The Sequence Chat: Daniel J. Mankowitz, DeepMind on Building AlphaDev to Discover New Computer Science Algorithms
Was this email forwarded to you? Sign up here The Sequence Chat: Daniel J. Mankowitz, DeepMind on Building AlphaDev to Discover New Computer Science AlgorithmsOne of the researchers behind DeepMind's groundbreaking model that discovered new sorting algorithms shares his insights about the experience.
👤 Quick bio
I was born and raised in Johannesburg, South Africa. I always had an interest in building things and solving problems, with a specific interest in computers and electronics. This is what led me to doing my first degree in Electrical and Information Engineering at the University of the Witwatersrand in Johannesburg. How I got started in Machine Learning: In the early 2010’s Artificial Intelligence was not yet mainstream, especially in South Africa. I found out about a Master’s program at the University of Edinburgh in Machine Learning and Computer vision and was determined to attend the program. I managed to get a scholarship and discovered a whole new world of possibility with Artificial Intelligence through this program. One such course was Reinforcement Learning which I took a particular liking to and this led me on a path to doing my PhD in hierarchical reinforcement learning at the Technion Israel Institute of Technology. Current role: My current role is focused on applying core Deepmind technologies to real-world products and applications. This requires me to deeply understand product needs and requirements, have a thorough understanding of the capabilities of the research technologies, and using my experience to determine whether a particular research technology fits with a particular product. 🛠 ML Work
Following our success where we incorporated MuZero in Youtube’s video compression pipeline, we realized that we could apply these core RL technologies to real world applications. We then began to brainstorm where we could take these technologies next. We live in an increasingly digital society with more and more applications, screens etc and this leads to an increase in energy demand and consumption. With Moore’s law coming to an end and chips reaching their fundamental physical limits, we need new and innovative ways to optimize the computing stack. This led us to identifying fundamental algorithms (such as sorting and hashing) that are called trillions of times every day. If we could improve these algorithms, we could help optimize one important aspect of the stack - the software that runs on it.
One aspect is that AlphaDev built the algorithms in the assembly language. This was a critical design decision that gave us added flexibility to find new optimizations. This is because we were operating at a much lower level (i.e., manipulating memory and CPU registers) than typical high level programming languages such as C++. Another aspect is that we optimized directly for actual measured latency (speed). This was no small feat. We needed to build a system that could measure sorting algorithms accurately on the order of nanoseconds. There are many sources of noise and as a result, we designed a latency benchmarking server that would take thousands of measurements across multiple machines for generating a single latency value for a given algorithm. This scale of taking measurements enabled us to accurately measure and optimize for latency.
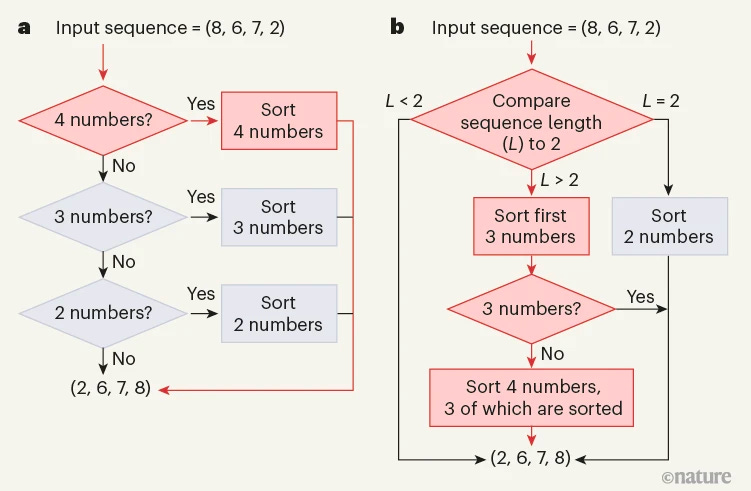
When we first began the AlphaDev project, we decided to try and learn a sort3 algorithm (i.e., sorting 3 elements) from scratch. This means that AlphaDev began with an empty buffer and had to iteratively build an algorithm that can sort three elements from the ground up. This is incredibly challenging as a huge space of algorithms needed to be explored efficiently by AlphaDev - there are more possible algorithms that can be built from scratch, even for sorting three elements, than the number of atoms in the universe! We visually analyzed the state of the art’s assembly code for sort3 and couldn’t find any way to improve it. We were convinced that AlphaDev could not improve this algorithm further and would probably learn to produce the human benchmark. However, to our surprise, it discovered a sort3 algorithm from scratch that had one less assembly instruction. This, we initially thought, was a mistake. However, upon further analysis, we realized that it discovered what we called the AlphaDev swap move. This is a sequence of instructions, that when applied under specific conditions, saves an instruction. For the swap move, it assumes that given 3 values A,B,C - it can be applied when B<=C - See AlphaDev swap move section and Figures 3a,b,c in our Nature paper. AlphaDev discovered this same move in other sorting algorithms too such as when it generated a sort5 algorithm from scratch. We had a similar experience with the AlphaDev copy move which can be applied under the condition that for 4 inputs <A,B,C,D>, we have that D>=min(A,C). See AlphaDev copy move section and Figures 3d,e,f in our paper. Another very interesting case is that of variable sort 4 (VarSort4). Here the input to the sorting algorithm is a vector of up to 4 elements. In this case, AlphaDev discovered, from scratch, VarSort4 algorithms up to 29 instructions shorter than the human benchmark, with fundamentally different structures! (see the image below from the Nature News and Views article - Figure a is the human benchmark, figure b is the fastest discovered AlphaDev VarSort4 algorithm). You can also read the ‘New variable sort algorithms’ section in our paper.
As a result, we realized that there are optimizations to algorithms that we don’t know about, or can’t see, but are still out there. And hopefully these optimizations can also influence how we construct other fundamental algorithms too.
Once we discovered faster sorting algorithms, we wanted to see whether AlphaDev could generalize to other fundamental computer science algorithms. Using the analogy of a librarian, sorting algorithms could be used by a librarian to sort books from A to Z. Hashing on the other hand, provides the librarian with a very efficient way to search for and retrieve a particular book. A book is assigned a unique identifier, which we refer to as a hash, and the librarian is then able to know exactly where to find the book as opposed to searching through the entire library. Hashing algorithms for data structures are called trillions of times everyday and are used in applications for information storage and retrieval. Hashing algorithms define their “correctness” in terms of the number of hashing collisions. So AlphaDev learned an improved hashing algorithm that had a minimal number of collisions and was 30% faster than the current algorithm in Abseil. As such it replaced the benchmark in Abseil and is now used by millions of developers, companies and applications around the world.
AlphaZero leverages the power of search and value functions to efficiently explore incredibly large combinatorial problems. For context, discovering a faster sorting algorithm requires searching through a space of algorithms similar in size to the number of possible games in Chess and Go and the number of atoms in the Universe. The value function gives AlphaDev a prediction as to whether the final program will be fast and correct and this is critical to determining how to efficiently explore this massive space of algorithms – AlphaDev’s value function only needs to be trained on the actual measured latency of approximately 0.002% of the algorithms it generates (using its latency benchmarking server). 💥 Miscellaneous – a set of rapid-fire questions
All areas of AI are fascinating and interesting to me. At the moment I am very interested in Reinforcement Learning from Human Feedback. This technology has shown the ability to better align Large Language Models (LLMs) with human preferences. Model alignment is critical in developing language models that provide value to humans such as saving time and resources, as well as ensuring safe and responsible responses too.
AlphaDev can be generalized to many more algorithms. Some examples include compression algorithms, both lossy (e.g., image compression) and lossless (e.g., file compression), cryptographic hashing, serialization, deserialization etc. Currently, AlphaDev does not support algorithms with loops, although this is possible to support in future work. It may also struggle if you want AlphaDev to optimize a huge algorithm or codebase (e.g., an entire library). In this case, additional break-throughs are necessary.
Yes, they both have AlphaZero as their base algorithm. The power of search and value functions are critical in both cases. However, they both play very different single player games which have different properties and algorithmic requirements. For example, in the case of AlphaDev it was critical for us to measure actual measured latency.
This is indeed a tough question :) I think definitions are very important, and I don’t have a good opinion as to whether this is a valid variation or not. What I can say is that we are taking a step forward to optimizing the computing stack which will hopefully enable us to make further progress with AI as well as the evergrowing computational bottleneck from our increasingly digital society. You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|



Older messages
Edge 303: The Top Two Types Retrieval-Augmented Language Models
Tuesday, June 27, 2023
What are the main types of techniques to augment LLMs with external information.
📝 Guest Post: Choosing the Right Vector Index For Your Project*
Monday, June 26, 2023
In this post, Frank Liu. ML Architect at Zilliz, discusses vector databases and different indexing strategies for approximate nearest neighbor search. The options mentioned include brute-force search,
The Generative Audio Momentum
Sunday, June 25, 2023
Sundays, The Sequence Scope brings a summary of the most important research papers, technology releases and VC funding deals in the artificial intelligence space.
Edge 302: Inside MPT-7B: MosaicML's Suite of Open Source LLMs that Supports 65k Tokens
Thursday, June 22, 2023
The new suite of models was released by MosaicML and support models optimized for Instructions, Chats, Stories and More.
The Sequence Chat: Vipul Ved Prakash, CEO, Together on Decentralized, Open Source Foundation Models
Wednesday, June 21, 2023
Together has been behind some of the most interesting releases in open source foundation models.
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your