Using S3 but not the way you expected. S3 as strongly consistent event store.
Welcome to the new week! Hype is strong in our industry, but the most powerful news usually comes surprisingly silent. That’s what happened with the latest AWS S3 update. Such a humble update on introducing new features: Okay, it didn’t go entirely silent. Gunnar Morling did a great write-up showing how you can now conduct a Leader Election With S3 Conditional Writes. That already shows how powerful this can be, and I want to show you today another unexpected use case of that: so building a strongly consistent event store using conditional writes for optimistic concurrency! Before I move on, I promised you that once per month, I’ll write an open article for all subscribers, and this article is like that. There is no paywall today! Still, check articles and webinars from last month; I think they’re worth subscribing to:
If you’d like to try them out, you can use a free month’s trial for the next three days: https://www.architecture-weekly.com/b3b7d64d. S3 as More Than Just StorageLet’s take a moment to appreciate just how far Amazon S3 has come since its debut. Initially, S3 was the place where you dumped your backups, logs, and static files—reliable and cheap but not exactly groundbreaking. Fast-forward to today, S3 has evolved into something far more versatile. It’s not just a storage service anymore; it’s a foundational piece of infrastructure enabling a new wave of distributed applications and services (e.g., Turso, WarpStream, etc.). Over the years, developers have realised that S3 can be used for much more than just file storage. It’s now being used to store database snapshots, as the backbone for event-driven architectures, and as a core component in serverless computing models. S3’s flexibility, scalability, and durability have made it a go-to service for architects looking to build robust, cost-effective systems. Read also: However, as we push S3 into these new roles, we encounter challenges that weren’t part of its original design brief. One of the biggest challenges is managing concurrency—ensuring that multiple processes can read and write data without stepping on each other’s toes. This is where S3’s new conditional writes feature comes in. Why Conditional Writes MatterConditional writes are a game-changer for anyone looking to use S3 in more complex scenarios. At its core, a conditional write is a way to ensure that an update only happens if the data hasn’t changed since you last read it. This might sound simple, but it’s incredibly powerful when you’re dealing with distributed systems, where multiple processes might try to update the same data simultaneously. S3 didn’t have this capability for a long time, which meant you had to rely on external systems—like DynamoDB or even running your own databases—to handle this kind of concurrency control. This added complexity, cost, and operational overhead. With conditional writes, S3 can now manage this itself, making it a more attractive option for a broader range of applications. So, what does this mean in practice? S3 can now serve as the foundation for a new generation of tools and services. Take Turso, for example, a service that uses a custom fork of SQLite to handle multi-region, low-latency data storage. Or Warp Stream, an event streaming service that benefits from the ability to store, process, and replay events in a distributed manner. These tools are pushing the boundaries of what’s possible with cloud storage, and S3’s conditional writes are a key enabler. By allowing developers to implement optimistic concurrency directly in S3, these tools can offer strong consistency guarantees without the need for complex, external coordination mechanisms. Optimistic Concurrency and Conditional Writes: Why It MattersEvery system faces the challenge of concurrency. Imagine you’re managing an order system for an e-commerce platform. Orders come in from multiple sources, and various microservices interact with the same data. For example, one service processes payments while another updates the inventory. Both might attempt to update the same order simultaneously. Without proper concurrency control, race conditions and data corruption can occur. Optimistic concurrency is a strategy where we (optimistically) assume that a scenario will be rare when more than one person tries to edit the same resource (a record). This assumption is correct for most system types. Having that, we can compare the expected record version (or timestamp) with the actual version in the database. If they match, then we perform the update. If the data has changed, the transaction is aborted, and the process can handle the conflict—often by retrying or alerting the user. Read more details in my other articles: Optimistic concurrency and atomic writes ensure that our decisions are based on the latest state. This capability is also one of the most important differences between databases and messaging tooling. How do you implement something similar with Amazon S3, primarily designed for storing files, not managing transactions? Before S3 introduced conditional writes, implementing optimistic concurrency was tricky. S3 didn’t natively support the ability to check whether an object had been modified before writing an update, leaving developers to cobble together various workarounds. These workarounds often involved additional infrastructure, such as using DynamoDB to track versions or implementing custom locking mechanisms, adding complexity and cost. The First Attempt: Using S3 Without Version ControlLet’s start with the most common approach: storing each order as an object in S3 without any version control. For instance, you might store an order with the key order123.json. When a process updates the order, it overwrites the existing order123.json file with the new data (S3 cannot patch or append data to a file. Files in S3 are immutable). If two processes try to update the order at the same time, the last one to finish will overwrite the changes made by the other, leading to potential data loss. This approach clearly lacks the necessary controls to manage concurrency, as it doesn’t prevent overwriting data. Adding Version Numbers to Object NamesTo address this, you might consider adding a version number to the object names, such as order123:001.json, order123:002.json, and so on. This way, each update creates a new version of the order. When a process updates an order, it writes a new object with the following version number, like order123:002.json. While this prevents overwriting the previous version, there’s still no mechanism to ensure that the version being updated is the latest one. Two processes could still generate the same new version number, order123:002.json, leading to a race condition where one update overwrites the other. Why Not Use S3’s Native Versioning?S3 has a built-in versioning feature, where you can enable versioning on a bucket, and S3 will automatically keep track of all versions of an object. However, this doesn’t solve the problem of optimistic concurrency because:
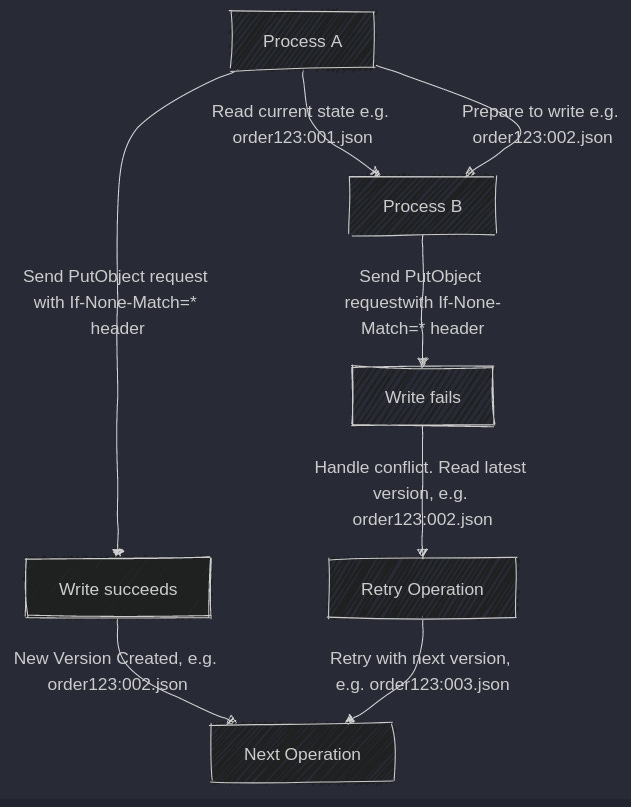
The Solution: Using Conditional Writes with Custom VersioningGiven these limitations, we can use S3’s conditional writes feature to implement a custom versioning strategy that supports optimistic concurrency. Here are the ingredients to make it work: 1. Naming Strategy We’ll use a structured naming convention for our objects, including the version number as part of the object key. For example, an order might be stored as ecommerce/tenantA/orders/12345/001.json. 2. Using `If-None-Match` for Conditional Writes: We use the If-None-Match=”*” header when updating an order. This tells S3 to only proceed with the write operation if an object with the specified key (e.g. order123:002.json) does not exist. 3. Handling Conflicts: If the If-None-Match=”*” condition fails (resulting in a `412 Precondition Failed` response), it means another process has already created that version. The process can then reread the latest version, resolve the conflict, and retry the operation with the next version number. For instance:
The key to consistency is a proper key strategyYeah, it's a lame joke that I’m famous for, but that’s true. When working with S3 to implement optimistic concurrency, we need a structured and predictable file naming convention to manage versions effectively. The naming strategy we’ve chosen is: {streamPrefix}/{streamtType}/{streamId}/{streamVersion} We’re building an event store here. Event stores are (logically) key-value databases; the key is a record, and the value is an ordered list of events. In relational databases, records are called rows; in document databases: documents; in Event Sourcing, they’re called streams.  Here, we’re building an event store in one article! Huh! Let’s break this down:
Stream Version should be gapless and not tied to streams or operation events count. This is important because if two processes tried to append events simultaneously, and if the version was tied to the number of events, they could generate the same version number, leading to data integrity issues. Using a gapless, auto-incremented version number ensures that each update has a unique version. For example, consider two processes trying to append events to the same stream:
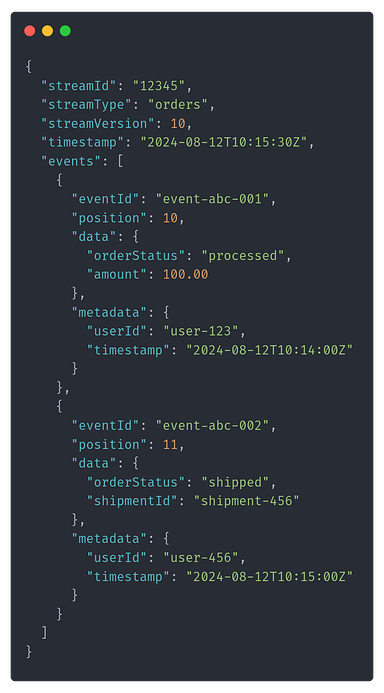
An autoincremented, gapless version based on the previous file name would not allow that, as both would try to append the file name with version 009. Essentially, the stream version is a logical timestamp. The JSON file stored in S3 will contain metadata about the stream and the events. Here’s an example structure:
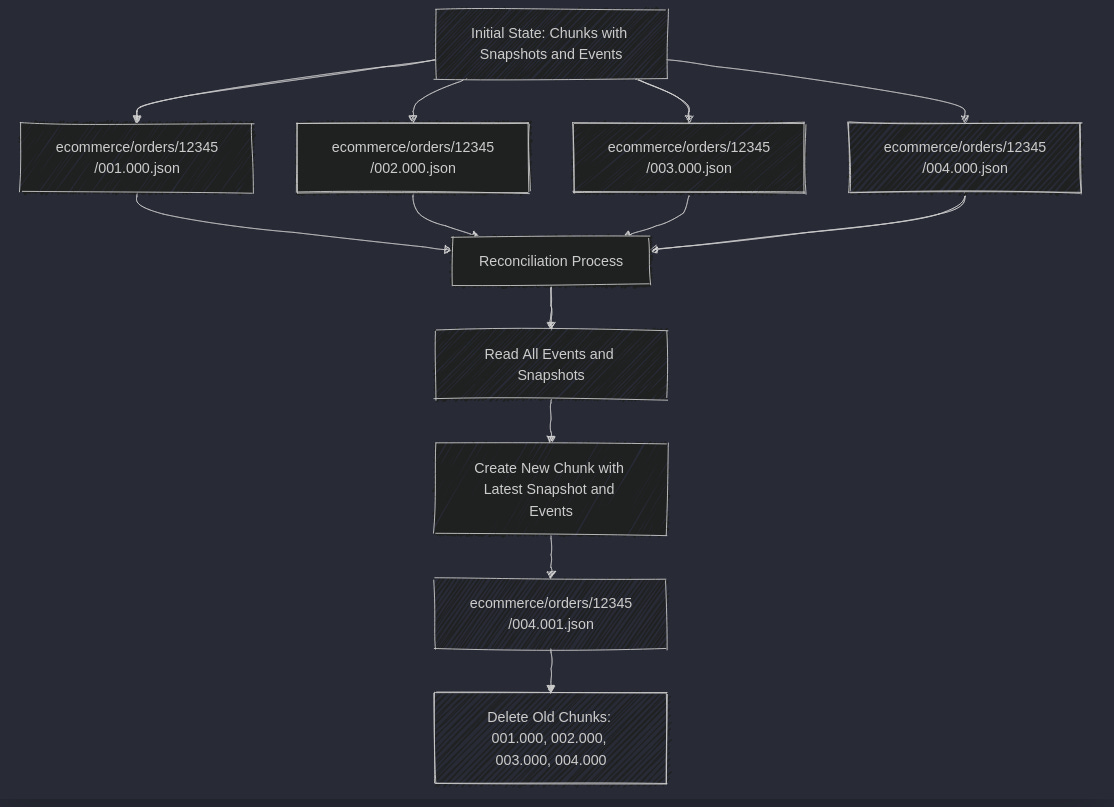
The Write-Ahead Pattern: A Familiar ApproachOur outlined approach is strikingly similar to the write-ahead pattern used in databases. In traditional databases, a write-ahead log (WAL) ensures that any changes to the data are first recorded in a log before they’re actually applied to the database. This ensures that even in the event of a crash or failure, the database can recover by replaying the log and returning the system to a consistent state. In our case, each stream operates similarly. We append new events to a chunk file in S3, with each version of the stream corresponding to a new update. This ensures that our event stream is always consistent, and if something goes wrong, we can trace back through the versions to recover the correct state. However, unlike traditional databases that might use a single log for the entire system, our approach involves multiple logs—one for each stream. This logical grouping allows us to efficiently read and write data per stream, making it scalable across different use cases, like processing orders, payments, or shipments. Read more in What if I told you that Relational Databases are in fact Event Stores? While this approach ensures consistency and helps manage concurrency, it comes with cost considerations that are particularly relevant when using S3 for event sourcing. In a typical event sourcing scenario, every time you want to build the state of an entity (like an order), you need to read all the events in the stream from the beginning to the current state. This means every operation could potentially involve reading all the chunks associated with a stream. And here’s where the S3 costs start to add up: S3 charges you for each GET request. If your stream is divided into multiple chunks, you’ll need to make multiple GET requests to read all the events. While each GET request might not be expensive on its own, the costs can accumulate quickly, especially as your streams grow and you have to read through more and more chunks. Snapshots to the rescue, yuk…Here comes the part that I’m afraid of the most. I spend months explaining not to use snapshots. E.g. through articles: Or in the talk:  TLDR. Snapshots are performance optimisation, a cache. As with each type of cache, they should be used with caution. The idea of a snapshot is to periodically store a full representation of the current state of an entity so that you don’t have to replay all events from the beginning every time you need to rebuild the state. If you’re using a traditional database, this is most often premature optimisation, as events are small, and it doesn’t cost much to read events. Thanks to that, we’re not falling into cache invalidation issues and other mishaps I outlined in linked articles. Still, in our S3-based approach, snapshots can actually be a cost-effective solution. By adding a snapshot to each chunk, we can dramatically reduce the number of GET requests required to read the full state of an entity. Instead of reading all the events from the beginning, we can read the latest chunk containing the most recent snapshot and subsequent events. This way, even if the stream has hundreds or thousands of events, you only need to retrieve the latest chunk to get the current state. Since S3 charges per request rather than per data transfer (assuming your infrastructure, like AWS Lambda or EC2, is also hosted within AWS), combining events and snapshots into a single chunk can lead to significant cost savings. You’re minimising the number of requests while still keeping your data access efficient. Of course, there’s a trade-off to this approach. Each snapshot increases the size of your chunk files, slightly raising your S3 storage costs. If your snapshot becomes invalid—perhaps because of a schema change in your application—you’ll need to read all the events from the beginning of the stream to rebuild the state. This can negate the cost savings we’ve discussed, so managing this carefully is important. One way to mitigate this risk is by versioning your snapshot schema. When you store a snapshot, include the schema version alongside it. Your application can then check if the stored snapshot’s schema version matches the current schema version in your code. If they match, you can safely use the snapshot. If they don’t, you’ll need to replay all events to rebuild the state and store a new chunk with the updated schema in the next chunk. For that our chunk file name could be: {streamPrefix}/{streamtType}/{streamId}/{streamVersion}.{chunkVersion} Having the example series of chunks: After merging those chunks and reconciliation, we’ll get a new file: It’ll contain the rebuild snapshots and possibly all events from the previous chunks, allowing you to delete the old ones and reducing the storage cost.
Following this convention, you can quickly identify the latest chunk using the highest chunk version within the current stream version. This simplifies the process of retrieving and updating your data. Yet, we also need to clear those unused chunks at some point, which means we need to do DELETE operations for each chunk file. We can also optimise the storage costs by benefiting from various storage classes like S3 Intelligent-Tiering and S3 Glacier, which allow us to move automatically not-accessed data to lower-cost storage (and old chunks won’t be accessed). Managing snapshots and handling schema migrations can add complexity to your system. Storing snapshots increases your storage needs, but the reduced number of GET requests often offsets this. There’s no free lunch! Two points for |
![]()
![]()
Older messages
Webinar #21 - Michael Drogalis: Building the product on your own terms
Wednesday, August 28, 2024
Watch now | Did you have a brilliant idea for a startup but were afraid to try it? Or maybe you've built an Open Source tool but couldn't find a way to monetise it?How to be a solopreneur, a
Talk is cheap, show me the numbers! Benchmarking and beyond!
Monday, August 26, 2024
We're did a reality check to what we learned so far. I showed the real study from my projects performance analysis. We verified if connection pooling is indeed such important by giving the real
Architecture Weekly #191 - Is It Production Ready?
Tuesday, August 20, 2024
Why is connection pooling important? How can queuing, backpressure, and single-writer patterns help? In previous posts, we did a learning by-doing. We've built a simple connection pool, added
Architecture Weekly #190 - Queuing, Backpressure, Single Writer and other useful patterns for managing concurrency
Monday, August 12, 2024
Welcome to the new week! ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Architecture Weekly #189 - Mastering Database Connection Pooling
Monday, August 5, 2024
Boom! This is the first Architecture Weekly in the new format. It's a deep dive to database connection pooling. Check to learn how to set it up starting from simple solution and learning how the
You Might Also Like
⚙️ GPT 4.5 - worth the cost?
Friday, February 28, 2025
Plus: Nvidia didn't come to the rescue
ASP.NET Core News - 02/28/2025
Friday, February 28, 2025
View this email in your browser Get ready for this weeks best blog posts about ASP.NET Core! ASP.NET Core updates in .NET 10 Preview 1 — by danroth27 .NET Aspire 9.1 is here with six great new
SWLW #640: The burdens of data, Creating a sense of stability, and more.
Friday, February 28, 2025
Weekly articles & videos about people, culture and leadership: everything you need to design the org that makes the product. A weekly newsletter by Oren Ellenbogen with the best content I found
12,000+ API Keys and Passwords Found in Public Datasets Used for LLM Training
Friday, February 28, 2025
THN Daily Updates Newsletter cover ⚡ LIVE WEBINAR ➟ The Anatomy of a Ransomware Attack Watch a Live Ransomware Attack Demo, Uncover Hacker Tactics and Learn to Defend Download Now Sponsored LATEST NEWS
The Sequence Research #500: Making Small Models Great Achieve GPT-o1 Levels in Math Reasoning with Microsoft rStar…
Friday, February 28, 2025
The new method represents an important evolution of reasoning for SLMs. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
🎧 The Perfect AirPods Alternative for Android — Features I Wish Netflix Would Copy From YouTube
Friday, February 28, 2025
Also: Are Ryobi Power Tools at Home Depot Worth Buying? and More! How-To Geek Logo February 28, 2025 Did You Know The crew of Apollo 11 took two tiny pieces of the Wright "Kitty Hawk" Flyer,
Meta Is Unbundling... Again
Friday, February 28, 2025
The strategy behind the stand-alone apps for Reels and Meta AI... Meta Is Unbundling... Again The strategy behind the stand-alone apps for Reels and Meta AI... By MG Siegler • 28 Feb 2025 View in
📧 Did you watch the FREE chapter of Pragmatic REST APIs?
Friday, February 28, 2025
Hey, it's Milan. 👋 The weekend is almost upon us. So, if you're up for some quality learning, consider watching the free chapter of Pragmatic REST APIs. Scroll down to the curriculum or click
Data Science Weekly - Issue 588
Thursday, February 27, 2025
Curated news, articles and jobs related to Data Science, AI, & Machine Learning ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
💎 Issue 458 - Why Ruby on Rails still matters
Thursday, February 27, 2025
This week's Awesome Ruby Newsletter Read this email on the Web The Awesome Ruby Newsletter Issue » 458 Release Date Feb 27, 2025 Your weekly report of the most popular Ruby news, articles and