📝 Guest Post: LoRA Land: 25 Fine-Tuned Mistral-7b LLMs that Rival or Outperform GPT-4
Was this email forwarded to you? Sign up here In this guest post, Predibase team discusses their recent release of LoRA Land that they built to demonstrate a real world example of how smaller, task-specific fine-tuned models can cost-effectively outperform leading commercial alternatives. It’s a fascinating read! We’re excited to release LoRA Land, a collection of fine-tuned Mistral-7b models that consistently outperform base models by 70% and GPT-4 by 4-15%, depending on the task. LoRA Land’s 27 task-specialized large language models (LLMs) were all fine-tuned with Predibase for less than $8.00 each on average and are all served from a single A100 GPU using LoRAX, our open source framework that allows users to serve hundreds of adapter-based fine-tuned models on a single GPU. This collection of specialized fine-tuned models–all trained with the same base model–offers a blueprint for teams seeking to efficiently and cost-effectively deploy highly performant AI systems. Join our webinar on February 29th to learn more!
* We observed that when performing fine-tuning the Mistral-7B base model with our default configuration on two datasets (MagicCoder and WebNLG) the performance was significantly lower compared to GPT-4. We are continuing to investigate these results further and details will be shared in our upcoming paper.How Efficient Fine-Tuning and Serving Entered the SpotlightWith the continuous growth in the number of parameters of transformer-based foundation models and the emergence of large language models (LLMs) with billions of parameters, it has become increasingly challenging to adapt them to specific downstream tasks, especially in environments with limited computational resources or budgets. Parameter Efficient Fine-Tuning (PEFT) and Quantized Low Rank Adaptation (QLoRA) offer an effective solution by reducing the number of fine-tuning parameters and memory usage while achieving comparable performance to full fine-tuning. Predibase has incorporated these best practices into its fine-tuning platform and, to demonstrate the accessibility and affordability of adapter-based fine-tuning of open-source LLMs, has fine-tuned 25 models for less than $8 each on average in terms of GPU costs. Fine-tuned LLMs have historically also been very expensive to put into production and serve, requiring dedicated GPU resources for each fine-tuned model. For teams that plan on deploying multiple fine-tuned models to address a range of use cases, these GPU expenses can often be a bottleneck for innovation. LoRAX, the open-source platform for serving fine-tuned LLMs developed by Predibase, enables teams to deploy hundreds of fine-tuned LLMs for the cost of one from a single GPU.
By building LoRAX into the Predibase platform and serving many fine-tuned models from a single GPU, Predibase is able to offer customers Serverless Fine-tuned Endpoints, meaning users don’t need dedicated GPU resources for serving. This enables:
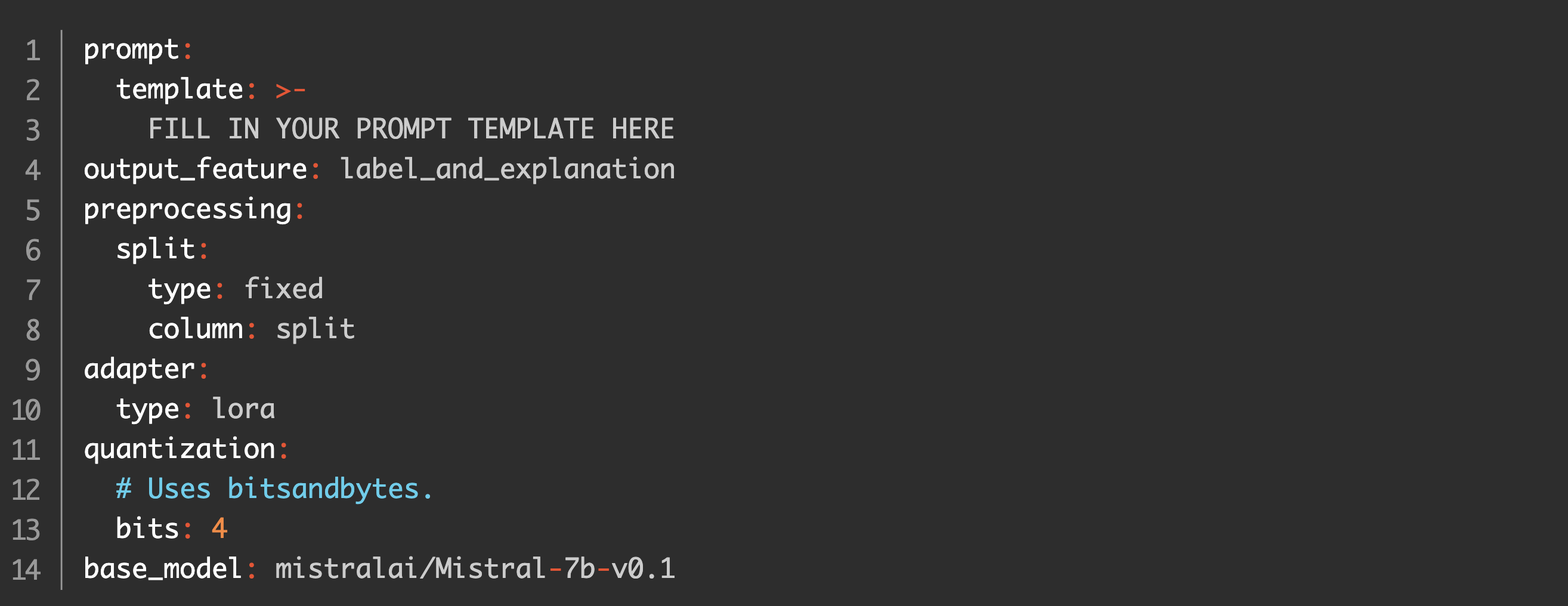
These underlying technologies and fine-tuning best practices built into Predibase significantly simplified the process of creating this collection of fine-tuned LLMs. As you’ll see, we were able to create these task-specific models that outperform GPT-4 with mostly out of the box training configurations. MethodologyDataset SelectionWe selected our datasets from ones that were widely available and either commonly used in benchmarking or as a proxy for industry tasks. Datasets that reflected common tasks in industry include content moderation (Jigsaw), SQL generation (WikiSQL), and sentiment analysis (SST2). We’ve also included evaluations on datasets that are more commonly evaluated in research, such as CoNLL++ for NER, QQP for question comparison, and many others. The tasks we fine-tuned span from classical text generation to more structured output and classification tasks. The length of the input texts varied substantially across tasks, ranging from relatively short texts to exceedingly long documents. Many datasets exhibited a long-tail distribution, where a small number of examples have significantly longer sequences than the average. To balance between accommodating longer sequences and maintaining computational efficiency, we opted to train models with a p95 percentile of the maximum text length. We define fixed splits for reproducibility based on published train-validation-test splits, when available. Training Configuration TemplatePredibase is built on top of the open source Ludwig framework, which makes it possible to define fine-tuning tasks through a simple configuration YAML file. We generally left the default configuration in Predibase untouched, mostly focusing on editing the prompt template and the outputs. While Predibase allows users to manually specify various fine-tuning parameters, the default values have been refined by fine-tuning 100s of models to maximize performance on most tasks out of the box. Here is an example of one of the configurations we used:
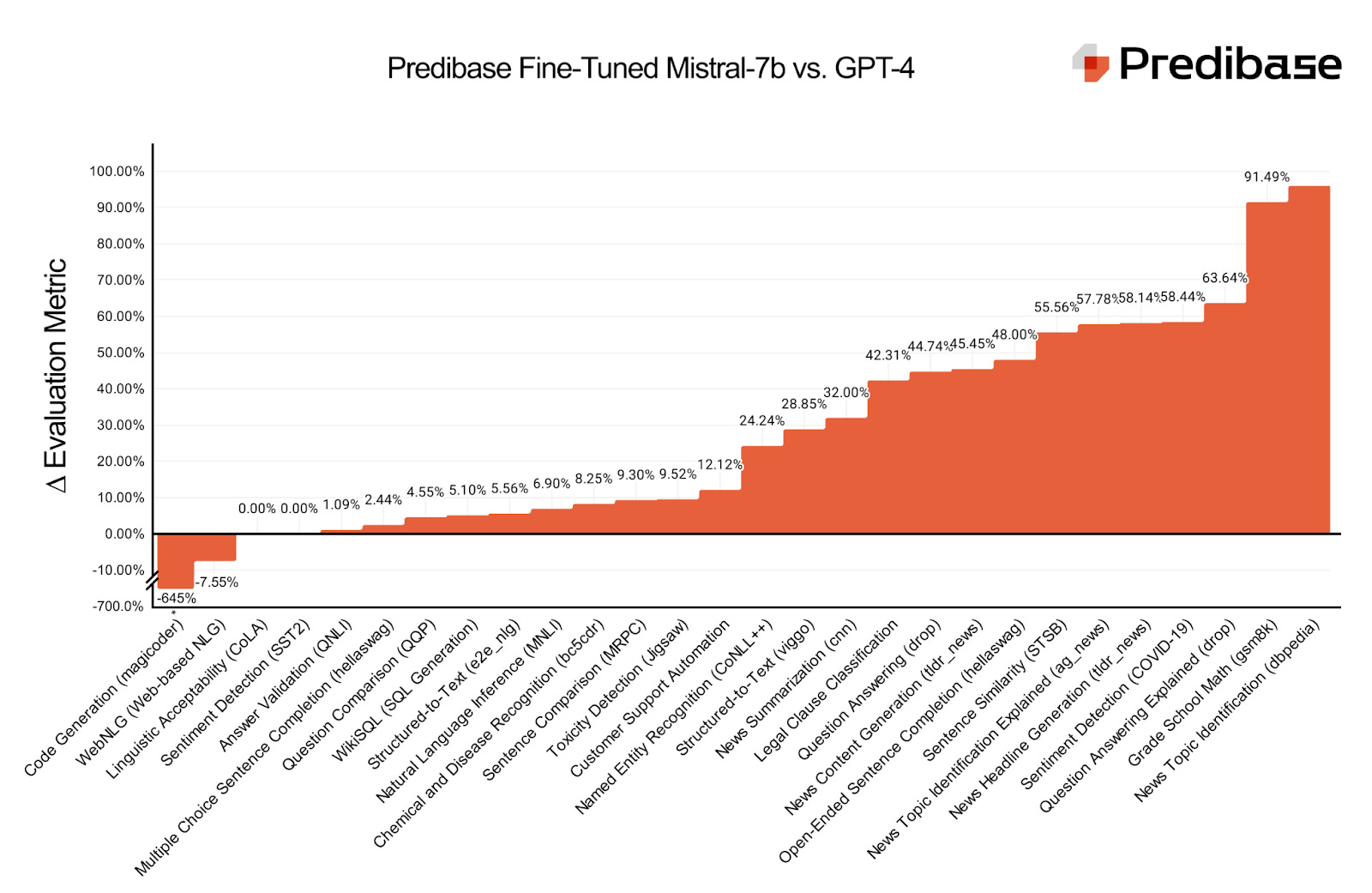
Prompt SelectionWhen fine-tuning an LLM, users can define a prompt template to apply to each datapoint in the dataset to instruct the model about the specifics of the task. We deliberately chose prompt templates that would make the task fair for both our adapters and for instruction-tuned models like GPT-4. For example, instead of passing in a template that simply says “{text}”, the prompt includes detailed instructions about the task. Single-shot and few-shot examples are provided for tasks that require additional context like named entity recognition and data-to-text. Evaluation MetricsWe created a parallelized evaluation harness that sends high volumes of queries to Predibase LoRAX-powered REST APIs, which also allows us to collect thousands of responses for OpenAI, Mistral, and fine-tuned models in a matter of seconds. For evaluating model quality, we assess each adapter on fixed, 1000-sample subsets of held out test data excluded from training. We typically employ accuracy for classification tasks and ROUGE for tasks involving generation. However, in instances where there's a mismatch in the models' output types (for example, when our adapter produces an index while GPT-4 generates the actual class), we resort to designing custom metrics to facilitate a fair comparison of scores. We plan to publish a comprehensive paper in the coming weeks, providing an in-depth explanation of our methodology and findings. ResultsOf the 27 adapters we provided, 25 match or surpass GPT-4 in performance. In particular, we found that adapters trained on language-based tasks, rather than STEM-based ones, tended to have higher performance gaps over GPT-4. A full table comparing fine-tuned Mistral-7b, Mistral-7b, Mistral-7b-instruct, GPT-4, and GPT-3.5-turbo is available on our blog. Try the Fine-Tuned Models YourselfYou can query and try out all the fine-tuned models in the LoRA Land UI. We also uploaded all the fine-tuned models on HuggingFace so that you can easily download and play around with them. The Importance of Specialized AI ModelsWhile organizations have been racing to productionize LLMs ever since the debut of ChatGPT in late 2022, many chose to avoid the pitfalls of commercial LLMs in favor of trying to build their own. Leading commercial LLMs can help teams develop proofs of concept and get started generating quality results without any training data but come with trade offs in terms of:
To overcome these challenges, many teams turned to either building their own Generative Pre-training Transformer (GPT) from scratch or to fine-tuning an entire model with billions or trillions of parameters. These approaches, however, are prohibitively expensive and require enormous computational resources that are out of reach for most organizations. This in turn has driven the adoption of smaller, specialized LLMs and efficient approaches like the above-mentioned PEFT and QLoRA. These techniques reduce the training requirements–in terms of compute, time, and data–by orders of magnitude and make developing fine-tuned LLMs like those hosted in LoRA Land accessible even for teams with limited resources and smaller budgets. We built LoRA Land to provide a real world example of how smaller, task-specific fine-tuned models can cost-effectively outperform leading commercial alternatives. Predibase makes it much faster and far more resource efficient for organizations to fine-tune and serve their own LLMs, and we're happy to provide the tools and infrastructure for teams that want to start deploying specialized LLMs to power their business.
This post was written by the Predibase team. We thank Predibase for their insights and ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|



Older messages
Edge 372: Learn About CALM, Google DeepMind's Method to Augment LLMs with Other LLMs
Thursday, February 22, 2024
Just like RAG but with LLMs! ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Edge 371: Two-Step LLM Reasoning with Skeleton of Thoughts
Tuesday, February 20, 2024
Created by Microsoft Research, the technique models some of the aspects of human cognitive reasoning in LLMs. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
📌 ML Engineering Event: Mastering AI and ML at Production Scale at apply()
Monday, February 19, 2024
Join the next apply() virtual conference on Wednesday, April 3, for a free event that brings together the engineering community to master AI and ML in production. Since 2021, apply() has hosted more
Edge 370: A Deep Dive Into AlphaGeometry: Google DeepMind’s New Model that Solves Geometry Problems Like a Math Ol…
Monday, February 19, 2024
The model uses a neurosymbolic approach to reasong through complex problems. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
More Super Models is All We Need
Monday, February 19, 2024
Five major foundation models released in a single week! ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your