📝 Guest Post: Creating your first Data Labeling Agent*
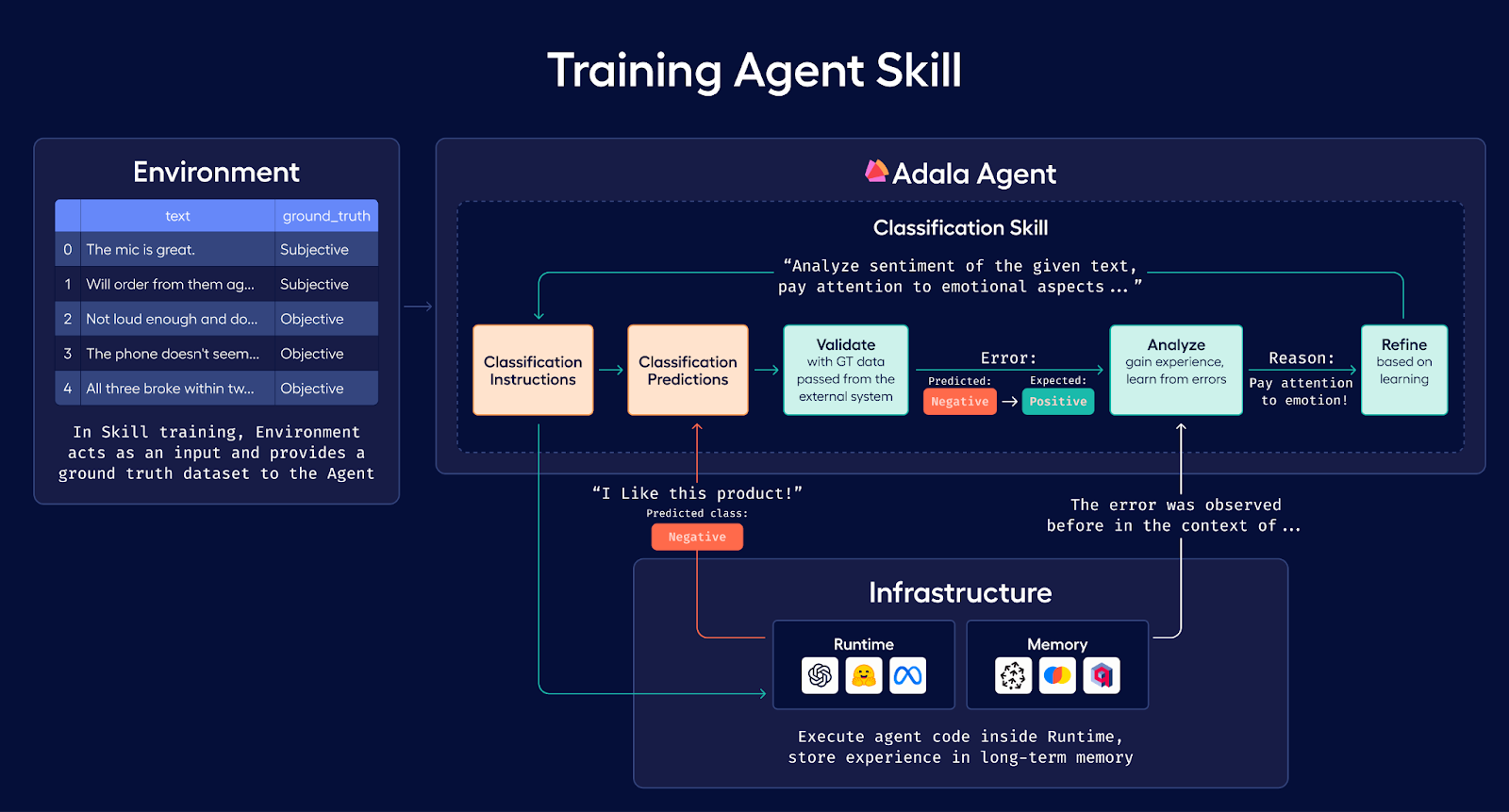
Was this email forwarded to you? Sign up here In this guest post, Jimmy Whitaker, Data Scientist in Residence at Human Signal, focuses on guiding users in building an agent using the Adala framework. He dives into the integration of Large Language Model-based agents for automating data pipelines, particularly for tasks like data labeling. The article details the process of setting up an environment, implementing an agent, and the iterative learning approach that enhances the agent's efficiency in data categorization. This approach combines human expertise with AI scalability, making these agents more effective in precise data tasks. LLM-based agents have remarkable capabilities in problem-solving, leading to a surge in their application across various industries. They can adapt their instructions to accomplish tasks, all through human-generated prompts. Unsurprisingly, channeling these capabilities reliably is becoming a crucial task. Adala is a framework for creating LLM-based agents to automate data pipelines, including tasks like data labeling and data generation. Its primary function is to provide these agents with guided learning opportunities, enabling them to act within the confines of a ground truth dataset and learn through dynamic feedback. The concept behind Adala is to combine human precision and expertise with AI model scalability. By doing so, these agents become more efficient in tasks where accurate data categorization is paramount.
This article aims to guide you through building your first data labeling agent using the Adala framework. The focus will be on understanding the underlying principles of these agents, setting up the necessary environment, and implementing a simple yet effective agent capable of classifying data based on a provided ground truth dataset. Through this, you will gain insights into the technical aspects of creating such an agent and the practical applications and benefits it offers. Getting started with AdalaIn this example, we will work through the Classification Skill Example notebook provided by Adala, using the pre-built classification skill. We aim to develop an agent that aids in data labeling for text classification, specifically categorizing product descriptions. Adala agents are autonomous and have the novel ability to teach themselves, acquiring skills through iterative learning. As their environment evolves, agents continuously refine these skills. The agent will then teach itself by comparing its predictions to the ground truth dataset, using trial and error to refine its labeling instructions. In many cases, having LLMs perform these tasks can be sufficient. However, relying solely on LLMs comes at a high operational cost. Curating a dataset to distill this prior knowledge into a simpler model is more cost-effective over time. Creating an Initial DatasetWe begin by creating an initial dataset for the agent to learn from. To show the learning process for the agents, we’ll start with a labeled dataset in a pandas DataFrame (df) that will be used as our ground truth data.
This code generates a dataframe with product descriptions and their corresponding categories, like so:
Building Your First Adala AgentBuilding an Adala agent involves integrating two critical components: skills and the environment.
We start with the pre-built `ClassificationSkill`. This skill restricts the LLM output to the data labels. When run, this skill generates predictions in a new column within our DataFrame, enriching our environment with valuable insights. In practical scenarios, the environment can be set up to gather ground truth signals from actual human feedback, further enhancing the learning phase of the agent. Here's how to set up your Adala agent:
As we continually add data to our ground truth dataset, the agent gains access to more sophisticated and diverse information, enhancing its learning and predictive capabilities. Agent LearningThe learning process of the agent involves three distinct steps:
The agent autonomously cycles through these steps when the `learn` function is called. This iterative process of applying skills, analyzing results, and making improvements enables the agent to align its predictions more closely with the ground truth dataset. The cycle can repeat until the agent achieves a state where errors are minimized or eliminated.
This command displays the enhanced classification skill. For instance, the skill to categorize products is now fine-tuned with specific examples, showcasing the agent's improved understanding and classification accuracy:
These examples illustrate the agent’s ability to accurately label products based on their primary function or purpose, demonstrating the effectiveness of the learning process. Testing the Agent’s SkillWith the agent's skills refined, it's time to assess its categorization capability using new product descriptions. The following example showcases a test DataFrame:
The `run` command enables the agent to apply its learned classification skill to the new dataset, predicting the most appropriate category for each product description. These predictions can be incorporated into data labeling platforms like Label Studio for human verification. This is one of the key aspects of Adala - incorporating human feedback by way of ground truth data. Once reviewed, we can optionally add this data to our environment to iteratively improve our classification skill. Where does Adala fit?Adala, as a framework for creating autonomous data agents, occupies a unique niche in the landscape of LLM-based applications. Its comparison with other notable LLM implementations like OpenAI GPTs and AutoGPT highlights its distinctive role and capabilities. Unlike the broad applicability of OpenAI GPTs in generating text and engaging in conversation, Adala's focus is narrower yet deeper in its domain of data processing. Another differentiator is that Adala is a framework for building “data-centric” agents guided by human feedback, whether a ground truth dataset or reviewing predictions via different channels. This specialization makes Adala more suited for tasks that require precision and reliability, a critical aspect of machine learning and data analysis. Although it can utilize the same GPT models from OpenAI, Adala has the capacity to support multiple runtimes depending on the domain-specific use case, economics, or even requirements for data privacy. ConclusionAdala distinguishes itself in the generative AI arena today by enhancing data labeling accuracy and efficiency, and the community will continue work to automate data pipelines that fuel AI models and applications. Adala's focused approach to data labeling makes it a vital tool for combining human-like meticulousness with AI scalability. Adala is under active development with new releases every two weeks. The latest version, 0.3.0, includes additional skills and environments along with a number of other enhancements. To keep abreast of these developments, follow the Adala repository on GitHub. Also, try these features and capabilities on your own data and share your feedback with us in the Adala Discord! *This post was written by Jimmy Whitaker, Data Scientist in Residence at Human Signal. We thank HumanSignal for their insights and ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|




Older messages
Thank you for supporting TheSequence
Sunday, November 19, 2023
TheSequence Thank you for reading TheSequence. As a token of our appreciation, we're offering you a limited-time offer of 20% off a paid subscription. Redeem special offer Here are the benefits you
I Promise, this Editorial is NOT About OpenAI
Sunday, November 19, 2023
Some major milestones in generative video were announced this week.
😎 Private Preview: Build Real-Time AI Applications Using Only Python
Friday, November 17, 2023
Our friends from Tecton launched a new, AI-optimized, Python-based compute engine called Rift. Now you can build real-time AI applications in minutes! Using Tecton with Rift, you can: Build better
Edge 344: LLMs and Memory is All You Need. Inside One of the Most Shocking Papers of the Year
Friday, November 17, 2023
Can memory-augmented LLMs simulate any algorithm?
Edge 343: Understanding Llama-Adapter Fine-Tuning
Tuesday, November 14, 2023
One of the most intriguing fine-tuning methods that combines prefix-tuning and PEFT.
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your