Data Science Weekly - Data Science Weekly - Issue 498
Issue #498 |

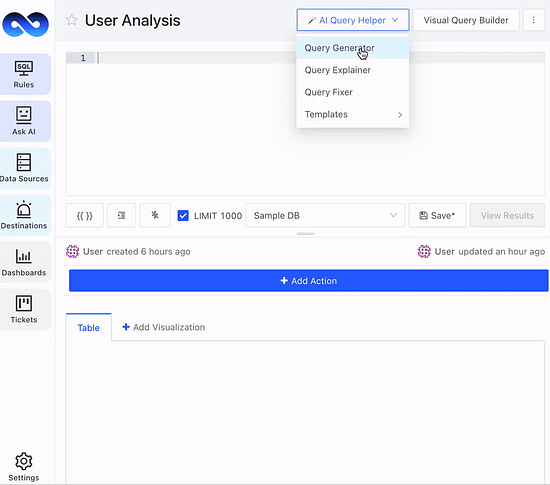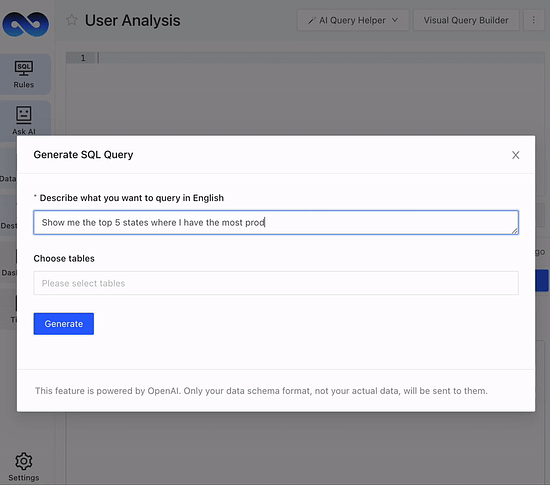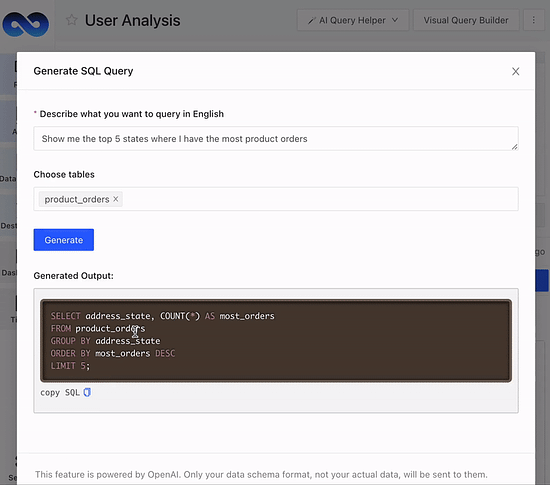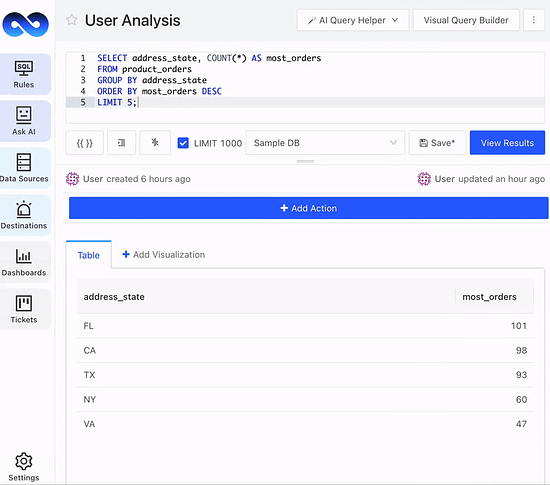 |
Spending too much time fiddling with SQL?
LogicLoop AI SQL Copilot can auto suggest, generate, fix and optimize SQL queries on your data schema in seconds. Whether you want to pull ad-hoc data, fix a data bug or reduce query runtime costs, do it 10x faster. Also embeddable as an API, so your customers can ask data questions in natural language.
Save bandwidth and budget by trying LogicLoop AI SQL Copilot for free today. Sign up here.
PS: Need inspiration? Check out 100+ SQL templates. Have feedback or a feature request? Chat with us.
Want to sponsor the newsletter? Email us for details --> team@datascienceweekly.org
Data Science Articles & Videos
Leadership needs us to do generative AI. What do we do?
The idea for the talk came from many conversations I’ve had recently with friends who need to figure out their generative AI strategy, but aren’t sure what exactly to do…This talk is a simple framework to explore what to do with generative AI. Many ideas are still being fleshed out. I hope to convert this into a proper post when I have more time. In the meantime, I’d love to hear from your experience through this process…
What are embeddings?
Ok, so LLMs are a Thing. How do they work? Embeddings. WTF are embeddings? I spent a year doing a deep dive. But when I was researching, I couldn't find anything that explained them in business, engineering, AND math contexts. So I wrote a thing. 🚀…
Privacy and Security in Data Science and Machine Learning [June 19]
Katharine Jarmul is a Principal Data Scientist at Thoughtworks Germany focusing on privacy, ethics, and security for data science workflows…In this live-streamed recording of Vanishing Gradients, Katharine joins your host Hugo Bowne-Anderson, to talk about all things privacy and security in data science and machine learning…What is the Leetcode equivalent for Data Engineering?
Actively interviewing so I need some prep material for Data wrangling questions if there is a single source out there.I'm looking for a source around questions like:
- Given a source data (JSON, CSV), derive insights to answer questions
- Clean up a given dataset to answer questions etc.
- Python dictionary / Json API response manipulation.
Thank you…
Do LLMs eliminate the need for programming languages?
Given new Large Language Model (LLM) powered developer tools like Copilot and Ghostwriter, many developers are wondering about the future of programming – do programming languages still matter when AI writes the code?…This is a great question! It cuts to the heart of developer workflows, allows us to reflect on the core purpose of programming tools more broadly, and encourages us to share our perspective on where coding technologies are going over the long term. First, let’s explore what a programming language is for across three critical dimensions…
Top AI researcher dismisses AI ‘extinction’ fears, challenges ‘hero scientist’ narrative
In a recent interview Kyunghyun Cho — who is highly regarded for his foundational work on neural machine translation, which helped lead to the development of the Transformer architecture that ChatGPT is based on — expressed disappointment about the lack of concrete proposals at the recent Senate hearings related to regulating AI’s current harms, as well as a lack of discussion on how to boost beneficial uses of AI…Daft: the distributed Python dataframe for complex data
Daft is a fast, Pythonic and scalable open-source dataframe library built for Python and Machine Learning workloads…The Daft dataframe is a table of data with rows and columns. Columns can contain any Python objects, which allows Daft to support rich complex data types such as images, audio, video and more…
We Are Writing Python Polars: The Definitive Guide
Polars is a highly performant DataFrame library for manipulating structured data. The core is written in Rust, and the library is officially available in Python, Rust, NodeJS, R, and SQL. Its three key selling points are:Record-breaking speed on common DataFrame operations
Processing of larger than memory datasets
Explicit, concise, and flexible syntax…
Approximating Shapley Values for Machine Learning
In a previous post, I explained the theory behind Shapley values. I also explained that calculating Shapley values for real world machine learning use cases is typically computationally infeasible, which is why in practice, methods that approximate them are used instead. In this article, we will explore a simple approach for approximating Shapley values. This sets the foundation for discussing the foremost technique for estimating Shapley values: SHAP…
Understanding GPT tokenizers
Large language models such as GPT-3/4, LLaMA and PaLM work in terms of tokens. They take text, convert it into tokens (integers), then predict which tokens should come next. Playing around with these tokens is an interesting way to get a better idea for how this stuff actually works under the hood. OpenAI offer a Tokenizer tool for exploring how tokens work I’ve built my own, slightly more interesting tool as an Observable notebook…
Examples of Good DS Portfolios? [Reddit Discussion]
Is there a data scientist portfolio that you're really proud of? A friend's portfolio that you envy? A standard which you aspire to have your portfolio come within light years of? I want to see it. I'm looking for some examples of really stellar data science portfolios so that I know what I should be striving towards myself. I need training data…
ChatGPT is fun, but it is not funny! Humor is still challenging Large Language Models
We put ChatGPT's sense of humor to the test. In a series of exploratory experiments around jokes, i.e., generation, explanation, and detection, we seek to understand ChatGPT's capability to grasp and reproduce human humor. Since the model itself is not accessible, we applied prompt-based experiments. Our empirical evidence indicates that jokes are not hard-coded but mostly also not newly generated by the model. Over 90% of 1008 generated jokes were the same 25 Jokes…
Jobs
(Remote) Data Scientist at Cloudflare
 |
As part of this initiative, we are looking for a strong Data Scientist to join Cloudflare and help us drive predictive analytic insights and best practices at scale from the ground up. This is a high visibility role and success in this role comes from marrying a strong data & modeling background with acute product and business acumen to deliver highly strategic and compelling insights that accelerate our business growth and influence our product decisions within Cloudflare.
What we look for:
Predictive modeling techniques, machine learning, model creation and deployment, storytelling and visualization, strong business & product acumen, cross-functional collaboration, creative problem solving, agile mindset
Apply here
Want to post a job here? Email us for details --> team@datascienceweekly.org
Training & Resources
The {marginaleffects} 📦 book is now online
25 chapters on post-estimation analyses and interpretation with #Rstats. The 📖 is full of tutorials, case studies, tips, and technical notes. Please check it out and let us know how we can improve this resource…Your guide to AI: June 2023
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering key developments in AI policy, research, industry, and startups during May 2023…A gentle introduction to DeepScatter: visualizing millions of points in the browser
Benjamin Schmidt, the author Deepscatter, has an impressive & feature-full example of what deepscatter can do in this notebook. Here, however, is a far more bare-bones example using the same data…
Last Week's Newsletter's 3 Most Clicked Links
* Based on unique clicks (25,659 opens, 46% substack open rate).
** Find last week's issue #497 here.
Cutting Room Floor
Thanks for joining us this week :)
All our best,
Hannah & Sebastian
P.S.,
If you found this newsletter helpful, consider supporting us by becoming a paid subscriber here: https://datascienceweekly.substack.com/subscribe
:)
Copyright © 2013-2023 DataScienceWeekly.org, All rights reserved.
You're currently a free subscriber to Data Science Weekly Newsletter. For the full experience, upgrade your subscription.
![]()
![]()
Older messages
Data Science Weekly - Issue 497
Friday, June 2, 2023
Curated news, articles and jobs related to Data Science
Data Science Weekly - Issue 496
Friday, May 26, 2023
Curated news, articles and jobs related to Data Science
Data Science Weekly - Issue 495
Friday, May 19, 2023
Curated news, articles and jobs related to Data Science
Data Science Weekly - Issue 494
Friday, May 12, 2023
Curated news, articles and jobs related to Data Science
Data Science Weekly - Issue 493
Friday, May 5, 2023
Curated news, articles and jobs related to Data Science
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your