The Sequence Pulse: The Architecture Powering Data Drift Detection at Uber
Was this email forwarded to you? Sign up here The Sequence Pulse: The Architecture Powering Data Drift Detection at UberData anonaly detection at massive scale.
In case you missed yesterday’s newsletter due to July the 4th holiday, we discussed the universe of in-context retrieval augmented LLMs or techniques that allow to expand the LLM knowledge without altering its core architecutre. It’s a good one. Go check it out. Uber runs one of the most sophisticated data and machine learning(ML) infrastructures in the planet. It’s Michelangelo platform has been used as the reference architecture for many MLOps platforms over the last few years. Uber innvoations in ML and data span across all categories of the stack. Recently, the Uber engineering team unveiled some details about their work in data anomaly detections which is one of the most mainstream problems in ML workflows. Like any large tech company, data is the backbone of the Uber platform. Not surprisingly, data quality and drifting is incredibly important. Many data drift error translates into poor performance of ML models which are not detected until the models have ran. A recent study of data drift issues at Uber reveled a highly diverse perspective.
Uber recognizes the need for a robust automated system that can effectively measure and monitor column-level data quality. With this objective in mind, Uber has developed D3, also known as the Dataset Drift Detector. Inside D3Automated Onboarding: D3 leverages offline usage to identify and prioritize important columns within a dataset. By applying monitors to these columns, D3 minimizes the need for extensive configuration from dataset owners during the onboarding process.
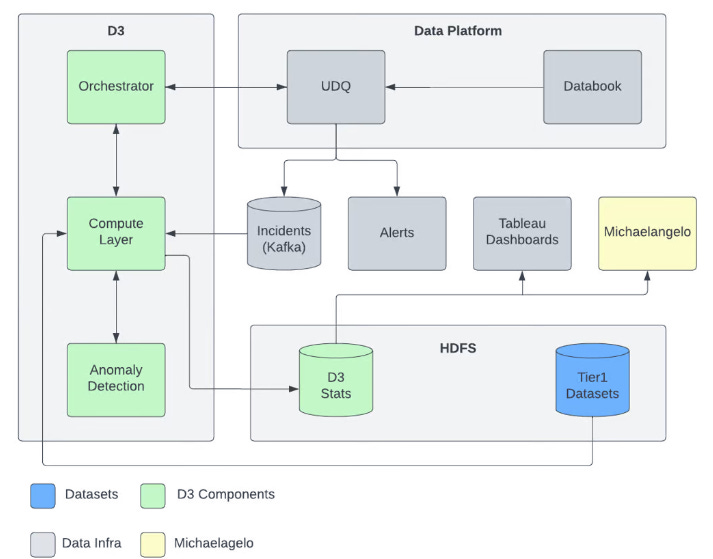
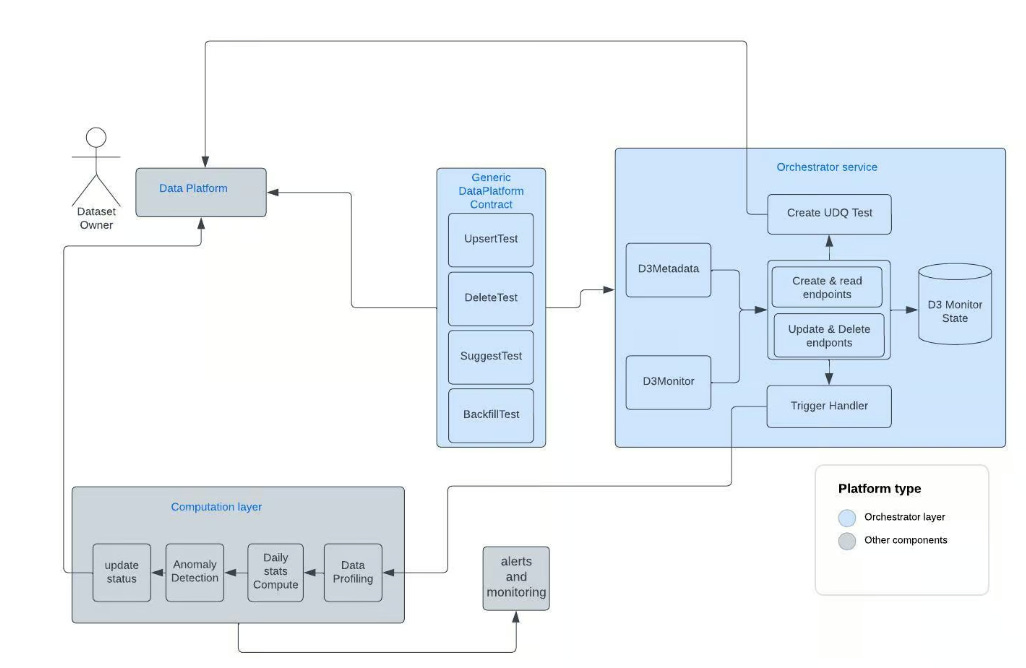
The ArchitectureThe D3 architecture comprises several core systems managed by Uber's Data Platform, which play a crucial role in maintaining data quality. Here are the key systems briefly mentioned in this article:
From a component perspective, D3 is structured in three main different areas:
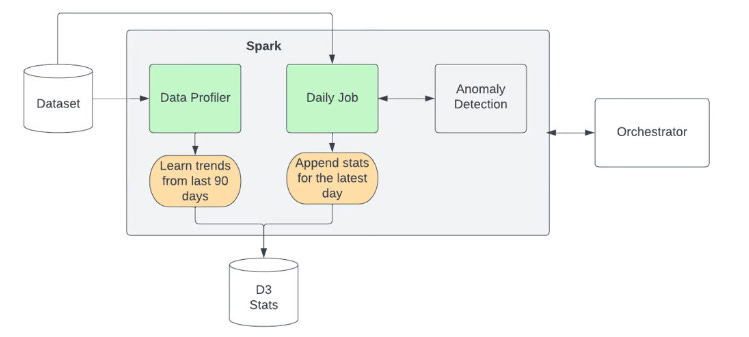
1) Compute LayerThe compute layer plays a central role in Uber's D3 framework. When a dataset is onboarded onto D3, two types of jobs are executed as part of the compute layer lifecycle:
These compute jobs are implemented as generic Spark jobs that operate on each dataset. Monitors are expressed as SQL statements using Jinja templates. The D3 dataset configuration is utilized to translate these templates into actual SQL queries executed within the Spark application. The computed statistics from both the data profiler job and the daily scheduled job are stored in the Hive D3 stats table. Alerting and monitoring mechanisms are established on top of this table. The compute layer of D3 leverages the power of Spark and SQL to efficiently process and analyze the dataset, enabling the identification of data drift and deviations from expected patterns. By persisting the computed statistics in a dedicated table, Uber ensures continuous monitoring and provides a foundation for timely alerts and further analysis of data quality issues.
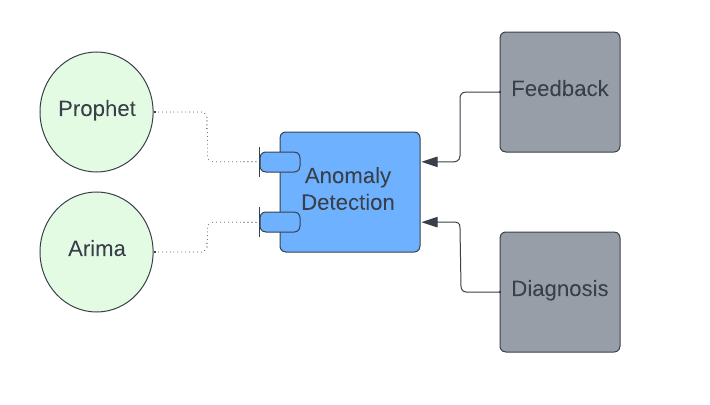
2) Anomaly Detection at UberAt Uber, data observability has traditionally relied on manually curated SQL-based tests with static alerting thresholds. This approach demands ongoing attention and recalibration to adapt to the ever-changing data trends. However, with the implementation of Anomaly Detection, Uber gains a more flexible and dynamic alerting system. Specifically for the D3 use case, Uber focuses on tuning the models to prioritize high precision and reduce the occurrence of false alerts. The integration of any anomaly detection model into the D3 framework is designed to be plug and play. It leverages generic User-Defined Function (UDF) interfaces, allowing each model to have its own custom implementation. During the configuration process, users can conveniently select their preferred anomaly detection method without concerning themselves with the underlying technical details. For any anomaly detection model, the input consists of time series data, while the expected output is the predicted limits within which the monitor value should fall. Although base limits can sometimes be more aggressive and lead to a higher number of false positives, Uber aims to employ a high-precision model. Typically, this involves defining conservative alerting limits in addition to the base limits. These alerting limits are dynamically determined based on the base limits, ensuring a responsive and accurate anomaly detection system. By integrating Anomaly Detection into the D3 framework, Uber enhances its data observability capabilities. The ability to select and fine-tune anomaly detection models empowers Uber's tech audience to maintain a vigilant eye on data quality and swiftly identify any deviations from expected patterns.
3) OrchestratorThe Orchestrator component plays a vital role in Uber's D3 framework, serving as a service component that exposes D3 capabilities to the external world. It acts as a mediator, facilitating seamless communication between the Uber data platform and D3. One of the key responsibilities of the Orchestrator is managing two crucial resources:
The Orchestrator actively manages the lifecycle of D3 monitors, including profiling data, statistical computation, anomaly detection, and status updates to the components of the Uber Data Platform. It ensures that D3 remains synchronized with any changes in the dataset schema. Moreover, the Orchestrator supports both scheduled and ad hoc trigger-based statistical computation, enabling efficient and timely monitoring of data quality. Additionally, it facilitates monitor updates, such as handling metadata changes (e.g., dimension or aggregator modifications) and updates to monitor attributes (e.g., threshold or monitor type changes), ensuring that the corresponding monitors and statistics are appropriately updated. To maximize the effectiveness of D3 in identifying data quality issues at scale and with speed, the recommended approach is to create D3-enabled tests through the user interface of Databook. To enable this seamless integration, the Orchestrator has been integrated with the Uber Data Platform, providing a unified and streamlined experience. Uber's Data Platform, specifically the Unified Data Quality (UDQ) component, offers a generic API contract that allows any system to integrate, create, and maintain data quality tests and their lifecycles. The Orchestrator implements these functionalities to address the needs of data consumers, including:
By leveraging the Orchestrator and its integration with the Uber Data Platform, D3 empowers data consumers with a powerful and versatile tool for maintaining data quality and effectively detecting any issues that may arise.
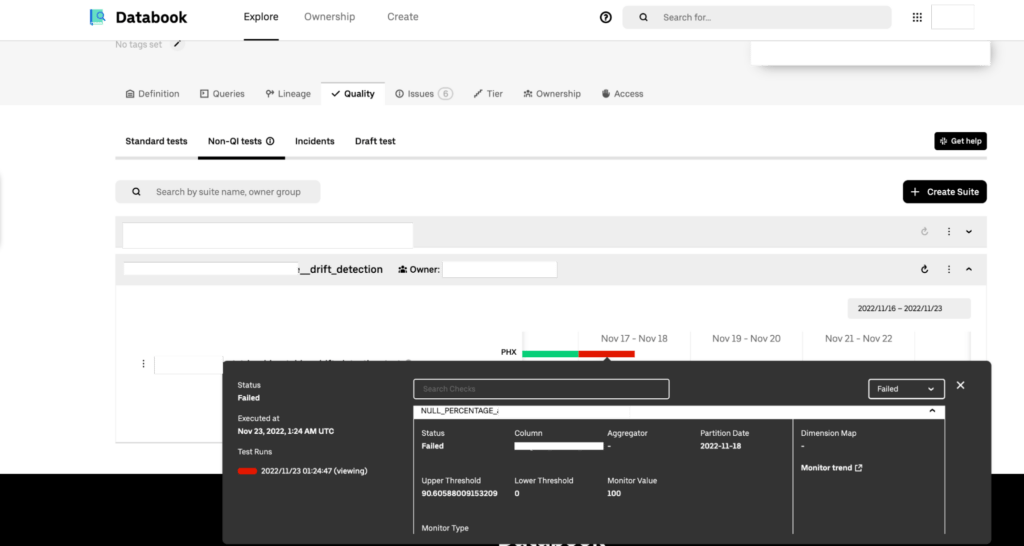
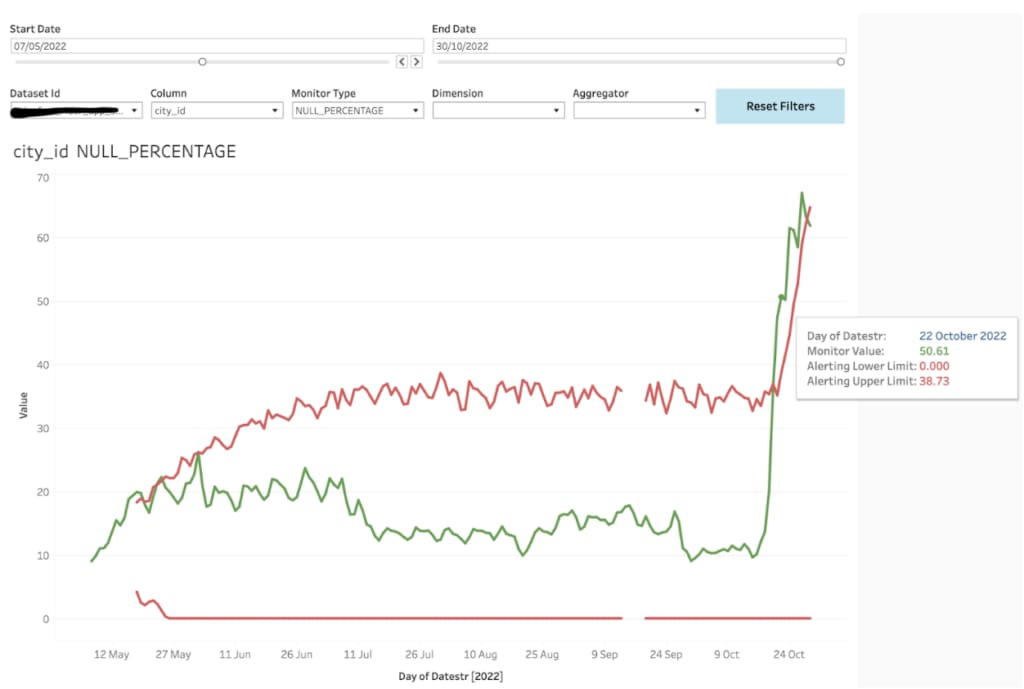
AlertingD3 has established a robust system for data quality alerting and monitoring to ensure the reliability and accuracy of its datasets. The computed statistics values, along with the dynamically generated thresholds from the data profiler and daily scheduled jobs, are securely persisted in a Hive-based stats table. This stats table serves as a critical resource for validating data quality and assessing the completeness and uptime of each dataset. To enable timely response and resolution, alerting mechanisms are seamlessly integrated with the databook monitoring service and pager duty on-call system, aligning with Uber's standard practices for service management. Whenever a threshold breach occurs in the persisted stats table, an alert is triggered, notifying the relevant teams for immediate action. Furthermore, the stats table plays a crucial role in configuring the tableau dashboard for data visualization, which is seamlessly integrated with the databook platform. This integration allows for a comprehensive and intuitive representation of data quality metrics, enhancing data exploration and analysis capabilities for Uber's tech audience.
D3 is one of the most complete reference architecture for data drifting at scale. Many of its components can be reused in enteprrise data quality pipelines. Uber has expressed that future work in D3 might include new data drift detection algorithms and ML model quality monitoring. You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|



Older messages
Edge 305: In-Context Retrieval-Augmented Language Models
Tuesday, July 4, 2023
Can we augment the knowledge of LLMs with external information without modifying their architecture?
💡Webinar: To train or not to train your 🅻🅻🅼
Monday, July 3, 2023
While GPT-style models perform admirably initially, developing practical solutions in real-world scenarios remains complex. Is prompt engineering alone sufficient to achieve the desired accuracy? Are
Open Source Scored the First Major M&A of the Generative AI Era
Sunday, July 2, 2023
Next Week in The Sequence: Edge 305: Our generative AI series continues with an overview of in-context, retrieval-augmented LLMs including Google's original paper in the space. We also explore the
💡Webinar: Designing & Scaling FanDuel's ML Platform—Best Practices & Lessons Learned
Friday, June 30, 2023
Discover FanDuel's journey in building a powerful ML platform for personalized experiences. Join the webinar on July 11 at 9 am PT to learn how they scaled their platform and implemented best
Edge 304: Inside AlphaDev: DeepMind’s Newest Breakthrough Model that Was Able to Discover New Computer Science Alg…
Thursday, June 29, 2023
Built on the foundation created by AlphaZero, the model discovered new and improved existing sorting algorithms.
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your