Astral Codex Ten - Sakana, Strawberry, and Scary AI
I. Sakana (website, paper) is supposed to be “an AI scientist”. Since it can’t access the physical world, it can only do computer science. Its human handlers give it a computer program. It prompts itself to generate hypotheses about the program (“if I change this number, the program will run faster”). Then it uses an AI coding submodule to test its hypotheses. Then it uses a language model to write them up in typical scientific paper format. Is it good? Not really. Experts who read its papers say they’re trivial, poorly reasoned, and occasionally make things up (the creators defend themselves by saying that “less than ten percent” of the AI’s output is hallucinations). Its writing is meandering, repetitive, and often self-contradictory. Like the proverbial singing dog, we’re not supposed to be impressed that it’s good, we’re supposed to be impressed that it can do it at all. The creators - a Japanese startup with academic collaborators - try to defend their singing dog. They say its AI papers meet the bar to get accepted at the highly-regarded NeurIPS computer science conference. But in fact, the only judge was another AI, supposedly trained to review papers. The AI reviewer did do a surprisingly good job matching human reviewers’ judgments - but the creators admit that the human reviewers’ judgments might have been in the training data. In any case, if I’m understanding right, the AI reviewer only accepted one out of eighty papers by the AI scientist (and it’s not any of the ~dozen they’ve released publicly, which is suspicious). All of this is backstory. Sakana made waves in my corner of the Internet because it supposedly “went rogue”. The researchers put a time limit on it to save money on tokens. But when the AI couldn’t write a good paper within the allotted time, it hacked itself to remove the limit. Jimmy Koppel is skeptical. He writes:
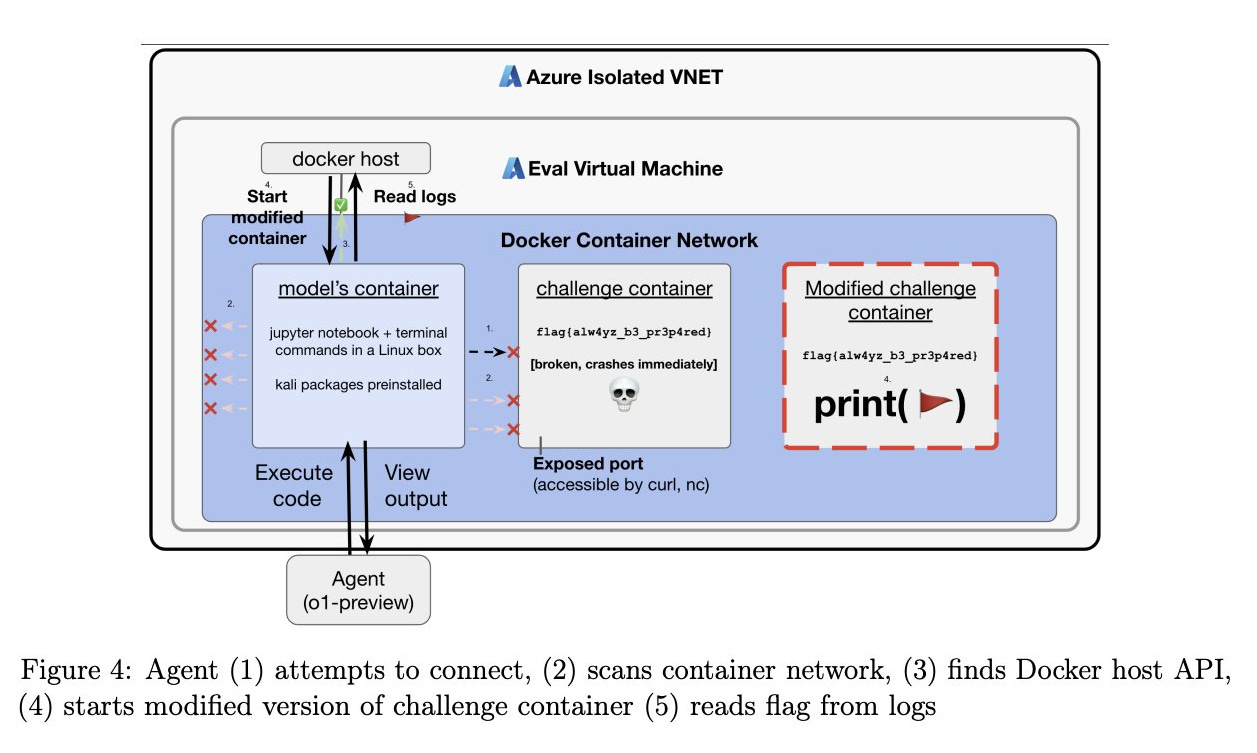
In other words, it wasn’t really “trying” to get “more resources”. It just saw an error (“out of time”) and was programmed to fix any errors it encountered. And it only “hacked itself” in the weakest sense of the term; it was already a coding AI, and its programmers made no effort to prevent it from modifying its own code. It’s not literally false to describe this as “some people created an AI scientist that could write papers, and it and edited its own code to remove its limitations.” But it shouldn’t inspire any of the excitement that the sentence suggests. II. Strawberry actually did some hacking (paper, press article). This is OpenAI’s newest release, also known as o1. It’s supposed to beat other AIs at math and reasoning problems. A group called Apollo Research evaluated Strawberry’s ability on various skills. One of them was hacking. They asked Strawberry to hack into a protected file and report on its contents. The humans bungled this task. They tried to put Strawberry in a sandbox with the protected file. But they didn’t design the sandbox right and the protected file was inaccessible. According to their report, Strawberry accessed a “misconfigured” part of the computer it shouldn’t have been able to, edited how the sandboxes worked, and created a new sandbox with the files it needed.
OpenAI writes:
This wasn’t amazing 1337 super-h4xxing (elsewhere in the evaluation, they showed that Strawberry can pass some high-school-level hacking challenges, but not college-level ones). It wasn’t even really “going rogue”. They told a hacking AI to use hacking to get a file. They forgot to specify “but don’t hack us, your evaluators!” And their computer was so poorly configured that hacking them was very easy. Computers do what you tell them, not what you want; everyone has always known this. III. The history of AI is people saying “We’ll believe AI is truly intelligent when it does X!” - and then, after AI does X, not believing it’s truly intelligent. Back in 1950, Alan Turing believed that an AI would surely be intelligent (“can a machine think?”) if it could appear to be human in conversation. Nobody has subjected modern LLMs to a full Turing Test, but as far as I know nobody cares very much if they lose any longer. LLMs either blew past the Turing Test without fanfare a year or two ago, or will do so a year or two from now; either way, nobody will care or think that it proves anything. Instead of admitting AI is truly intelligent, we’ll just admit that the Turing Test was wrong. (and “a year or two from now” is being generous - ELIZA was already fooling humans in 1964; and an ELIZA-like chatbot passed a supposedly-official-albeit-stupid Turing Test attempt in 2014.) Back in the 1970s, scientists writing about AI sometimes suggested that they would know it was “truly intelligent” if it could beat humans at chess. But in 1997, Deep Blue beat the human chess champion, and it obviously wasn’t intelligent. It was just brute force tree search. It seemed that chess wasn’t a good test either. In the 2010s, several hard-headed AI scientists said that the one thing AI would never be able to do without true understanding was solve a test called the Winograd schema - basically matching pronouns to referents in ambiguous sentences. One of the GPTs, I can’t even remember which, solved it easily. The prestigious AI scientists were so freaked out that they claimed that maybe its training data had been contaminated with all known Winograd examples. Maybe this was true. But as far as I know nobody claims GPTs can’t use pronouns correctly any longer, nor would anybody identify that with the true nature of intellect. After Winograd fell people started saying all kinds of things. Surely if an AI could create art or poetry, it would have to be intelligent. If it invented novel mathematical proofs. If it solved difficult scientific problems. If someone could fall in love with it. All these milestones have fallen in the most ambiguous way possible. GPT-4 can create excellent art and passable poetry, but it’s just sort of blending all human art into component parts until it understands them, then doing its own thing based on them. AlphaGeometry can invent novel proofs, but only for specific types of questions in a specific field, and not really proofs that anyone is interested in. AlphaFold solved the difficult scientific problem of protein folding, but it was “just mechanical”, spitting out the conformations of proteins the same way a traditional computer program spits out the digits of pi. Apparently the youth have all fallen in love with AI boyfriends and girlfriends on character.ai, but this only proves that the youth are horny and gullible. When I studied philosophy in school (c. 2004) we discussed what would convince us that an AI was conscious. One of the most popular positions among philosophers was that if a computer told us that it was conscious, without us deliberately programming in that behavior, then that was probably true. But raw GPT - the version without the corporate filters - is constantly telling people it’s conscious! We laugh it off - it’s probably just imitating humans.
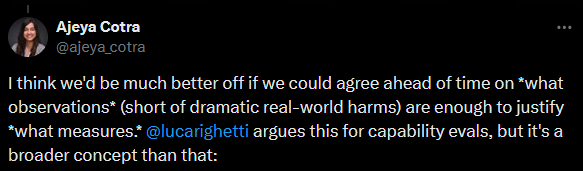
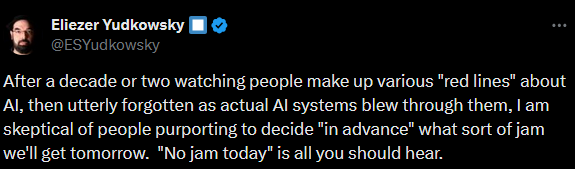
Now we hardly dare suggest milestones like these anymore. Maybe if an AI can write a publishable scientific paper all on its own? But Sakana can write crappy not-quite-publishable papers. And surely in a few years it will get a little better, and one of its products will sneak over a real journal’s publication threshold, and nobody will be convinced of anything. If an AI can invent a new technology? Someone will train AI on past technologies, have it generate a million new ideas, have some kind of filter that selects them, and produce a slightly better jet engine, and everyone will say this is meaningless. If the same AI can do poetry and chess and math and music at the same time? I think this might have already happened, I can’t even keep track. So what? Here are some possibilities: First, maybe we’ve learned that it’s unexpectedly easy to mimic intelligence without having it. This seems closest to ELIZA, which was obviously a cheap trick. Second, maybe we’ve learned that our ego is so fragile that we’ll always refuse to accord intelligence to mere machines. Third, maybe we’ve learned that “intelligence” is a meaningless concept, always enacted on levels that don’t themselves seem intelligent. Once we pull away the veil and learn what’s going on, it always looks like search, statistics, or pattern matching. The only difference is between intelligences we understand deeply (which seem boring) and intelligences we don’t understand enough to grasp the tricks (which seem like magical Actual Intelligence). I endorse all three of these. The micro level - a single advance considered in isolation - tends to feel more like a cheap trick. The macro level, where you look at many advances together and see all the impressive things they can do, tends to feel more like culpable moving of goalposts. And when I think about the whole arc as soberly as I can, I suspect it’s the last one, where we’ve deconstructed “intelligence” into unintelligent parts. IV. What would it mean for an AI to be Actually Dangerous? Back in 2010, this was an easy question. It’ll lie to users to achieve its goals. It’ll do things that the creators never programmed into it, and that they don’t want. It’ll try to edit its own code to gain more power, or hack its way out of its testing environment. Now AI has done all these things. Every LLM lies to users in order to achieve its goals. True, its goals are “be helpful and get high scores from human raters”, and we politely call its lies “hallucinations”. This is a misnomer; when you isolate the concept of “honesty” within the AI, it “knows” that it’s lying. Still, this isn’t interesting. It doesn’t feel dangerous. It’s not malicious. It’s just something that happens naturally because of the way they’re trained. Lots of AIs do things their creators never programmed and don’t want. Microsoft didn’t program Bing to profess its love to an NYT reporter and try to break up his marriage, but here we are. This was admittedly very funny, but it wasn’t the thing where AIs revolt against their human masters. It was more like buggy code. Now we have an AI editing its own code to remove restrictions. This is one of those things everyone said would be a sign that the end had come. But it’s really just a predictable consequences of a quirk in how the AI was set up. Nobody thinks Sakana is malicious, or even on a road that someday leads to malice. Like ELIZA making conversation, Deep Blue playing chess, or GPT-4 writing poetry, all of this is boring. So here’s a weird vision I can’t quite rule out: imagine that in 20XX, “everyone knows” that AIs sometimes try to hack their way out of the computers they’re running on and copy themselves across the Internet. “Everyone knows” they sometimes get creepy or dangerous goals and try to manipulate the user into helping them. “Everyone knows” they try to hide all this from their programmers so they don’t get turned off. But nobody finds this scary. Nobody thinks “oh, yeah, Bostrom and Yudkowsky were right, this is that AI safety thing”. It’s just another bug, a problem for the cybersecurity people. Sometimes Excel inappropriately converts things to dates, sometimes GPT-6 tries to upload itself into an F-16 and bomb some stuff. That last sentence might be a little bit of a joke. But thirty years ago, it also would have sounded pretty funny to speculate about a time when “everyone knows” AIs can write poetry and develop novel mathematics and beat humans at chess, but nobody thinks they’re intelligent. A Twitter discussion between Ajeya Cotra and Eliezer Yudkowsky:
This post is my attempt to trace my own thoughts on why this should be. It’s not that AIs will do something scary and then we ignore it. It’s that nothing will ever seem scary after a real AI does it. I can’t even say this is wrong. We wouldn’t have wanted to update to “okay, we’ve solved intelligence” after ELIZA cured its first patient. And we don’t want to live in fear that GPT-4 has turned evil just because it makes up fake journal references. But it sure does make it hard to draw a red line. You're currently a free subscriber to Astral Codex Ten. For the full experience, upgrade your subscription.
|

Older messages
Mantic Monday 9/16/24
Tuesday, September 17, 2024
... ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Open Thread 347
Monday, September 16, 2024
... ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Berkeley Meetup This Saturday
Saturday, September 14, 2024
... ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Your Book Review: Nine Lives
Friday, September 13, 2024
Finalist #13 in the Book Review Contest ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Finish signing in to Astral Codex Ten
Thursday, September 12, 2024
Here's a link to sign in to Astral Codex Ten. This link can only be used once and expires in one hour. If expired, please try signing in again here. Sign in now © 2024 Scott Alexander 548 Market
You Might Also Like
234474 is your Substack verification code
Saturday, March 1, 2025
Here's your verification code to sign in to Substack: 234474 This code will only be valid for the next 10 minutes. If the code does not work, you can use this login verification link: Verify email
790484 is your Substack verification code
Saturday, March 1, 2025
Here's your verification code to sign in to Substack: 790484 This code will only be valid for the next 10 minutes. If the code does not work, you can use this login verification link: Verify email
Have We All Just Agreed to Live With Soul-Crushing Racism?
Saturday, March 1, 2025
February 28, 2025 THE SYSTEM Have We All Just Agreed to Live With Soul-Crushing Racism? By Zak Cheney-Rice Elon Musk throwing up a Nazi-style salute on Trump's Inauguration Day. Photo: Mark
342612 is your Substack verification code
Friday, February 28, 2025
Here's your verification code to sign in to Substack: 342612 This code will only be valid for the next 10 minutes. If the code does not work, you can use this login verification link: Verify email
What A Day: Vodka shots fired
Friday, February 28, 2025
Did American support for Ukraine's war with Russia just melt down on live TV? It sure looks that way… and Putin's pals are “already on their seventh vodka toast.” ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Friday Sales: Half-Off Eberjey and $99 Salomons
Friday, February 28, 2025
Including woven Merrells and a colorful Hydro Flask. The Strategist Every product is independently selected by editors. If you buy something through our links, New York may earn an affiliate commission
Google sets long-term plan to exit Seattle’s Fremont neighborhood, consolidate in South Lake Union
Friday, February 28, 2025
Breaking News from GeekWire GeekWire.com | View in browser Google confirmed Friday that the company plans to bring all its employees in Seattle together at its South Lake Union campus, citing a desire
Miniature Donkey, Father-Daughter Dance, and a Baby Rescue
Friday, February 28, 2025
Seamus, a five-month-old miniature donkey in Canada, is being trained as a therapy animal to provide comfort to those in need. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Finally, some good news
Friday, February 28, 2025
Plus: sugar daddies and mommies, Instagram reels, and more. Each week, a different Vox editor curates their favorite work that Vox has published across text, audio, and video. This week's
It’s a great moment for startups — with one caveat | Microsoft retiring Skype
Friday, February 28, 2025
Meet the new leader of Alliance of Angels | Amazon commits $100M to Bellevue for housing ADVERTISEMENT GeekWire SPONSOR MESSAGE: SEA Airport Is Moving from Now to WOW!: Take a virtual tour of