Horrific-Terrific - 🔍 Where are all my precious answers?
🔍 Where are all my precious answers?They’ve been eaten by a corporation, deal with it like the rest of us and buy twenty different media subscriptions
Hello friends, I was in absentia for about a month just there because Reality’s sticky venomous tendrils yanked me out of my internet dream space and put my girlfriend into the hospital. She’s all better now but that was scary for a minute there. Finally, I can return to my pixel dungeon of likes and upvotes. The theme of this week’s newsletter is: why do we still not know how to value digitised information? It feels as though information is everywhere but it’s either very poor quality, or it’s being enclosed by profit-making companies. Proof:
There was a popular phrase in tech ethics circles around 2018/19 which made you sound like you really knew what you were talking about at conferences: when the product is free, you are the product. In 2023 we have new phrases that we say at conferences to let everyone around us know that we are savvy thought-leaders who deserve our ridiculously high salaries. If you are caught still using the phrase when the product is free, you are the product, you are probably one bad meeting away from having all your ideas ignored by all the new Gen Z’s around the office (they keep saying ‘based’ and you don’t know what it means). Okay but the thing is: the phrase is still true. Nothing has really changed. Many online spaces are still geared around the idea that we are the products; not the content. And actually, I’ve been finding it really annoying that even people within tech ethics circles will wring their hands and wonder why they can’t read one news article without trying to bypass a paywall or avoid a horrific tundra of ads and auto-playing videos. They’ve forgotten — somehow — that on the internet, content is secondary to traffic. The sole purpose of many online publications is not to create ‘good’ content, but to sell the promise of our collective attention to advertisers. Ryan Broderick recently summed this dynamic up nicely, explaining that it kind of all started with Facebook’s recommendation engine:
He touches on legacy media rushing to catch up, and often getting it wrong — but of course basically everyone is getting it wrong now, because there isn’t a single trend that will stay still for long enough for anyone to even know what it is. Now that Facebook’s growing irrelevance is becoming impossible to ignore, and Twitter is burying itself alive, users are caught in the warring dynamics of legacy media organisations, and online media publishers. It’s all a product of these four internet-breaking events:
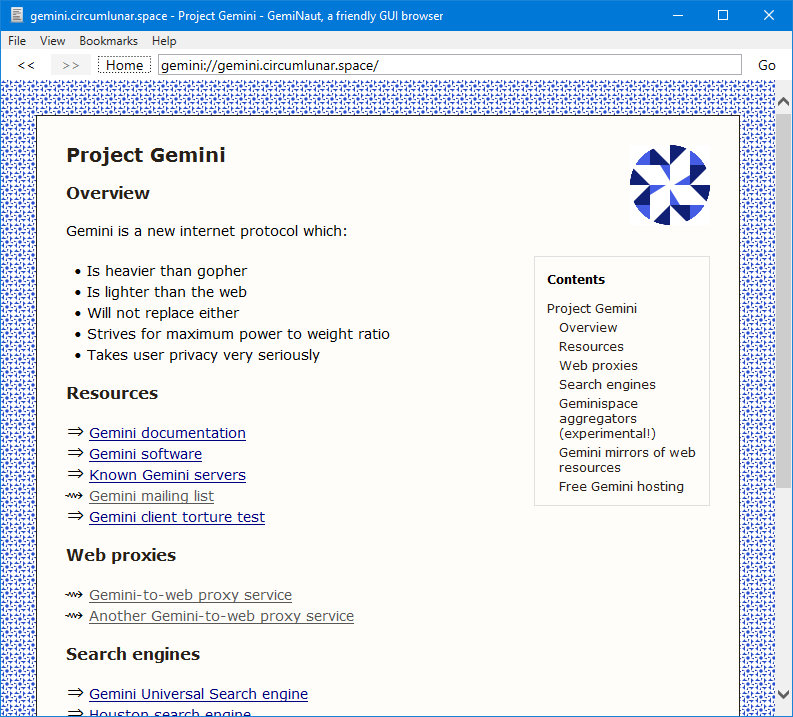
The overall result is an internet peppered with infuriating modals asking you either to subscribe or ‘consent’ to cookies. No one is really winning here. I think that the digitisation of information has made it impossible to value correctly, if that’s even something we’re supposed to be doing. Another overused but very true phrase comes to mind: information wants to be free. But the kind of information that we get for free is not even good — because it’s clickbait. I think there’s a difference between reading what you want to read, and reading something because you are outraged. As someone who ingests a lot of tech news, the information I want is not novel or interesting on it’s own; I just want a handful of updates on the various stories I’m following. There will never ever be a time where I will want to look at a slow, banner-addled website over a bland list of headlines or wall of plain text. I will use every tool I have in my belt to ensure that I never actually read news from the news website itself, because the experience is so tiresome and unpleasant (in case you’re interested I use a mixture of Techmeme, Feedbro, Instapaper, and just… reader view tbh). This does make you wonder who the internet is even for. Online publishers spend all that time and effort to build websites that we will bend over backwards to avoid completely, and extract only the raw content. Some of the most bent-over people (sorry) are the team behind Project Gemini, which is an alternative internet protocol that allows you to experience websites as a series of documents (which is what they really are) rather than an over-designed splatter of data-hungry web apps masquerading as news publications. Gemini takes a bit of setting up, but once you’re in you’ll notice that the ‘websites’ are centred around only one thing: displaying information. These websites are built with Gemtext, a markup language that looks so unbelievably simple to use that anyone, even if you don’t know how to code, could probably throw a Gemini website together quite easily. But most importantly, there is no Javascript; the ‘websites’ do not force your browser to download flashy graphics and tracking technologies; they just display content. It’s therefore impossible for targeted ads to exist in this kind of ecosystem.
This of course could never (and was never intended to) replace the web, because you can’t really build anything truly interactive or dynamic, like games, or online stores, etc. This is an internet for people who just want to find and ingest information, without all the noise. People on Gemini have constructed all kinds of aggregators that pull articles from the web so that others can read without hassle. They also write their own content and share it, and probably descend into petty arguments just like with any other online space. Learning about how Gemini works has made me think about how content creators would operate in its ecosystem: if there was a way to securely send payments on this protocol, in theory content creators could just make content and get paid for it directly, without having to rely on some kind of rigid creator platform taking a cut of every transaction and payout. I also don’t even think anyone would call them ‘content creators’, because really that’s just a silly marketing categorisation; a kind of synthetic demographic of internet users from which corporations can extract labour (the making of content) and money (a cut of every subscription payment). If everyone was truly free to actually make content outside the confines of ‘platforms’, things would be very different. You certainly wouldn’t get any mishaps like the recent one on Patreon, where something fucked up with their payment providers and creators woke up to a sudden halt in their income. Okay but what about libraries? Remember those?It’s funny, legacy media organisations and ‘content creators’ both want the same thing in the end: to get paid for the work they produce. BUT where a legacy media org is dripping with resources and a well-established reputation, a content creator only has an iPad with a cracked screen and 2.5k followers on a website that is now called ‘X’. The logics of our present dark and crumbling reality mean that legacy media institutions, such as dusty old book publishers, don’t even make money from books anymore — they make money from suing libraries. You may have heard that recently Hachette, HarperCollins, Wiley, and Penguin Random House have just sued The Internet Archive for making their books available in their online library, and so now The Archive will have to stop lending all commercially available books by these particular publishers. Before we continue I need to make something abundantly clear: The Internet Archive is just a library; it’s a fucking library, okay?? It collects and purchases A LOT of media and puts it in a free and open archive so people can look at it and delight at the wonders of human creativity. You know, A LIBRARY. Why would BOOK PUBLISHERS be mad at LIBRARIES? The Internet Archive mimics the mechanics of a brick and mortar library by using controlled digital lending (CDL) which means if only one physical copy of the book exists among The Internet Archive’s collection, then the digitised version can only be borrowed by one person at a time. They use encryption to ensure that their digitised versions of books and texts can’t be copied across the web infinitely — which is exactly what Hachette et al are afraid of. But what they fail to understand is that the whole point of a library is to prevent this kind of piracy. If the information is already free and open for all, then it’s free and open for all — you can’t ‘steal’ what’s free! Smh 💆♀️. All this lawsuit has done is squeeze money out of a very cool non-profit, and ensure that the publishers own books are read by less people. I’m more than sure that this behaviour is not the product of an unreasonable phobia of digitisation, but rather a way to compensate for a drop in book sales. I don’t know anything about publishing obviously, but maybe they should consider producing better books or, I don’t know, adapt to shifting market trends. I mentioned this when discussing platform decay: the control of content for profit results in channels of information being closed down, giving us less choice. There is an assumption that making information free and open will somehow devalue it — but the value in information isn’t in what people will pay for it, it’s surely in what they can learn from that information. 💌 Thank you for subscribing to Horrific/Terrific. If you need more reasons to distract yourself try looking at my website or maybe this ridiculous zine that I write or how about these silly games that I’ve made. Enjoy!
|

Older messages
🐍 Automation is a snake eating its own tail
Friday, July 28, 2023
The division of labour and the fallacy that automation provides freedom from work
🔰 Tired millennials batting away recommendation algorithms
Monday, July 17, 2023
Sorry but 'For You' has never really been 'for me'
🤤 Why is existential risk so alluring?
Friday, July 7, 2023
We're all doomed! God isn't there just something so hot about that
🎨 Formats over platforms
Friday, June 30, 2023
Is 'TikTok' the name of a platform or just a content format that people really like?
🧟 We are experiencing platform decay
Tuesday, June 20, 2023
The Reddit blackout gives us one less channel of information
You Might Also Like
Master the New Elasticsearch Engineer v8.x Enhancements!
Tuesday, March 4, 2025
Need Help? Join the Discussion Now! ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ elastic | Search. Observe. Protect Master Search and Analytics feb 24 header See
Daily Coding Problem: Problem #1707 [Medium]
Monday, March 3, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Facebook. In chess, the Elo rating system is used to calculate player strengths based on
Simplification Takes Courage & Perplexity introduces Comet
Monday, March 3, 2025
Elicit raises $22M Series A, Perplexity is working on an AI-powered browser, developing taste, and more in this week's issue of Creativerly. Creativerly Simplification Takes Courage &
Mapped | Which Countries Are Perceived as the Most Corrupt? 🌎
Monday, March 3, 2025
In this map, we visualize the Corruption Perceptions Index Score for countries around the world. View Online | Subscribe | Download Our App Presented by: Stay current on the latest money news that
The new tablet to beat
Monday, March 3, 2025
5 top MWC products; iPhone 16e hands-on📱; Solar-powered laptop -- ZDNET ZDNET Tech Today - US March 3, 2025 TCL Nxtpaper 11 tablet at CES The tablet that replaced my Kindle and iPad is finally getting
Import AI 402: Why NVIDIA beats AMD: vending machines vs superintelligence; harder BIG-Bench
Monday, March 3, 2025
What will machines name their first discoveries? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
GCP Newsletter #440
Monday, March 3, 2025
Welcome to issue #440 March 3rd, 2025 News LLM Official Blog Vertex AI Evaluate gen AI models with Vertex AI evaluation service and LLM comparator - Vertex AI evaluation service and LLM Comparator are
Apple Should Swap Out Siri with ChatGPT
Monday, March 3, 2025
Not forever, but for now. Until a new, better Siri is actually ready to roll — which may be *years* away... Apple Should Swap Out Siri with ChatGPT Not forever, but for now. Until a new, better Siri is
⚡ THN Weekly Recap: Alerts on Zero-Day Exploits, AI Breaches, and Crypto Heists
Monday, March 3, 2025
Get exclusive insights on cyber attacks—including expert analysis on zero-day exploits, AI breaches, and crypto hacks—in our free newsletter. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
⚙️ AI price war
Monday, March 3, 2025
Plus: The reality of LLM 'research'