📝 Guest Post: Yandex develops and open-sources YaFSDP — a tool for faster LLM training and optimized GPU consumpt…
Was this email forwarded to you? Sign up here A few weeks ago, Yandex open-sourced the YaFSDP method — a new tool that is designed to dramatically speed up the training of large language models. In this article, Mikhail Khrushchev, the leader of the YandexGPT pre-training team will talk about how you can organize LLM training on a cluster and what issues may arise. He'll also look at alternative training methods like ZeRO and FSDP and explain how YaFSDP differs from them. Problems with Training on Multiple GPUsWhat are the challenges of distributed LLM training on a cluster with multiple GPUs? To answer this question, let's first consider training on a single GPU:
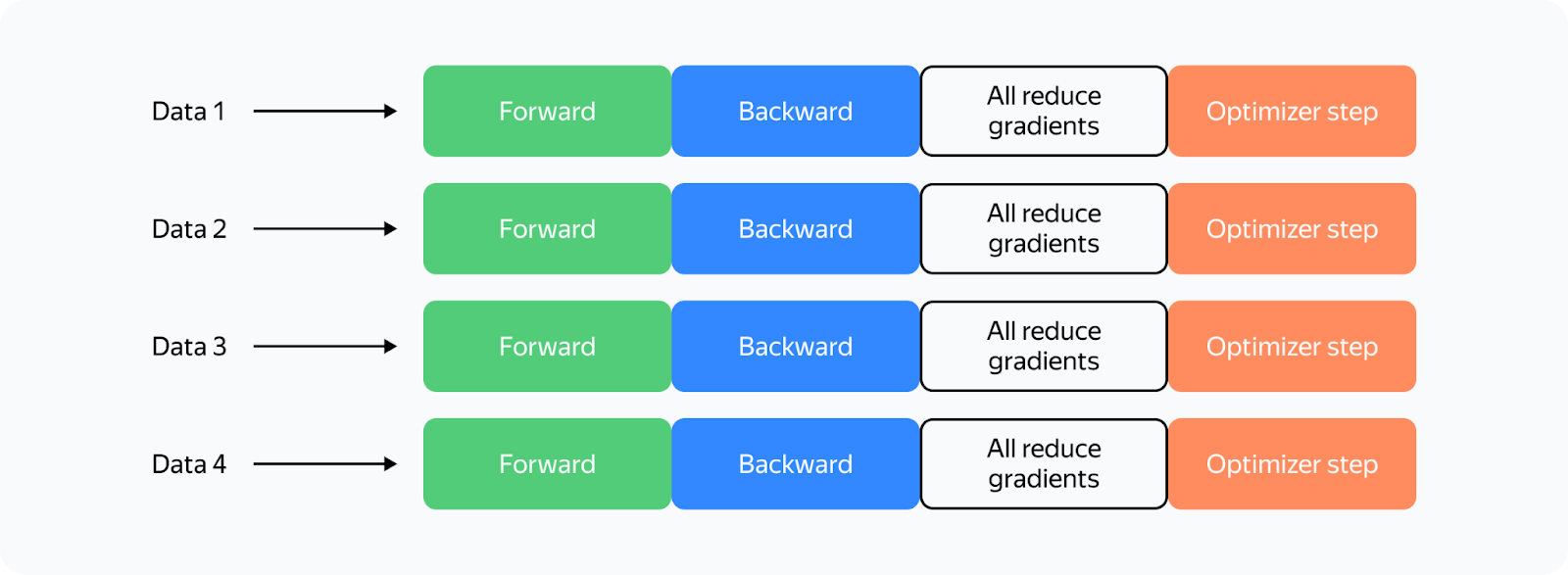
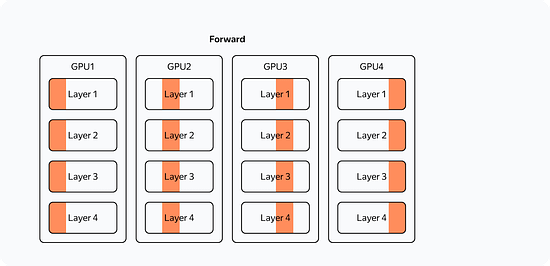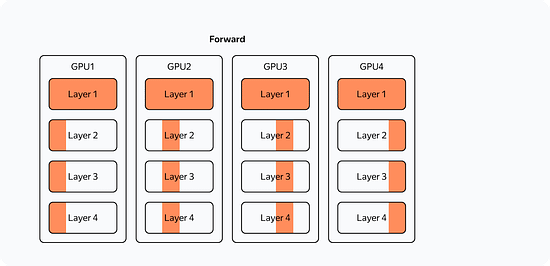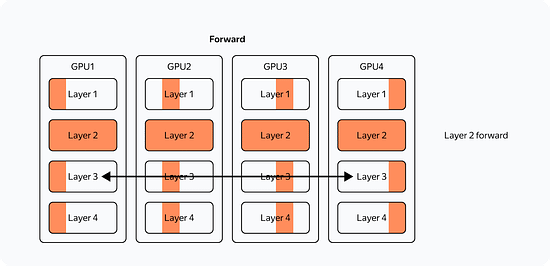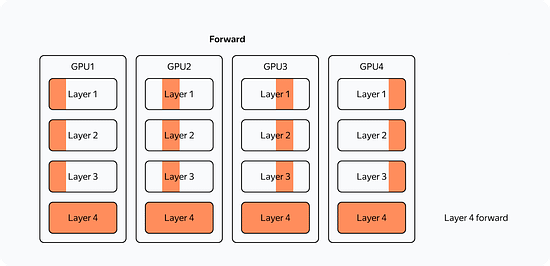
So what changes when we use multiple GPUs? Let's look at the most straightforward implementation of distributed training on four GPUs (Distributed Data Parallelism):
What's changed? Now:
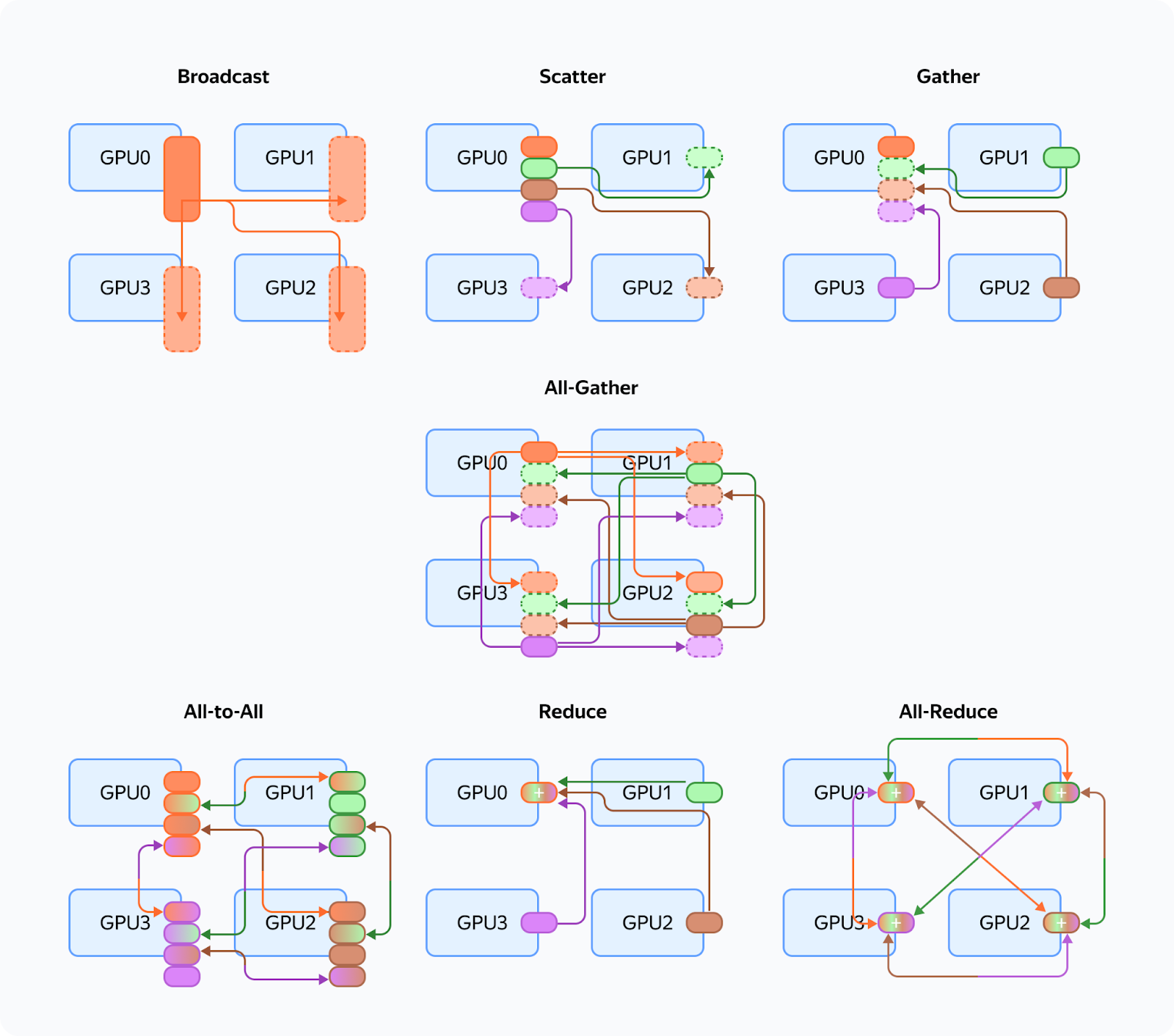
Let's recall the different communication operations (they are referenced throughout the article):
These are the issues we encounter with those communications:
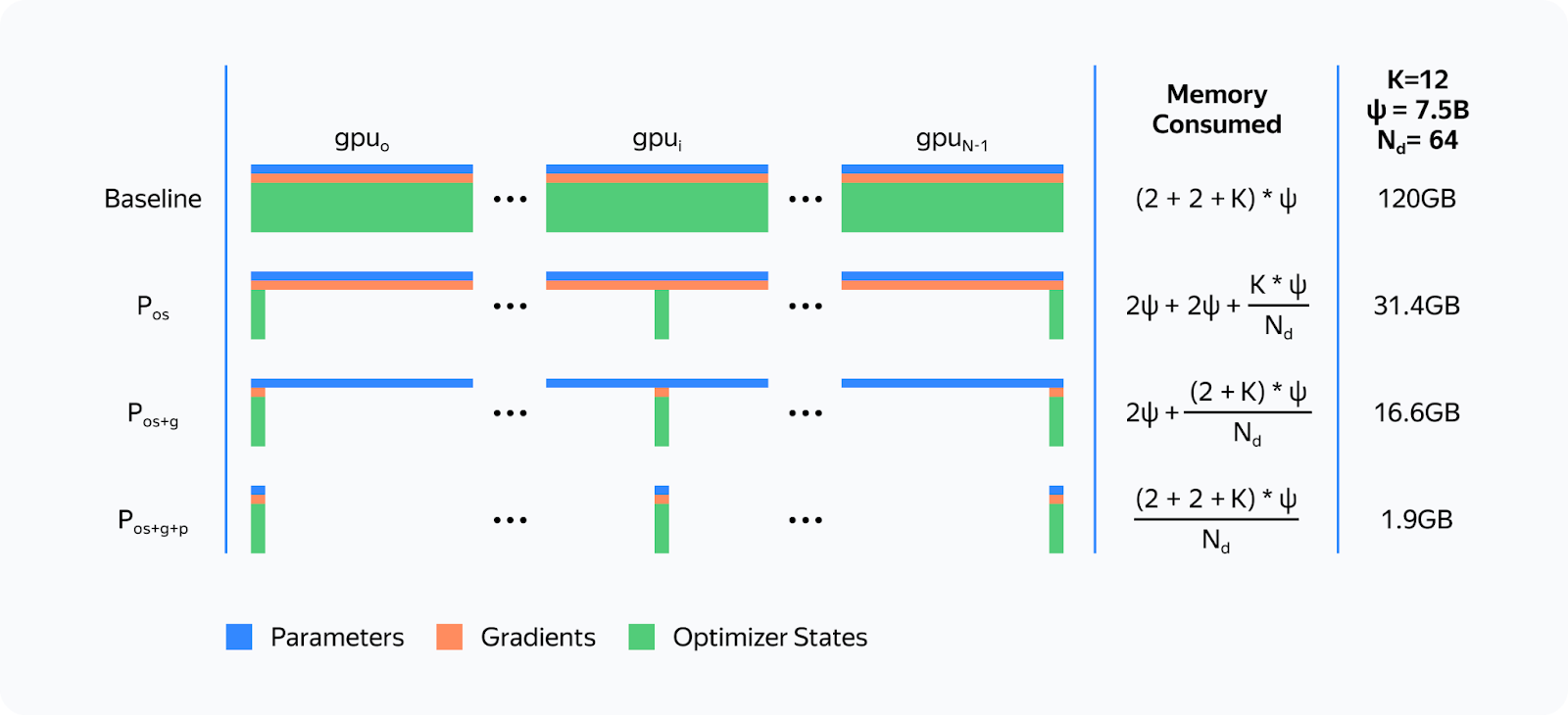
This means the redundant memory load is so massive we can't even fit a relatively small model into GPU memory, and our training process is severely slowed down due to all these additional operations. Is there a way to solve these issues? Yes, there are some solutions. Among them, we distinguish a group of Data Parallelism methods that allow full sharding of weights, gradients, and optimizer states. There are three such methods available for Torch: ZeRO, FSDP, and Yandex's YaFSDP. ZeROIn 2019, Microsoft's DeepSpeed development team published the article ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. The researchers introduced a new memory optimization solution, Zero Redundancy Optimizer (ZeRO), capable of fully partitioning weights, gradients, and optimizer states across all GPUs:
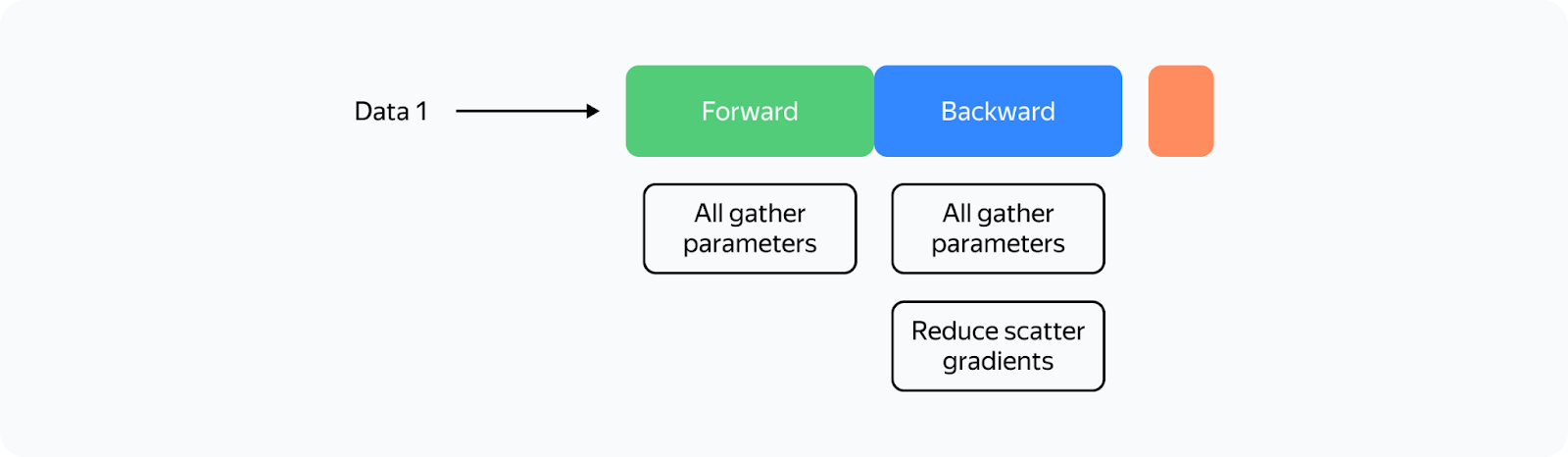
The proposed partitioning is only virtual. During the forward and backward passes, the model processes all parameters as if the data hasn't been partitioned. The approach that makes this possible is asynchronous gathering of parameters. Here's how ZeRO is implemented in the DeepSpeed library when training on the N number of GPUs:
Here's how the forward pass would work in ZeRO if we had only one parameter tensor per layer:
The training scheme for a single GPU would look like this:
From the diagram, you can see that:
The ZeRO concept implemented in DeepSpeed accelerated the training process for many LLMs, significantly optimizing memory consumption. However, there are some downsides as well:
A peculiar principle applies to all collective operations in the NCCL: the less data sent at a time, the less efficient the communications. Suppose we have N GPUs. Then for all_gather operations, we'll be able to send no more than 1/N of the total number of parameters at a time. When N is increased, communication efficiency drops. In DeepSpeed, we run all_gather and reduce_scatter operations for each parameter tensor. In Llama 70B, the regular size of a parameter tensor is 8192 × 8192. So when training on 1024 maps, we can't send more than 128 KB at a time, which means network utilization is ineffective.
As a result, the profile looks something like this (stream 7 represents computations, stream 24 is communications):
Evidently, at increased cluster sizes, DeepSpeed tended to significantly slow down the training process. Is there a better strategy then? In fact, there is one. The FSDP EraThe Fully Sharded Data Parallelism (FSDP), which now comes built-in with Torch, enjoys active support and is popular with developers. What's so great about this new approach? Here are the advantages:
Based on an illustration from the FSDP documentation
Despite all these advantages, there are also issues that we faced:
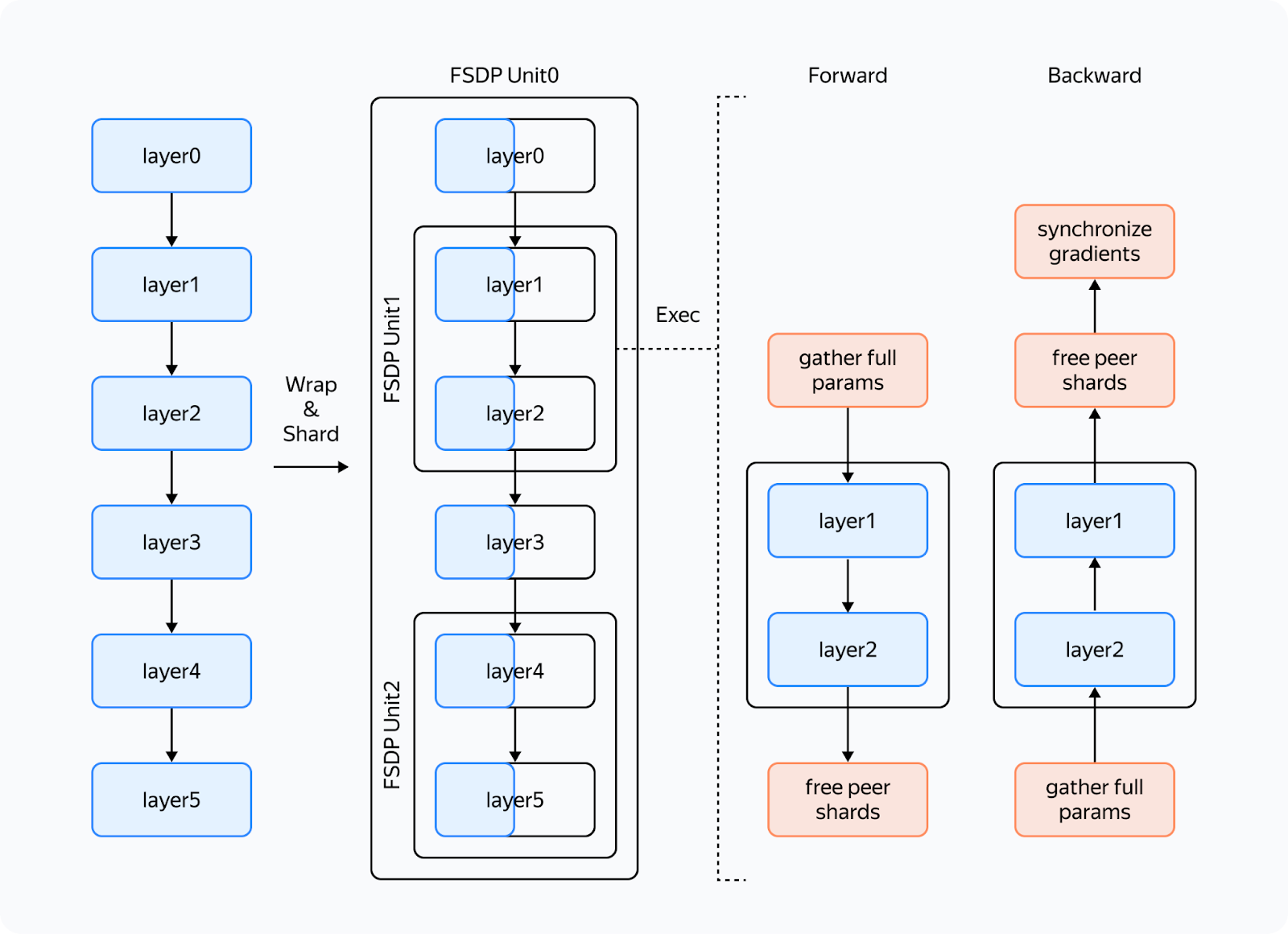
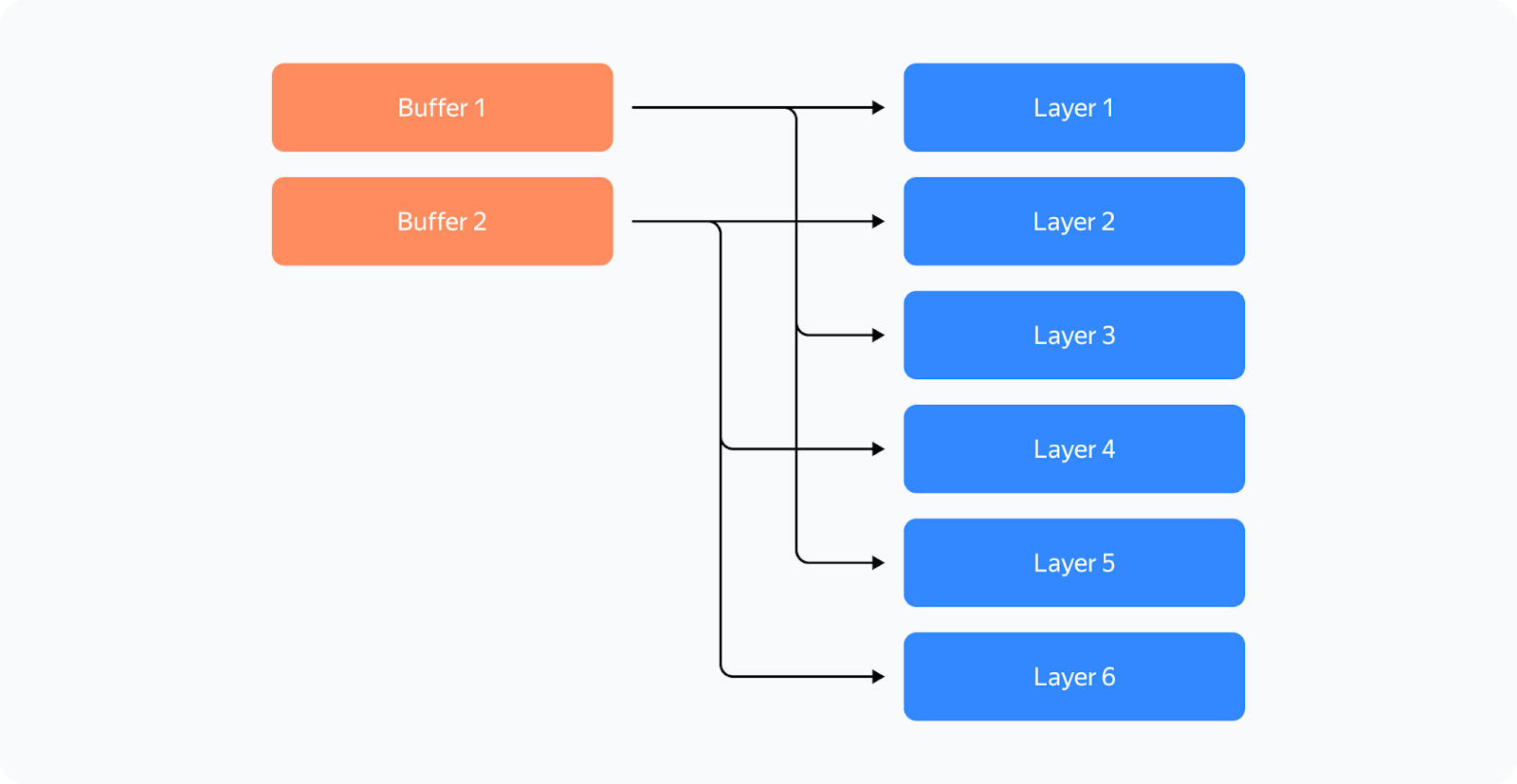
The first line here is the computation stream, and the other lines represent communication streams. We'll talk about what streams are a little later. So what's happening in the profile? Before the reduce_scatter operation (blue), there are many preparatory computations (small operations under the communications). The small computations run in parallel with the main computation stream, severely slowing down communications. This results in large gaps between communications, and consequently, the same gaps occur in the computation stream. We tried to overcome these issues, and the solution we've come up with is the YaFSDP method. YaFSDPIn this part, we'll discuss our development process, delving a bit into how solutions like this can be devised and implemented. There are lots of code references ahead. Keep reading if you want to learn about advanced ways to use Torch. So the goal we set before ourselves was to ensure that memory consumption is optimized and nothing slows down communications. Why Save Memory?That's a great question. Let's see what consumes memory during training: — Weights, gradients, and optimizer states all depend on the number of processes and the amount of memory consumed tends to near zero as the number of processes increases. It turns out that activations are the only thing taking up memory. And that's no mistake! For Llama 2 70B with a batch of 8192 tokens and Flash 2, activation storage takes over 110 GB (the number can be significantly reduced, but this is a whole different story). Activation checkpointing can seriously reduce memory load: for forward passes, we only store activations between transformer blocks, and for backward passes, we recompute them. This saves a lot of memory: you'll only need 5 GB to store activations. The problem is that the redundant computations take up 25% of the entire training time. That's why it makes sense to free up memory to avoid activation checkpointing for as many layers as possible. In addition, if you have some free memory, efficiency of some communications can be improved. BuffersLike FSDP, we decided to shard layers instead of individual parameters — this way, we can maintain efficient communications and avoid duplicate operations. To control memory consumption, we allocated buffers for all required data in advance because we didn't want the Torch allocator to manage the process. Here's how it works: two buffers are allocated for storing intermediate weights and gradients. Each odd layer uses the first buffer, and each even layer uses the second buffer.
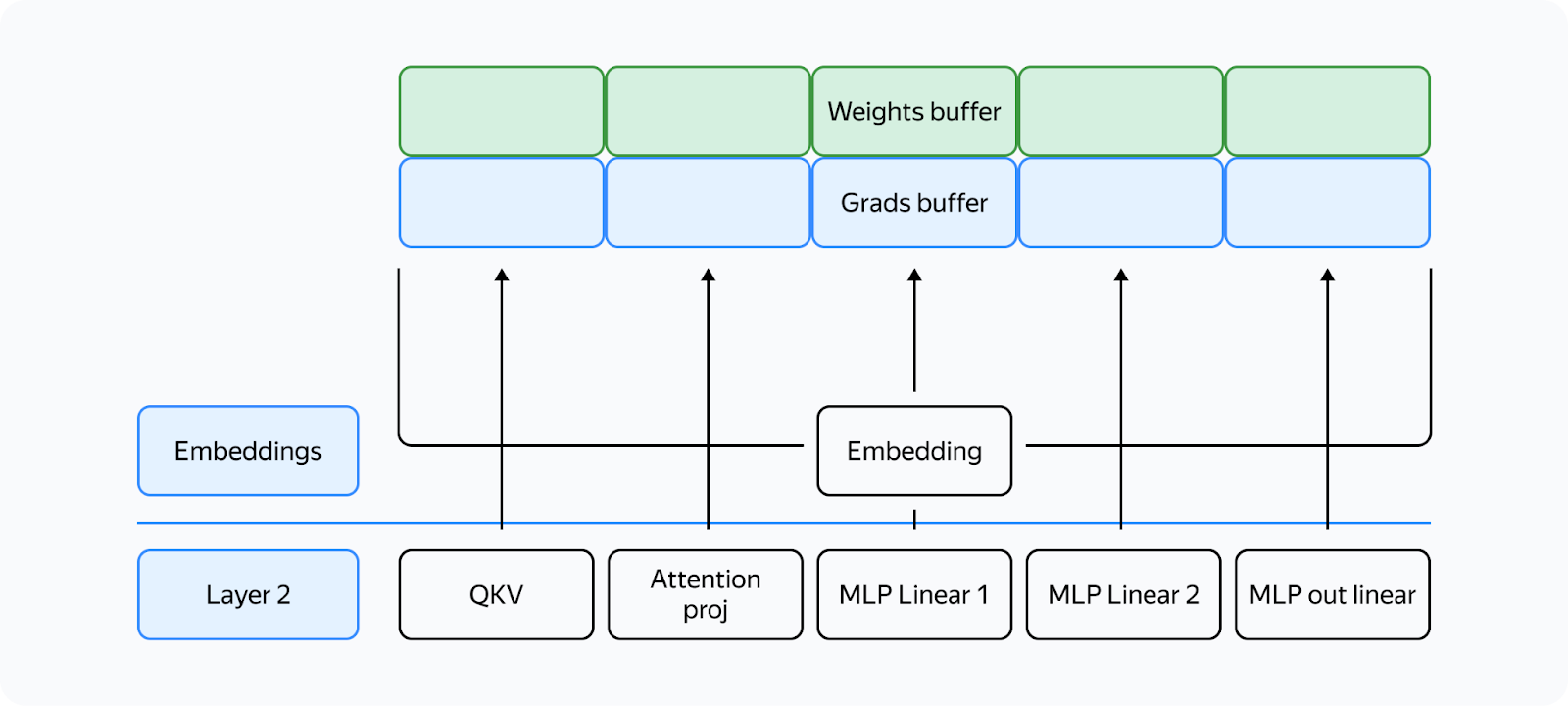
This way, the weights from different layers are stored in the same memory. If the layers have the same structure, they'll always be identical! What's important is to ensure that when you need layer X, the buffer has the weights for layer X. All parameters will be stored in the corresponding memory chunk in the buffer:
Other than that, the new method is similar to FSDP. Here's what we'll need:
Now we need to set up communications so that:
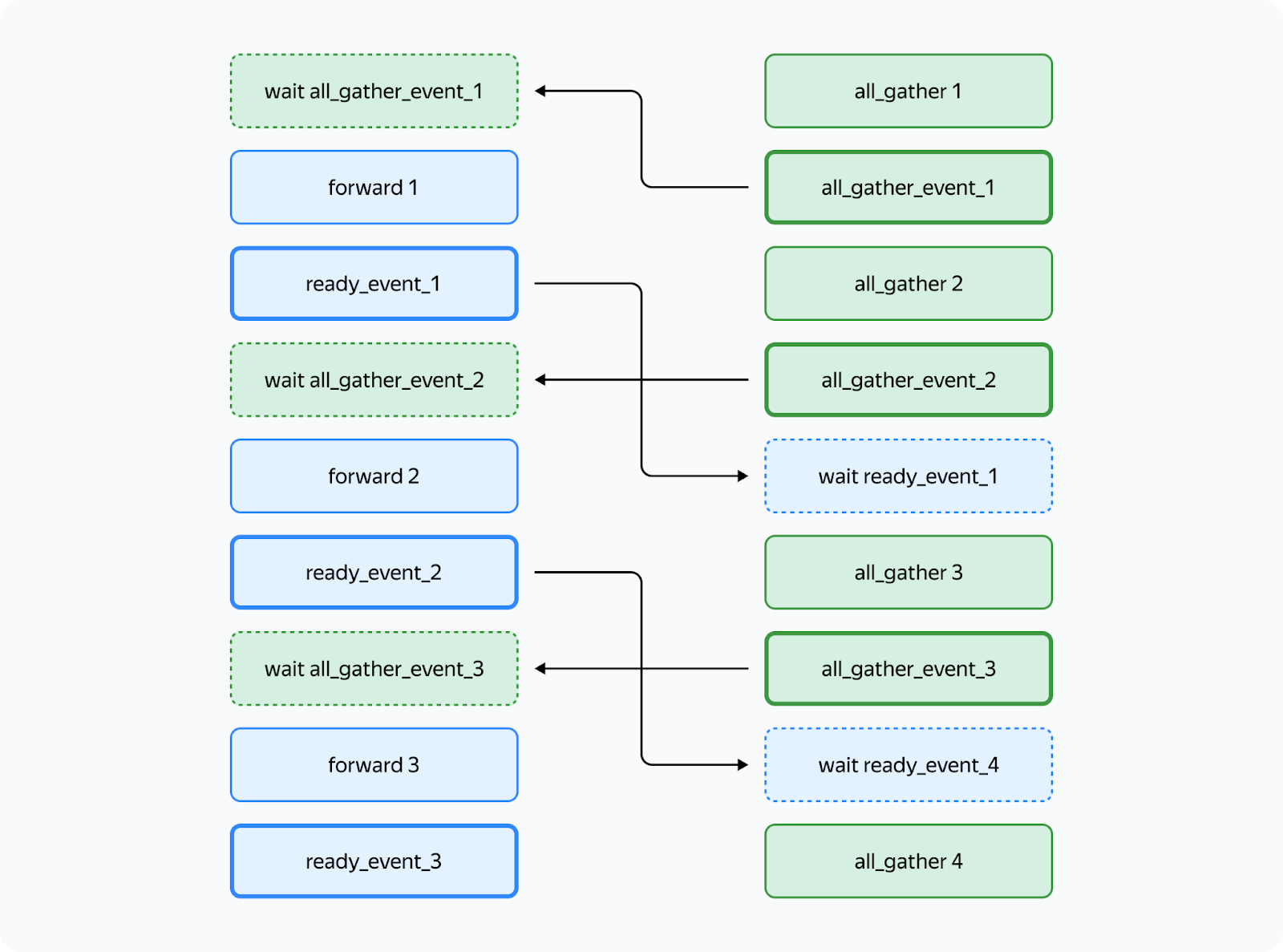
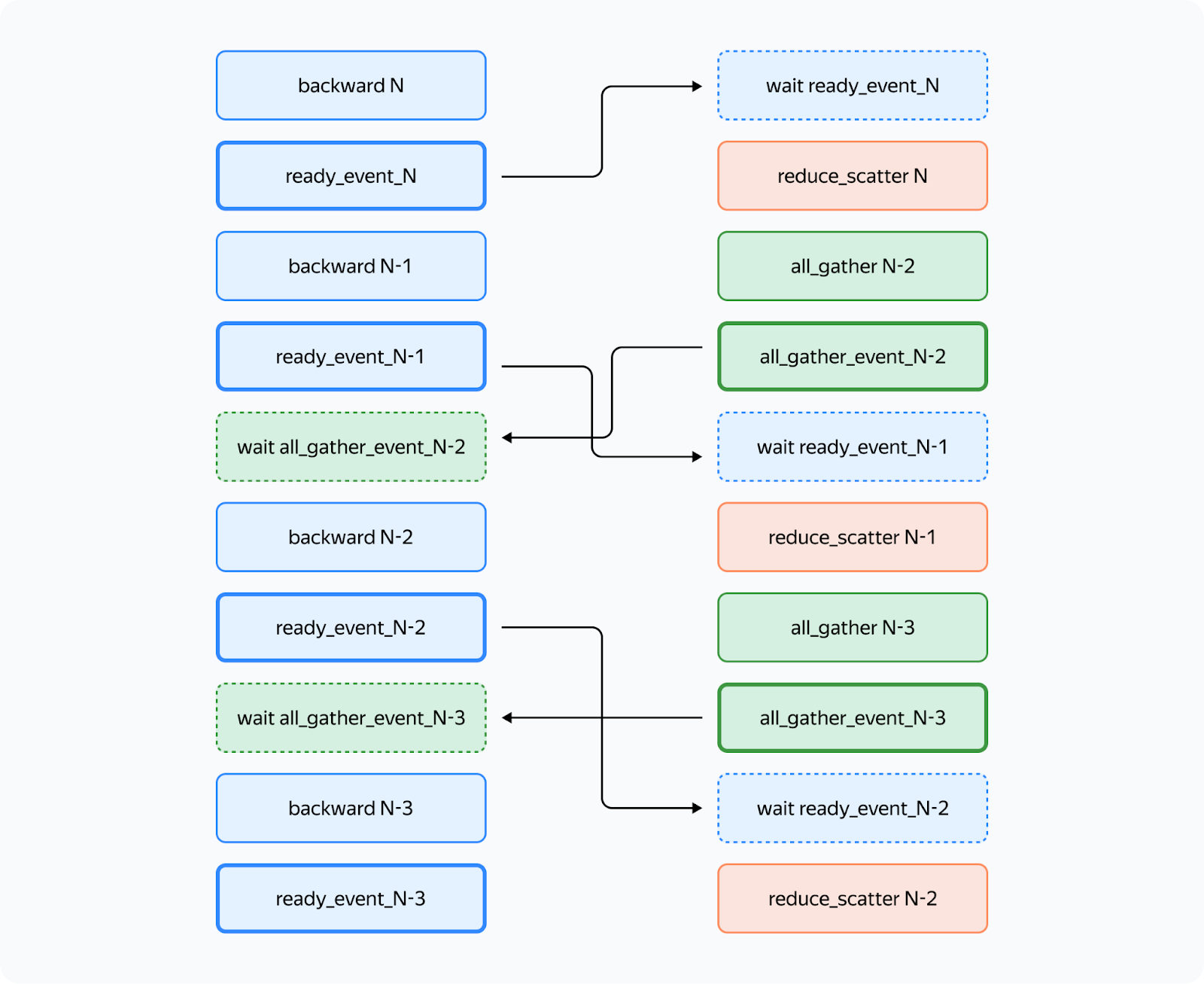
How do we achieve this setup? Working with Streams You can use CUDA streams to facilitate concurrent computations and communications. How is the interaction between CPU and GPU organized in Torch and other frameworks? Kernels (functions executed on the GPU) are loaded from the CPU to the GPU in the order of execution. To avoid downtime due to the CPU, the kernels are loaded ahead of the computations and are executed asynchronously. Within a single stream, kernels are always executed in the order in which they were loaded to the CPU. If we want them to run in parallel, we need to load them to different streams. Note that if kernels in different streams use the same resources, they may fail to run in parallel (remember the "give-way effect" mentioned above) or their executions may be very slow. To facilitate communication between streams, you can use the "event" primitive (event = torch.cuda.Event() in Torch). We can put an event into a stream (event.record(stream)), and then it'll be appended to the end of the stream like a microkernel. We can wait for this event in another stream (event.wait(another_stream)), and then this stream will pause until the first stream reaches the event. We only need two streams to implement this: a computation stream and a communication stream. This is how you can set up the execution to ensure that both conditions 1 and 2 (described above) are met:
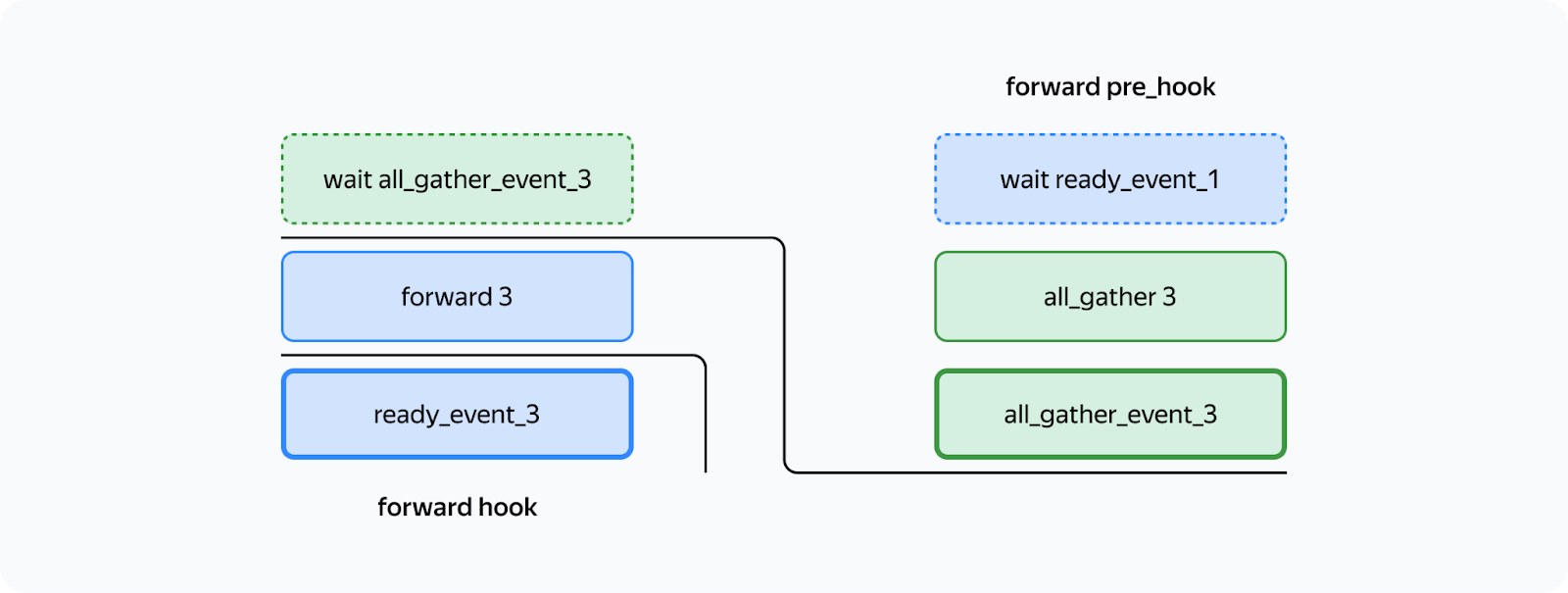
In the diagram, bold lines mark event.record() and dotted lines are used for event.wait(). As you can see, the forward pass on the third layer doesn't start until the all_gather operation on that layer is completed (condition 1). Likewise, the all_gather operation on the third layer won't start until the forward pass on the first layer that uses the same buffer is completed (condition 2). Since there are no cycles in this scheme, deadlock is impossible. How can we implement this in Torch? You can use forward_pre_hook, code on the CPU executed before the forward pass, as well as forward_hood, which is executed after the pass:
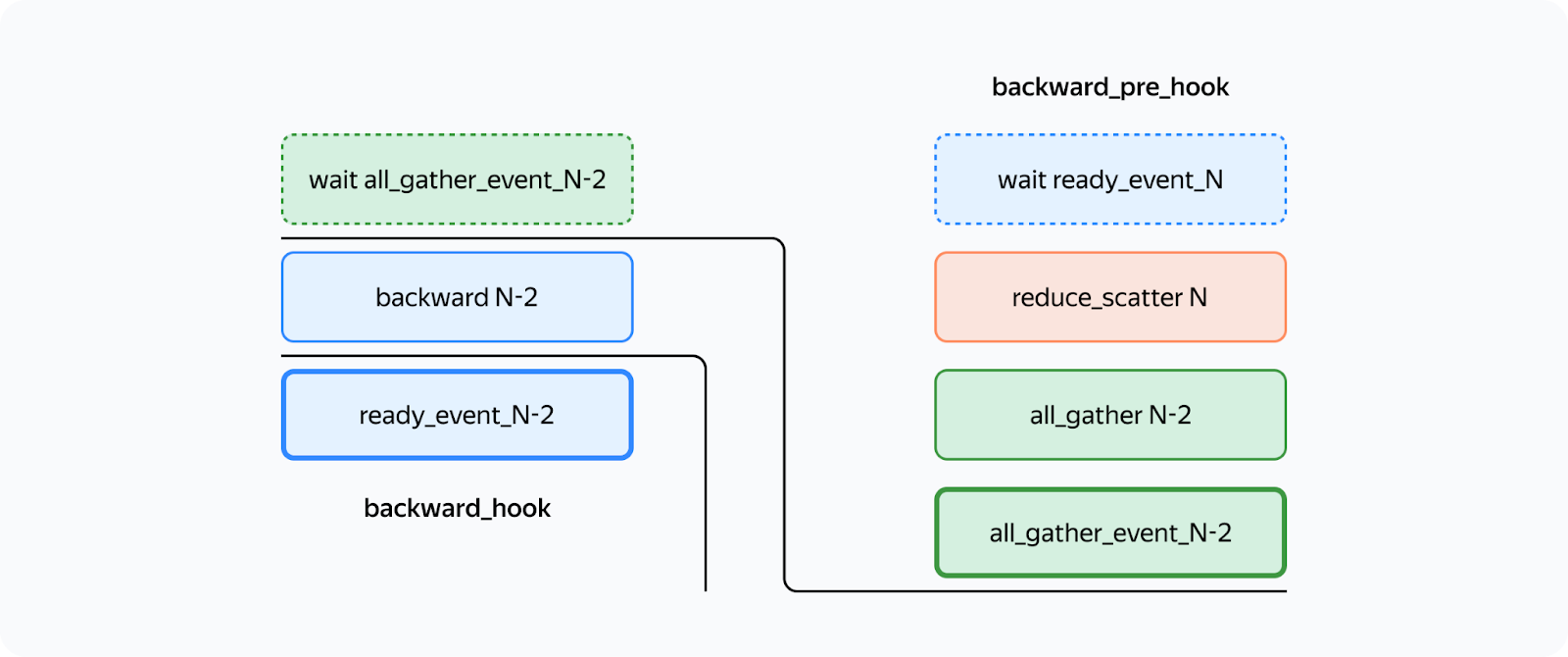
This way, all the preliminary operations are performed in forward_pre_hook. For more information about hooks, see the documentation. What's different for the backward pass? Here, we'll need to average gradients among processes:
We could try using backward_hook and backward_pre_hook in the same way we used forward_hook and forward_pre_hook:
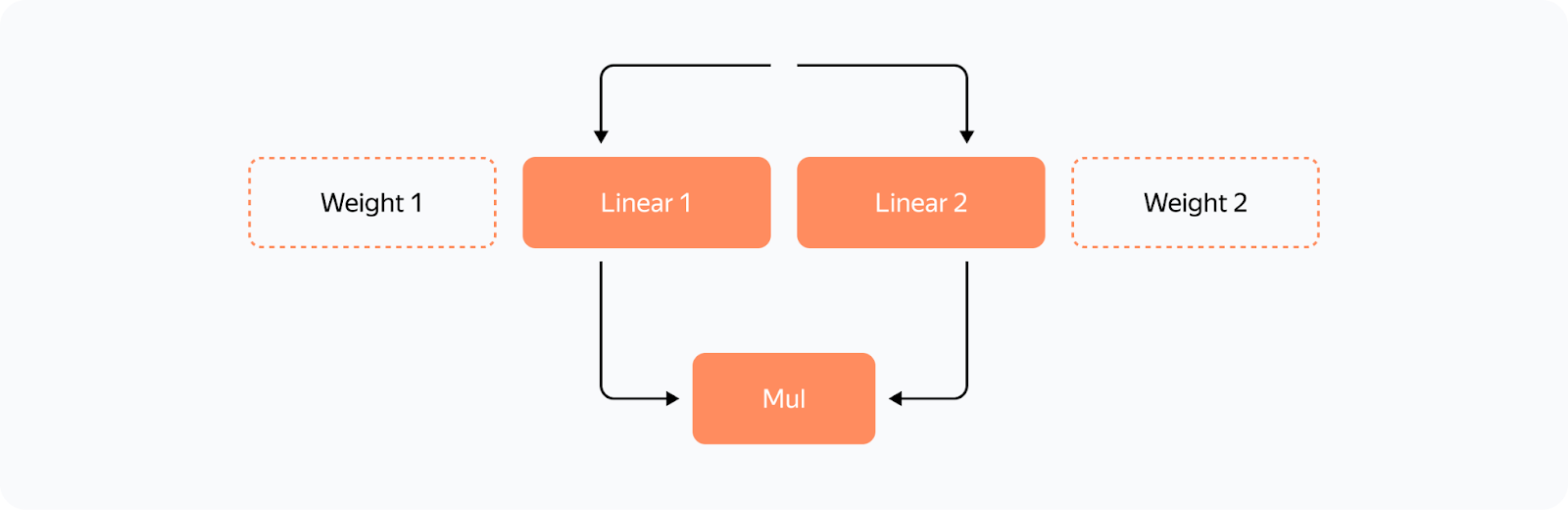
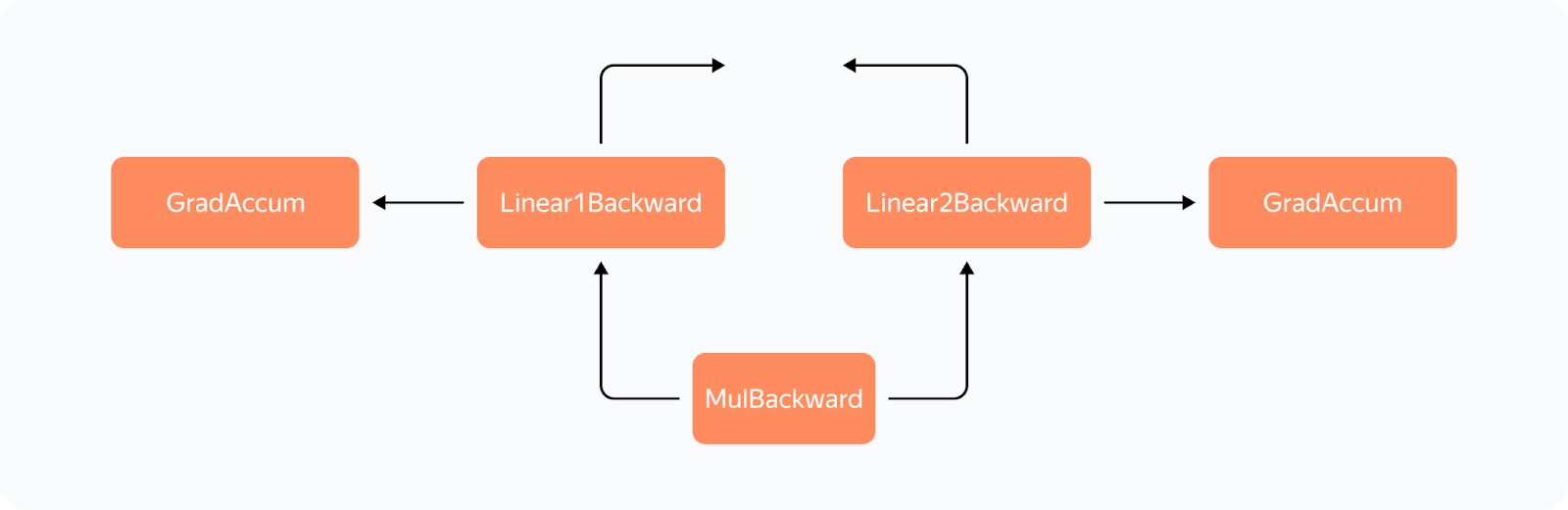
But there's a catch: while backward_pre_hook works exactly as anticipated, backward_hook may behave unexpectedly: — If the module input tensor has at least one tensor that doesn't pass gradients (for example, the attention mask), backward_hook will run before the backward pass is executed. So we aren't satisfied with the initial implementation of backward_hook and need a more reliable solution. Reliable backward_hook Why isn't backward_hook suitable? Let's take a look at the gradient computation graph for relatively simple operations:
We apply two independent linear layers with Weight 1 and Weight 2 to the input and multiply their outputs. The gradient computation graph will look like this:
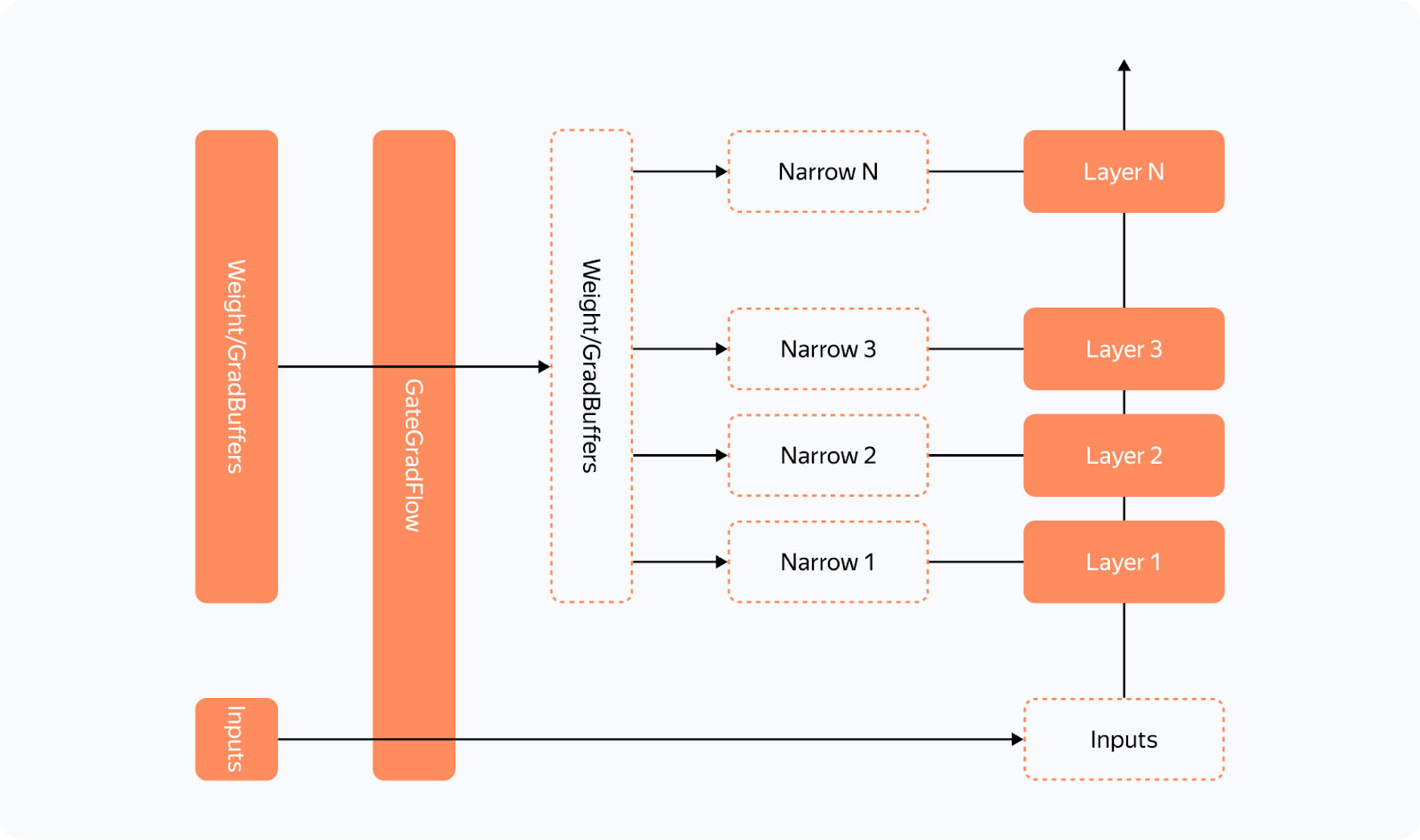
We can see that all operations have their *Backward nodes in this graph. For all weights in the graph, there's a GradAccum node where the .grad of the parameter is updated. This parameter will then be used by YaFSDP to process the gradient. Something to note here is that GradAccum is in the leaves of this graph. Curiously, Torch doesn't guarantee the order of graph traversal. GradAccum of one of the weights can be executed after the gradient leaves this block. Graph execution in Torch is not deterministic and may vary from iteration to iteration. How do we ensure that the weight gradients are calculated before the backward pass on another layer starts? If we initiate reduce_scatter without making sure this condition is met, it'll only process a part of the calculated gradients. Trying to work out a solution, we came up with the following schema:
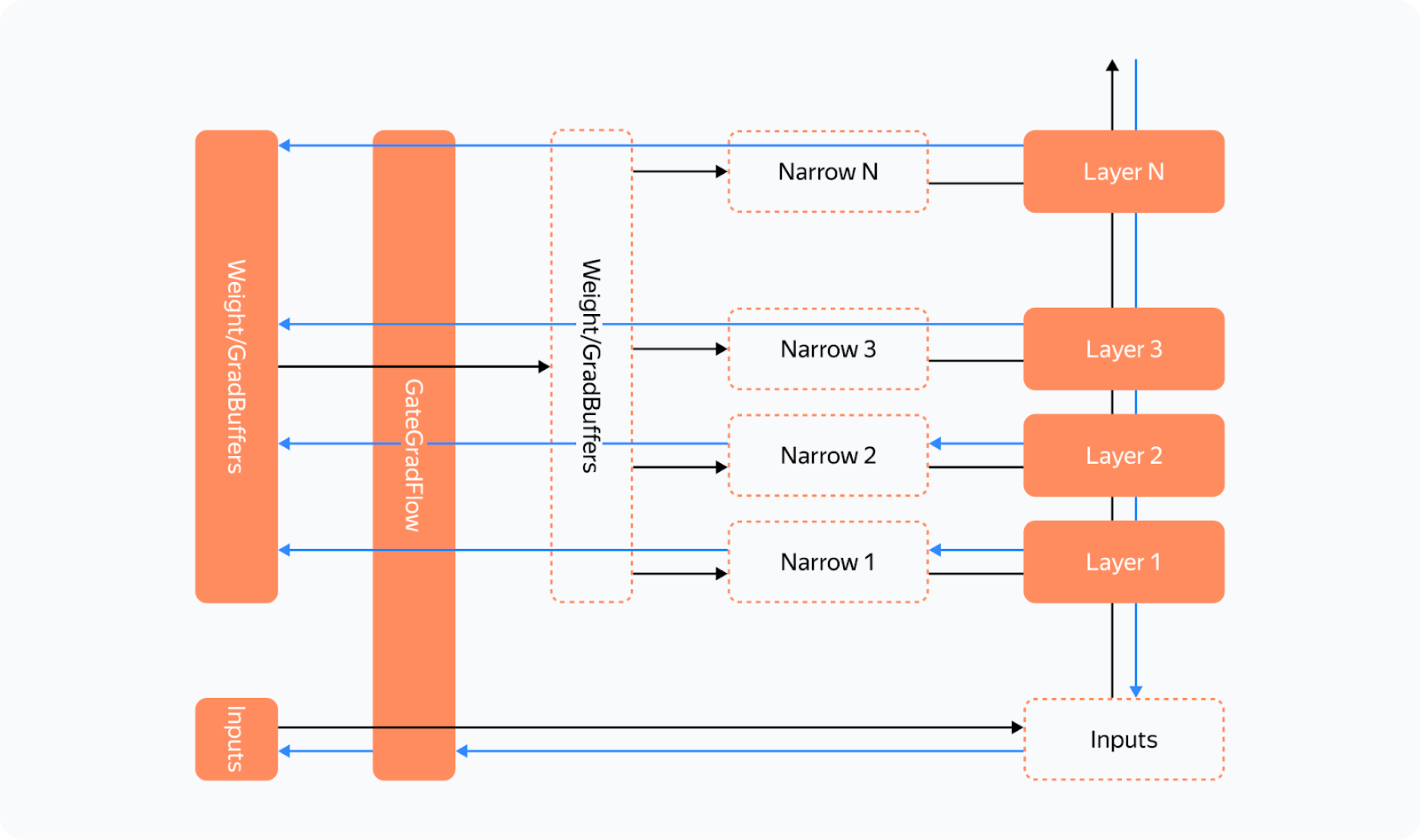
Before each forward pass, the additional steps are carried out: — We pass all inputs and weight buffers through GateGradFlow, a basic torch.autograd.Function that simply passes unchanged inputs and gradients through itself. — In layers, we replace parameters with pseudoparameters stored in the weight buffer memory. To do this, we use our custom Narrow function. What happens on the backward pass:
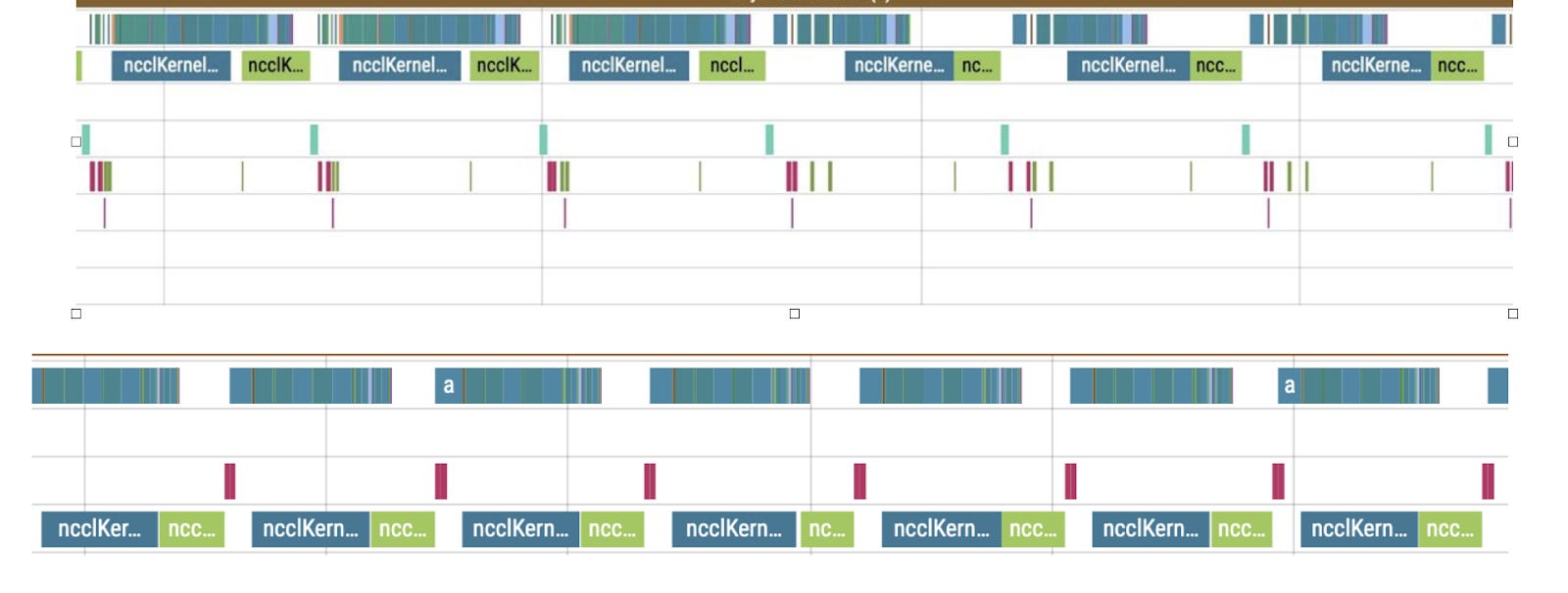
The gradient for parameters can be assigned in two ways: — Normally, we'll assign or add a gradient during the backward Narrow implementation, which is much earlier than when we get to the buffers' GradAccum. With this, we can guarantee that: — All gradients will be written to the gradient buffer before the backward GateGradFlow execution. This means that the most suitable place for the backward_hook call is in the backward GateGradFlow! At that step, all weight gradients have been calculated and written while a backward pass on other layers hasn't yet started. Now we have everything we need for concurrent communications and computations in the backward pass. Overcoming the "Give-Way Effect' The problem of the "give-way effect" is that several computation operations take place in the communication stream before reduce_scatter. These operations include copying gradients to a different buffer, "pre-divide" of gradients to prevent fp16 overflow (rarely used now), and others. Here's what we did: — We added a separate processing for RMSNorm/LayerNorm. Because these should be processed a little differently in the optimizer, it makes sense to put them into a separate group. There aren't many such weights, so we collect them once at the start of an iteration and average the gradients at the very end. This eliminated duplicate operations in the "give-way effect". — Since there's no risk of overflow with reduce_scatter in bf16 or fp32, we replaced "pre-divide" with "post-divide", moving the operation to the very end of the backward pass. As a result, we got rid of the "give-way effect", which greatly reduced the downtime in computations:
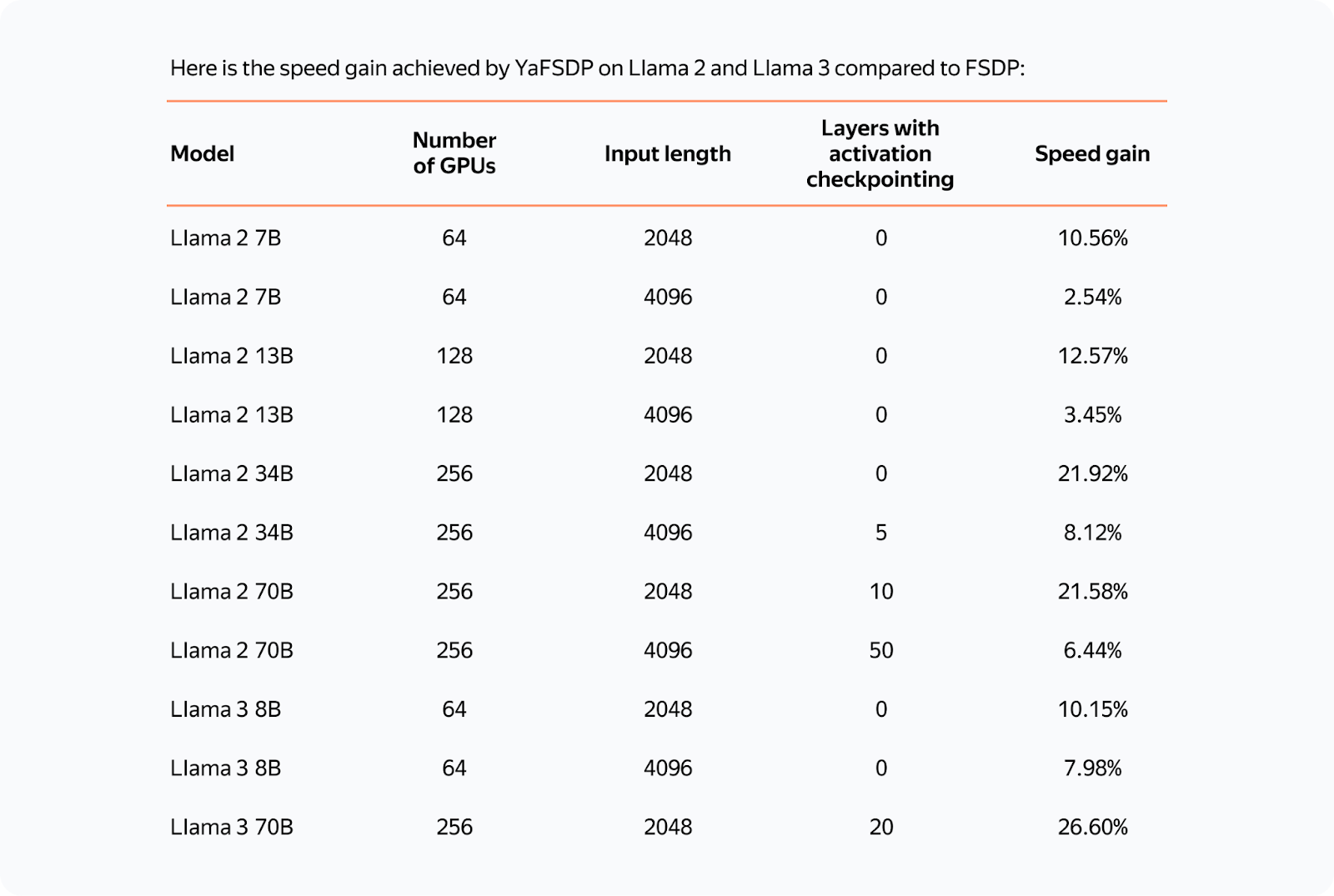
RestrictionsThe YaFSDP method optimizes memory consumption and allows for a significant gain in performance. However, it also has some restrictions: — You can reach peak performance only if the layers are called so that their corresponding buffers alternate. Test Results
The resulting speed gain in small-batch scenarios exceeds 20%, making YaFSDP a useful tool for fine-turning models. In Yandex's pre-trainings, the implementation of YaFSDP along with other memory optimization strategies resulted in a speed gain of 45%. Now that YaFSDP is open-source, you can check it out and tell us what you think! Please share comments about your experience, and we'd be happy to consider possible pull requests. *This post was written by Mikhail Khrushchev, the leader of the YandexGPT pre-training team, and originally published here. We thank Yandex for their insights and ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|





Older messages
The Single-Algorithm AI Chip
Sunday, June 30, 2024
Plus a tremendous activity in funding activity in generative AI startups. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
📝 Guest Post: Designing Prompts for LLM-as-a-Judge Model Evals*
Friday, June 28, 2024
In this guest post, Nikolai Liubimov, CTO of HumanSignal provides helpful resources to get started building LLM-as-a-judge evaluators for AI models. HumanSignal recently launched a suite of tools
Edge 406: Inside OpenAI's Recent Breakthroughs in GPT-4 Interpretability
Thursday, June 27, 2024
A new method helps to extract interpretable concepts from large models like GPT-4. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Edge 407: LLMs with Infininite Context Windows? Short-Term Memory and Autonomous Agents
Tuesday, June 25, 2024
The role of context windows in LLMs ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
📽 [Virtual Talk] Powering millions of real-time rankings at GetYourGuide
Monday, June 24, 2024
Hi there, Curious about how GetYourGuide, a leading online marketplace for travel excursions, delivers millions of personalized rankings daily, adapting to users' preferences in real time? Join us
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your