📝 Guest Post: Introduction to DiskANN and the Vamana Algorithm*
Was this email forwarded to you? Sign up here In this tutorial, Frank Liu, Solutions Architect at Zilliz, will deep dive into DiskANN, a graph-based indexing strategy, their first foray into on-disk indexes. Like HNSW, DiskANN avoids the problem of figuring out how and where to partition a high-dimensional input space and instead relies on building a directed graph to the relationship between nearby vectors. As the volume of unstructured data continues to grow in the upcoming decade, the need for on-disk indexes will likely rise, as will research around this area. Let’s explore! Approximate Nearest Neighbors Oh Yeah (Annoy for short) is a tree-based indexing algorithm that uses random projections to iteratively split the hyperspace of vectors, with the final split resulting in a binary tree. Annoy uses two tricks to improve accuracy/recall - 1) traversing down both halves of a split if the query point lies close to the dividing hyperplane, and 2) creating a forest of binary trees. Although Annoy isn't commonly used as an indexing algorithm in production environments today (`HNSW` and `IVF_PQ` are far more popular), Annoy still sets a strong baseline for tree-based vector indexes. At its core, Annoy is still an in-memory index. In previous articles, we’ve only looked at in-memory indexes - vector indexes that reside entirely in RAM. On commodity machines, in-memory indexes are excellent for smaller datasets (up to around 10 million 1024-dimensional vectors). Still, once we move past 100M vectors, in-memory indexes can be prohibitively expensive. For example, 100M vectors alone will require approximately 400GB of RAM. Here's where an on-disk index - a vector index that utilizes both RAM and hard disk - would be helpful. In this tutorial, we'll dive into DiskANN, a graph-based vector index that enables large-scale storage, indexing, and search of vectors by persisting the bulk of the index on NVMe hard disks. We'll first cover Vamana, the core data structure behind DiskANN, before discussing how the on-disk portion of DiskANN utilizes a Vamana graph to perform queries efficiently. Like previous tutorials, we'll also develop our implementation of the Vamana algorithm in Python. The Vamana algorithmVamana's key concept is the relative neighborhood graph (RNG). Formally, edges in an RNG for a single point are constructed iteratively so long as a new edge is not closer to any existing neighbor. If this is difficult to wrap your head around, no worries - the key concept is that RNGs are constructed so that only a subset of the most relevant nearest edges are added for any single point in the graph. As with HNSW, nearby vectors are determined by the distance metric that's being used in the vector database, e.g., cosine or L2. There are two main problems with RNGs that make them still too inefficient for vector search. The first is that constructing an RNG is prohibitively expensive:
The second is that setting the diameter of an RNG is difficult. High-diameter RNGs are too dense, while RNGs with low diameters make graph traversal (querying the index) lengthy and inefficient. Despite this, RNGs remain a good starting point and form the basis for the Vamana algorithm.
In broad terms, the Vamana algorithm solves both of these problems by making use of two clever heuristics: the greedy search procedure and the robust prune procedure. Let's walk through both of these, along with an implementation, to see how these work together to create an optimized graph for vector search. As the name implies, the greedy search algorithm iteratively searches for the closest neighbors to a specified point (vector) in the graph `p`. Loosely speaking, we maintain two sets: a set of nearest neighbors `nns` and a set of visited nodes `visit`.
`nns` is initialized with the starting node, and at each iteration, we take up to `L` steps in the direction closest to our query point. This continues until all nodes in `nns` have been visited. Robust prune, on the other hand, is a bit more involved. This heuristic is designed to ensure that the distance between consecutive searched nodes in the greedy search procedure decreases exponentially. Formally, robust prune, when called on a single node, will ensure that the outbound edges are modified such that there are at most `R` edges, with a new edge pointing to a node at least `a` times distant from any existing neighbor.
With these two heuristics, we can now focus on the full Vamana algorithm. A Vamana graph is first initialized so each node has `R` random outbound edges. The algorithm then iteratively calls `_greedy_search` and `_robust_prune` for all nodes within the graph. As we've done for all of our previous tutorials on vector indexes, let's now put it all together into a single script:
That's it for Vamana! All code for this tutorial is freely available at https://github.com/fzliu/vector-search. Explore Other Vector Database 101 courses*This post was written by Frank Liu, Solutions Architect at Zilliz, and originally published here. We thank Zilliz for their insights and ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|

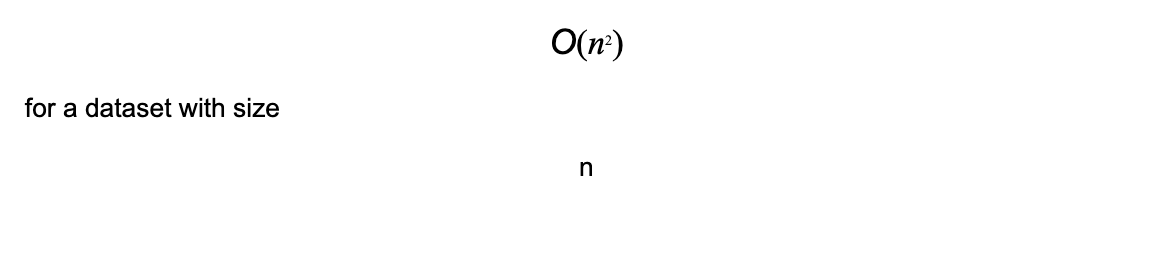


Older messages
DeepMind's AlphaFold-Latest is Pushing the Boundaries of Scientific Exploration
Sunday, November 5, 2023
The model continues making breakthroughts in digital biology.
📣 ML Engineering Event: Join HelloFresh, Remitly, Riot Games, Uber & more at apply(ops)
Friday, November 3, 2023
apply(ops) is just around the corner! Join the global ML community at this virtual event—speakers from companies like HelloFresh, Lidl Digital, Meta, PepsiCo, Riot Games, and more will share best
Meet AutoGen: Microsoft's Super Innovative Framework for Autonomous Agents
Thursday, November 2, 2023
A new open source framework that streamlines reasoning and communication with agents.
Edge 339: What is Prefix-Tuning
Tuesday, October 31, 2023
One of the simplest ways to fine-tune LLMs
📝 Guest Post: Adala – The First Open Source Data-Labeling Agent*
Monday, October 30, 2023
In this guest post, Jimmy Whitaker, Data Scientist in Residence at Human Signal, introduces Adala, an Autonomous Data Labeling Agent framework that harmonizes AI's computational power with human
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your