📝 Guest Post: Evaluating LLM Applications*
Was this email forwarded to you? Sign up here To successfully build an AI application, evaluating the performance of large language models (LLMs) is crucial. Given the inherent novelty and complexities surrounding LLMs, this poses a unique challenge for most companies. Peter Hayes, who holds a PhD in Machine Learning from University College London, is one of the world’s leading experts on this topic. As CTO of Humanloop, Peter has assisted companies such as Duolingo, Gusto, and Vanta in solving LLM evaluation challenges for AI applications with millions of daily users. Today, Peter shares his insights on LLM evaluations. In this 5-minute read, you will learn how to apply traditional software evaluation techniques to AI, understand the different types of evaluations and when to use them, and see what the lifecycle of evaluating LLM applications looks like at the frontier of Generative AI. This post is a shortened version of Peter’s original blog, titled 'Evaluating LLM Applications'.
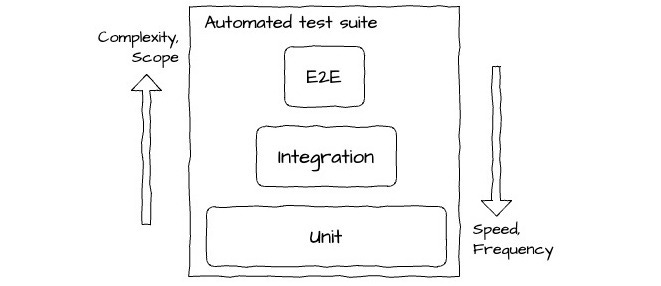
Take lessons from traditional softwareA large proportion of teams now building great products with LLMs aren't experienced ML practitioners. Conveniently many of the goals and best practices from software development are broadly still relevant when thinking about LLM evals. Automation and continuous integration is still the goalCompetent teams will traditionally set up robust test suites that are run automatically against every system change before deploying to production. This is a key aspect of continuous integration (CI) and is done to protect against regressions and ensure the system is working as the engineers expect. Test suites are generally made up of 3 canonical types of tests: unit, integration and end-to-end.
Typical makeup of a test suite in software development CI. Unit tests tend to be the hardest to emulate for LLMs.
The most effective mix of test types for a given system often sparks debate. Yet, the role of automated testing as part of the deployment lifecycle, alongside the various trade-offs between complexity and speed, remain valuable considerations when working with LLMs. Types of evaluation can vary significantlyWhen evaluating one or more components of an LLM block, different types of evaluations are appropriate depending on your goals, the complexity of the task and available resources. Having good coverage over the components that are likely to have an impact over the overall quality of the system is important. These different types can be roughly characterized by the return type and the source of, as well as the criteria for, the judgment required. Judgment return types are best kept simpleThe most common judgment return types are familiar from traditional data science and machine learning frameworks. From simple to more complex:
Simple individual judgments can be easily aggregated across a dataset of multiple examples using well known metrics. For example, for classification problems, precision, recall and F1 are typical choices. For rankings, there are metrics like NDCG, Elo ratings and Kendall's Tau. For numerical judgments there are variations of the Bleu score. I find that in practice binary and categorical types generally cover the majority of use cases. They have the added benefit of being the most straight forward to source reliably. The more complex the judgment type, the more potential for ambiguity there is and the harder it becomes to make inferences. Model sourced judgments are increasingly promisingSourcing judgments is an area where there are new and evolving patterns around foundation models like LLMs. At Humanloop, we've standardised around the following canonical sources:
Typical makeup of different sources of evaluation judgments. AI evaluators are a good sweet spot for scaling up your evaluation process, while still providing Human-level performance. Model judgments in particular are increasingly promising and an active research area. The paper Judging LLM-as-a-Judge demonstrates that an appropriately prompted GPT-4 model achieves over 80% agreement with human judgments when rating LLM model responses to questions on a scale of 1-10; that's equivalent to the levels of agreement between humans. I believe teams should consider shifting more of their human judgment efforts up a level to focus on helping improve model evaluators. This will ultimately lead to a more scalable, repeatable and cost-effective evaluation process. As well as one where the human expertise can be more targeted on the most important high-value scenarios. Different stages of evaluation are necessaryDifferent stages of the app development lifecycle will have different evaluation needs. I've found this lifecycle to naturally still consist of some sort of planning and scoping exercise, followed by cycles of development, deployment and monitoring. These cycles are then repeated during the lifetime of the LLM app in order to intervene and improve performance. The stronger the teams, the more agile and continuous this process tends to be. Development here will include both the typical app development; orchestrating your LLM blocks in code, setting up your UIs, etc, as well more LLM specific interventions and experimentation; including prompt engineering, context tweaking, tool integration updates and fine-tuning - to name a few. Both the choices and quality of interventions to optimize your LLM performance are much improved if the right evaluation stages are in place. It facilitates a more data-driven, systematic approach. From my experience there are 3 complementary stages of evaluation that are the give the highest ROI in supporting rapid iteration cycles of the LLM block-related interventions:
Recommended stages for a robust evaluation process. Interactive, offline and online. It's usually necessary to co-evolve to some degree the evaluation framework alongside the app development as more data becomes available and requirements are clarified. The ability to easily version control and share across stages and teams both the evaluators and the configuration of your app can significantly improve the efficiency of this process. At Humanloop, we’ve developed a platform for enterprises to evaluate LLM applications at each step of the product development journey. To read the full blog on Evaluating LLM Applications, or learn more about how help enterprises reliably put LLMs in production, you can visit our website. *This post was written by Peter Hayes, CTO of Humanloop. We thank Humanloop for their insights and ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|


Older messages
Can I Solve Science?
Sunday, March 10, 2024
A brilliant essay by Stephen Wolfram explores this challenging question. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
📌 ML Engineering Event: Lineup for apply() 2024 is Now Live!
Friday, March 8, 2024
Exciting news! The speaker lineup for apply() 2024 is now live. Join industry leaders from LangChain, Meta, and Visa for insights to master AI and ML in production. Here's a sneak peek of the
Edge 376: The Creators of Vicuna and Chatbot Arena Built SGLang for Super Fast LLM Inference
Thursday, March 7, 2024
Created by LMSys, the framework provides a tremendous optimizations to improve the inference times in LLMs by 5x. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The Sequence Chat: Yohei Nakajima on Creating BabyAGI, Autonomous Agents and Investing in Generative AI
Wednesday, March 6, 2024
The creator of one of the most popular open source generative AI projects shares his views about AI tech, investing and the future. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Edge 375: Meta's System 2 Attention is a Very Unique LLM Reasoning Method
Tuesday, March 5, 2024
The method has been inspired by cognitive psychology and has immediate impact in LLM reasoning. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your