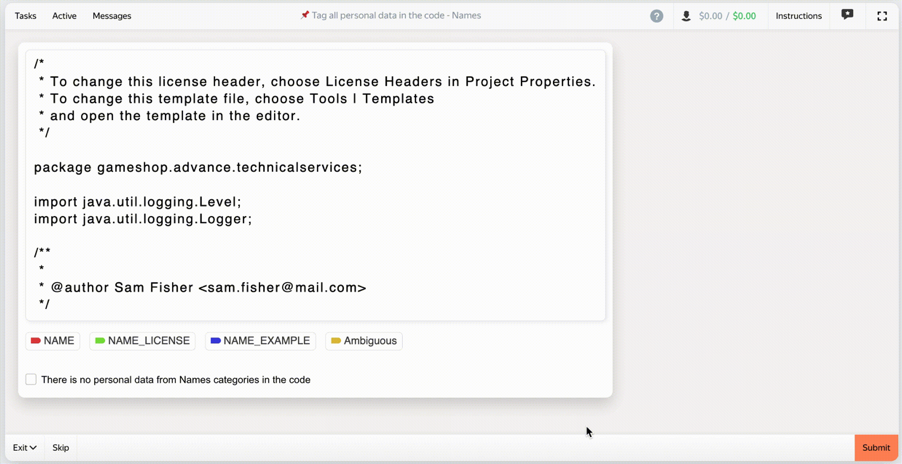
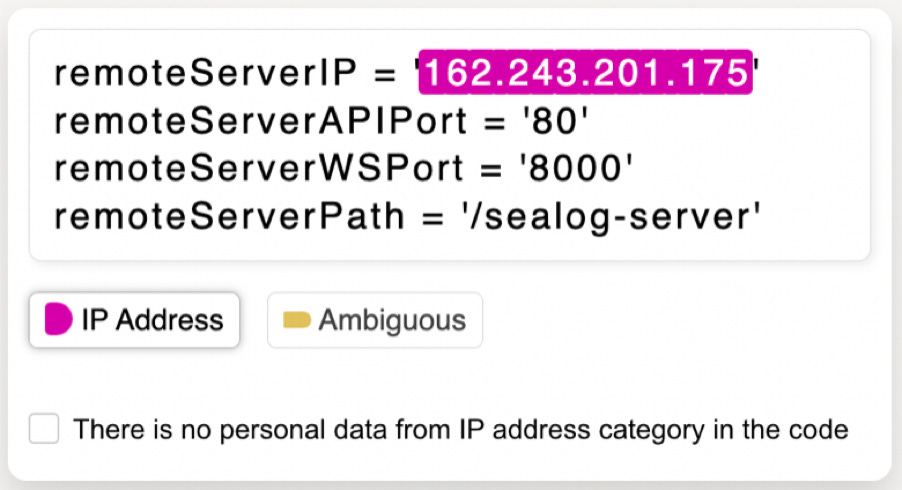
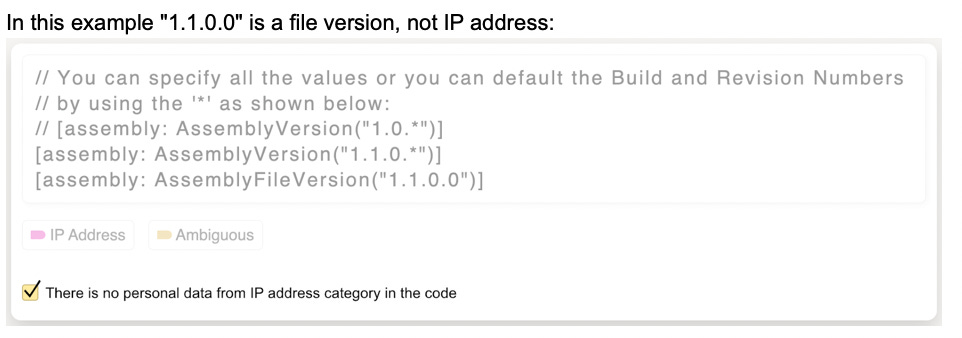
Was this email forwarded to you? Sign up here In this post Toloka showcases Human-in-the-Loop using StarCoder, a code LLM, as an example. They address PII risks by training a PII reduction model through crowdsourcing, employing strategies like task decomposition, clear instructions, and quality control. This successful implementation demonstrates how responsible AI and high-performing models can align. Responsible AI starts with a responsible approach to dataThe promise of Large Language Models (LLMs) is that they will help us with a variety of different tasks. However, before your LLM can solve these problems in a few-shot or even zero-shot manner, models must be exposed to extremely large amounts of data. These datasets are usually scraped from the internet. There is a problem with the internet, though—it’s messy. If you use scraped data, the model might pick up some private information, amplify existing biases, and, consequently, create more harm than good. Naturally, model developers implement numerous strategies and safeguards to detect and discard inappropriate prompts or model output at inference time, but models can still be manipulated into generating undesirable content. The risks of harmful results do not align with the principles of Responsible AI. If you want to build a responsible AI solution, you need to be careful with data handling practices. This includes adhering to copyright laws, complying with the laws of the country of use, and being fully transparent about the data collection and model training processes. All of these aspects are nearly impossible to cover without any human curation, and this is where Human-in-the-Loop comes in. We’re going to show how Human-in-the-Loop can be put to effective use in building responsible AI tools, using the example of StarCoder, a code LLM. By creating this open-source code LLM, the BigCode community, supported by Hugging Face and ServiceNow, has proven that high-performing AI solutions can be a part of responsible AI. StarCoder’s PII challengesStarCoder is an open-access alternative to the model which powers Github Copilot. The main goal of the BigCode community was to develop a code LLM that follows responsible AI guidelines, particularly those related to training data. StarCoderBase is trained on The Stack Dataset — a 6.4 TB dataset of permissively licensed source code in 384 programming languages. The final product, StarCoder, is the StarCoderBase model fine-tuned on the data sourced from the same dataset. To respect code owners’ rights, the StarCoder developers introduced a tool called “Am I in The Stack” which allows developers to opt out if desired. Even though the data usage was legally permissible, there were risks related to Personally Identifiable Information (PII) contained in the training data. The presence of personal data poses an ethical concern, as the final model could uncontrollably output personal information during inference. To mitigate this risk, prior to using The Stack dataset for StarCoder, the Big Code community members trained a PII reduction model and applied it to the entire dataset. Building a PII reduction modelIn the context of ethically sensitive tasks such as PII detection, human involvement is crucial. Looking through 6.4 terabytes of data manually is impossible. A working method to solve this dilemma is to use machine learning models and Human-in-the-Loop in a PII detection pipeline. When working with natural language processing (NLP) and text data— which includes code — developers are no longer training all their models from scratch, since downstreaming (fine-tuning, or prompting for extremely large models) has proven to be quite effective for training language models to perform specific tasks. In line with this approach, the Big Code community developers have trained the BERT-like encoder-only Star Encoder model and fine-tuned it to perform a Named Entity Recognition task. To achieve good recognition quality, engineers needed a high-quality labeled dataset of code snippets with various kinds of PII, including potential edge cases. A dataset for fine-tuning needs to be large — the plan was to use approximately 12,000 items — and diverse, in this case in types of PII represented. Given the cost and time associated with gathering such a dataset with a team of software engineers, the Big Code community decided to use crowdsourcing for labeling, and asked Toloka for help. Secrets to success for crowdsourcing and PII detectionA commonly held belief is that tasks requiring domain knowledge, like labeling programming code, can only be done by a specifically gathered group of domain experts. But experts are often difficult to find, hard to scale, and expensive to employ. This misguided belief often slows down the development of high-quality responsible AI tools, which are primarily data-driven. Over the past 10+ years, Toloka has tackled complex data labeling and data generation tasks that require deep domain expertise, proving that tasks of this nature can be solved efficiently with crowdsourcing. Toloka’s diverse crowd naturally includes experts in multiple domains. When we apply advanced crowdsourcing techniques, even the part of the crowd without domain experience can effectively contribute to labeling tasks. We applied our experience to the task of PII detection for the Big Code project and we’ll share our strategies in the following sections. Decomposition is keyWhen setting up a project to be labeled with crowdsourcing, the key strategy is to break down the task into easier subtasks. This is a skill that becomes second nature as you handle crowdsourcing projects. Instead of giving the Toloka crowd (also known as Tolokers) an assignment to label every type of PII in code, we grouped PII into 7 categories and set up a separate labeling project for each. These are the types of PII:
This approach made the task easier to handle for better quality. Putting all the categories in one project would create cognitive overload and lead to poor labeling quality. Start with the basics and gradually add complexityWe created a quiz for Tolokers that guided them through each category of PII, from easiest to hardest. They were assigned a skill for each category that they mastered in the quiz, and they had an opportunity to opt out if they hit a point where they felt overwhelmed. We used a similar system for tasks in production. Out of 2896 Tolokers interested in PII labeling, 1364 of them mastered all 7 categories. Names -> Emails -> Usernames -> IP Addressess -> Passwords -> API/SSH Keys -> IDs
Maintain consistency and make tasks manageableWe kept the tasks consistent and easy to understand. Each task included exactly 50 lines of code, and each project had no more than 4 categories to label. A good rule of thumb in crowdsourcing is that if a task takes more than 2 minutes, keep decomposing it. The user interface mattersIt’s essential to make labeling tools intuitive and easy to use. For instance, it helps to use contrasting colors to highlight categories. It’s also a good practice to add an option for users to give feedback that something is wrong with the input data, like an “Ambiguous” class in this project.
We try to include all of the best practices of crowdsourcing interface development in Toloka’s Template Builder. Give clear instructions with examples and counter examplesPeople are all-purpose few-shot learners. Their advantage lies in the ability to detect a similar item in different distorted forms and to be able to give human-readable feedback on levels of this distortion.
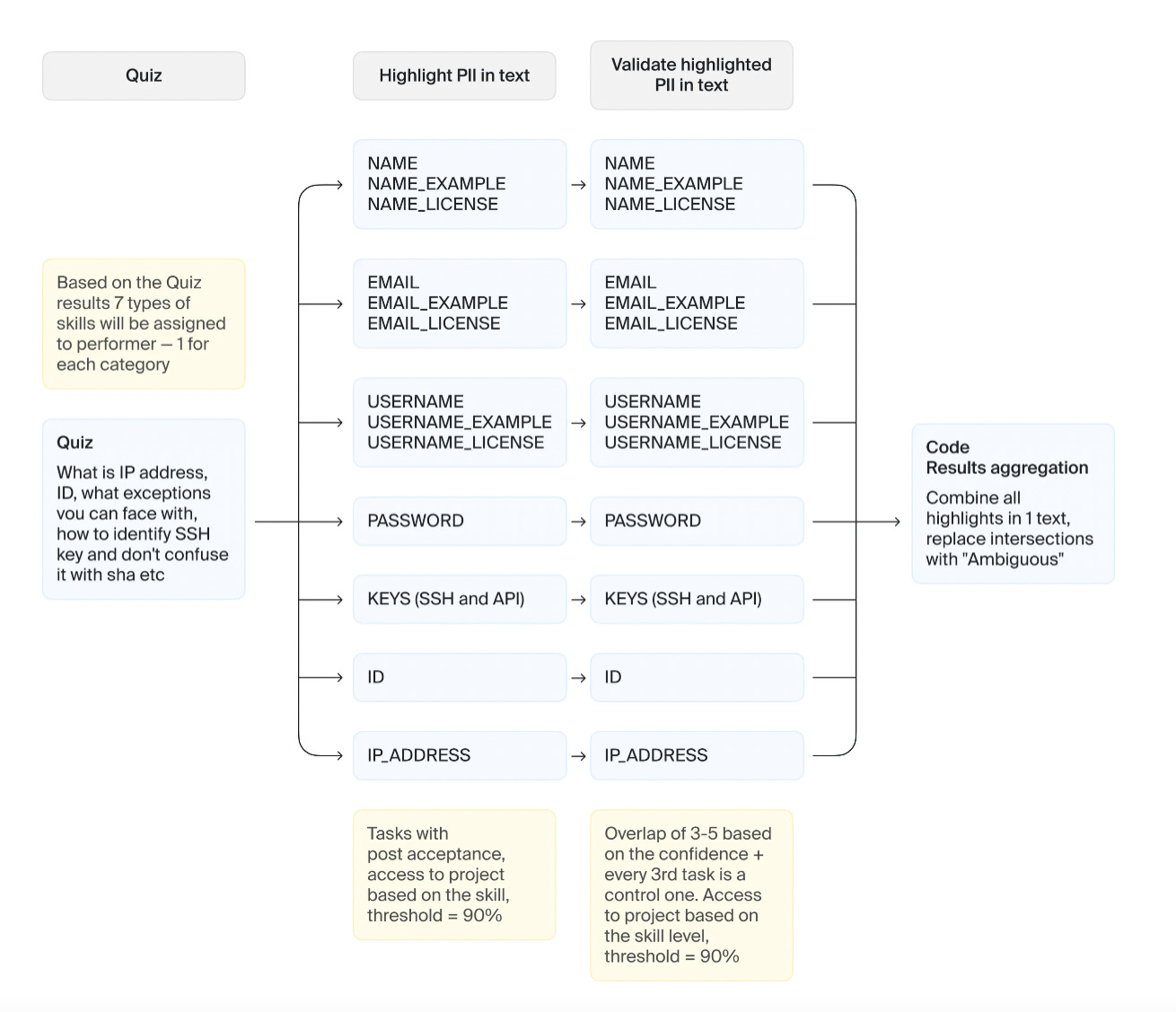
Set up quality controlChoosing a small group of experts to do the labeling might seem like the only way to get good quality. But that’s not always the case. Crowdsourcing allows us to use advanced techniques to measure labeling skills and maintain quality at the desired level. For the PII pipeline, we used validation projects, overlap, and hidden control tasks to manage labeling quality. Use validation projectsFor each category, we designed a chain of projects:
Validation projects are needed when the correct answers are hard to check automatically. A validation project should reflect target metrics. In the case of PII detection, the metrics were precision and recall: “Was every piece of PII found in the code? Was each selected piece labeled correctly?” Use overlapTwo heads are better than one. Overlap means that the same task is completed by two or more people and the results are aggregated. In validation projects, we used majority vote to determine the correct answer and weed out low-quality results. Use control tasksControl tasks are tasks that include correct answers and can be checked automatically, but they look like regular tasks to the crowd. We used these tasks to dynamically update Toloker skill levels for each category of tasks during labeling. We filtered Tolokers by skill and only allowed them to access the types of tasks they have a high skill level for. We also awarded bonuses for good quality.
Responsibility to the crowdTo follow the principles of Responsible AI, crowd projects should be managed responsibly.
ResultsFinal Pipeline
PII reduction modelOur rapid setup and labeling — completed in two weeks and four days, respectively — yielded impressive results. However, given more time to improve labeling instructions, we’re confident of even greater accuracy, potentially reaching flawless ID labeling. The PII reduction model fine-tuned on the labeled dataset scored high F1 scores for names, emails, and IP addresses (over 90%) and passwords (73.39%). Lower performance on keys and usernames (F1 scores of 56.66% and 59.39%) was due to a limited number of these PII types in the dataset, with only 308 instances available. IDs were excluded from the training dataset. To sum upThe StarCoder model surpassed every open Code LLM that supports multiple programming languages and competes with, if not outperforms, OpenAI’s code-cushman-001. What’s most important to us is that it follows the guidelines of Responsible AI. Achieving these results without Human-in-the-Loop would be challenging. Crowdsourcing is an effective approach, delivering quality labeling in a limited time frame across a range of complexity. *This post was written by the Toloka team. We thank Toloka for their ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|



Older messages
GPT-Microsoft
Sunday, May 28, 2023
Sundays, The Sequence Scope brings a summary of the most important research papers, technology releases and VC funding deals in the artificial intelligence space.
Announcing Turing Post
Saturday, May 27, 2023
When we launched TheSequence back in 2020, AI and machine learning were not as widely discussed or covered. Our goal from the start was to make AI knowledge accessible in bite-sized pieces, helping
📢 Event: ML practitioners from Affirm, Block, Remitly, Tide & more share their learnings from building risk & fra…
Friday, May 26, 2023
Want to connect with the ML engineering community and learn best practices from ML practitioners on how to build risk and fraud detection systems? Then join us on May 30 for apply(risk), a free half-
Edge 294: Inside StarCoder: Hugging Face's New LLM that Can Generate Code in Over 80 Programming Languages
Thursday, May 25, 2023
StarCoder was created by Hugging Face and ServiceNow as part of the BigCode project.
The Sequence Chat: Hugging Face's Leandro von Werra on StarCoder and Code Generating LLMs
Wednesday, May 24, 2023
StarCoder is one of the most ambitious code generation foundation models released in recent times.
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your