Data Science Weekly - Data Science Weekly - Issue 538
Data Science Weekly - Issue 538Curated news, articles and jobs related to Data Science, AI, & Machine Learning
Issue #538 |

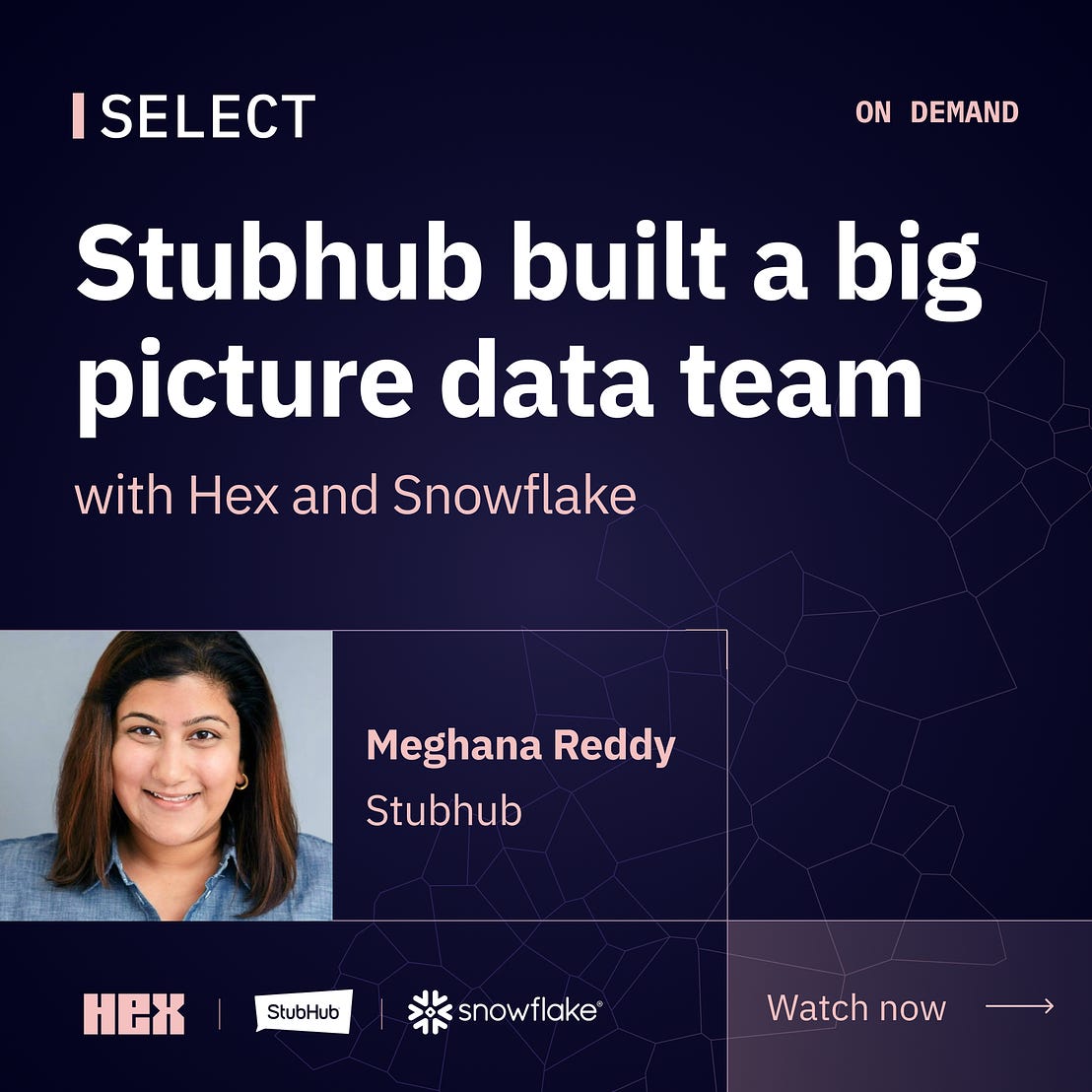 |
Building a Big Picture Data Team at StubHub
See how Meghana Reddy, Head of Data at StubHub, built a data team that delivers business insights accurately and quickly with the help of Snowflake and Hex.
The challenges she faced may sound familiar:
Unclear SMEs meant questions went to multiple people
Without SLAs, answer times were too long
Lack of data modeling & source-of-truth metrics generated varying results
Lack of discoverability & reproducibility cost time, efficiency and accuracy
Static reporting reserved interactivity for rare occasion
Register now to hear how Meghana and the StubHub data team tackled these challenges with Snowflake and Hex. And watch Meghana demo StubHub’s data apps that increase quality and speed to insights.
* Want to sponsor the newsletter? Email us for details --> team@datascienceweekly.org
Data Science Articles & Videos
Diffusion models from scratch, from a new theoretical perspective
This tutorial aims to introduce diffusion models from an optimization perspective as introduced in our paper (joint work with Frank Permenter). It will go over both theory and code, using the theory to explain how to implement diffusion models from scratch. By the end of the tutorial, you will learn how to implement training and sampling code for a toy dataset, which will also work for larger datasets and models. In this tutorial we will mainly reference code from smalldiffusion. For pedagogical purposes, the code presented here will be simplified from the original library code, which is on its own well-commented and easy to read…How are simple token predictors able to do so much stuff these days? [Reddit]
Everyone tells me that LLMs, even the SOTA ones like GPT-4, Claude 3 are nothing but glorified statistics machines predicting the next token. A year or so ago, I could understand that…But, nowadays, LLMs seem to be capable of much more and I'm curious how?…How do all these work? They're still Transformers at their core, right? And will we see LLMs become capable of much more advanced tasks as the models become bigger and bigger, or do we need some other architectures…Magix - Supercharge huggingface transformers with model parallelism.
Magix is a mininalist toolkit for training LLM with flexible data and model parallel.Training Billion-scale LLM on GPUs and TPUs.
Familiar Huggingface model interfaces and eco-system (dataset, hub, etc.).
Pre-defined model parallel (sharding) rules for popular models like Llama, Mistral, Gemma, etc.
Acceleration with flash attention and operation fusion.
Fast checkpoint save/restore with arbirary device and parallism design.
…If you have ever used Huggingface Flax transformers, using magix is as simple as adding several magic functions into the common worflow…
A Bayesian Approach to Linear Mixed Models (LMM) in R/Python
Here’s what I’ll cover (both in R and Python):Practical methods to select priors (needed to define a Bayesian model)
A step-by-step guide on how to implement a Bayesian LMM using R and Python (with
brmsandpymc3, respectively)Quick MCMC diagnostics to help you catch potential problems early on in the process…
Cloud native data loaders for machine learning using zarr and xarray
There is a lack of established best practices for efficiently managing machine learning training pipelines due to the diverse range of data formats used when storing scientific data. In this blog post, we discuss an architecture that we have found highly effective in seamlessly integrating multidimensional arrays from cloud storage into machine learning frameworks…bayesianbandits - A Pythonic microframework for multi-armed bandit problems
Problem: Despite having a conceptually simple interface, putting together a multi-armed bandit in Python is a daunting task…Solution:bayesianbanditsis a Python package that provides a simple interface for creating and running Bayesian multi-armed bandits. It is built on top of scikit-learn and scipy, taking advantage of conjugate priors to provide fast and accurate inference…While the API is still evolving, this library is already being used in production for marketing optimization, dynamic pricing, and other applications…What is the hardest you have ever seen someone work manually? [Reddit]
I once worked with a team who was in charge of some sales dashboards. Their process to update them was to have someone individually open the PDF's of every new invoice for the week, enter the dollar figures into an excel sheet, and then update the workbook datasource with the new static excel file. I work for a global market leader, we are lapping the #2 company behind us 5 times over. I would estimate that 5-10% of our headcount is allocated to jobs like these…How I saved $70k a month in BigQuery
Learn the simple yet powerful optimization techniques that helped me reduce BigQuery spend by $70,000 a month…When data engineering projects scale, optimization comes into play and becomes a challenging thing to solve. In this article, I will focus on the cost optimization part of one of the Data Engineering Pipeline that I worked as a sole Engineer…Model commoditization and product moats
GPT4’s level of performance has been replicated within multiple organizations. GPT3’s level of performance has been reproduced by many. GPT2 level models can be trained by almost everyone (probably on the order of $1k to do in a few hours). The early idea that models could maybe be moats has been so resoundingly defeated that people don’t expect language model providers to have any moats…
Building the whole ML platform from the ground up [Reddit]
I got a new job as an MLE (currently a data scientist) and I will have to make the whole infrastructure from the ground up on AWS…I've done deployments and things related to MLE in the past , read books about it but never done anything like this before…How do I avoid failure?…What are the things to look out for?…Base R - match()
’ve sort of rediscovered base R’smatch()function recently, so I figured I’d add a page here about it…Per it’s documentation, match “returns a vector of the positions of (first) matches of its first argument in its second.”…So let’s illustrate this with the following data…What I learned from looking at 900 most popular open source AI tools
Four years ago, I did an analysis of the open source ML ecosystem. Since then, the landscape has changed, so I revisited the topic. This time, I focused exclusively on the stack around foundation models…After MANY hours, I found 896 repos…It was a painful but rewarding process. It gave me a much better understanding of what people are working on, how incredibly collaborative the open source community is, and just how much China’s open source ecosystem diverges from the Western one…
Training & Resources
Python Foundation for Spatial Analysis
This [free] playlist contains videos for our Python Foundation for Spatial Analysis course…
Evaluating Bayesian Mixed Models in R/Python
In this article, my goal guide is you through some useful model checking and evaluation VISUAL METHODS for Bayesian models (not your typical RMSE) in both R and Python…Awesome Local AI - An awesome repository of local AI tools
Covering:
- Inference Engine
- Inference UI
- Platforms / full solutions
- Developer tools
- Agents
- Training
and more…
Last Week's Newsletter's 3 Most Clicked Links
What python data visualization package are you using in 2024?
Why are there so many ETL tools when we have SQL and Python?
* Based on unique clicks.
** Find last week's issue #537 here.
Whenever you're ready, 2 ways we can help:
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~61,000 subscribers by sponsoring this newsletter. 35-45% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
You're currently a free subscriber to Data Science Weekly Newsletter. For the full experience, upgrade your subscription.
![]()
![]()
Older messages
Data Science Weekly - Issue 537
Friday, March 8, 2024
Curated news, articles and jobs related to Data Science, AI, & Machine Learning ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Data Science Weekly - Issue 536
Friday, March 1, 2024
Curated news, articles and jobs related to Data Science, AI, & Machine Learning ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Data Science Weekly - Issue 535
Friday, February 23, 2024
Curated news, articles and jobs related to Data Science, AI, & Machine Learning ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Data Science Weekly - Issue 534
Monday, February 19, 2024
Curated news, articles and jobs related to Data Science, AI, & Machine Learning ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Data Science Weekly - Issue 533
Friday, February 9, 2024
Curated news, articles and jobs related to Data Science, AI, & Machine Learning
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your