Thoughts on Platforms, Core Teams, DORA Report and all that jazz
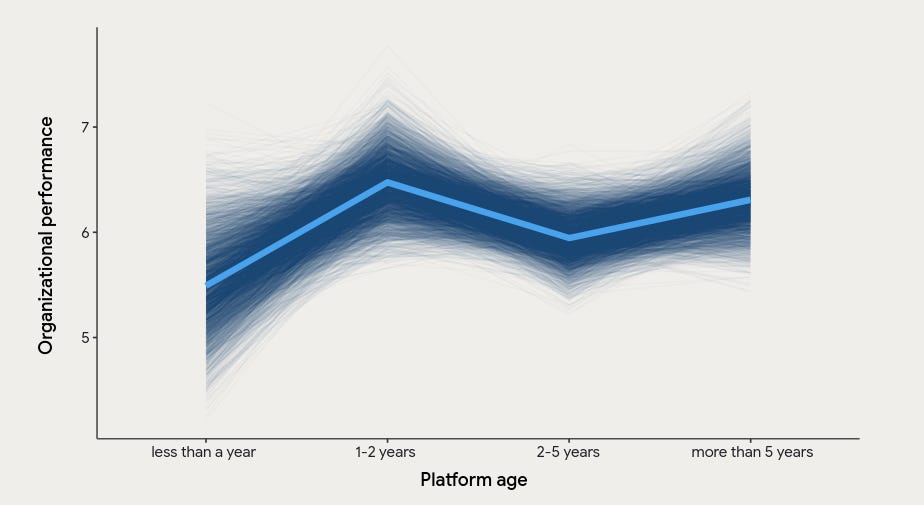
All the best in New Year! Here’s my summary of 2024: I survived! And that’s a success that I want to repeat in 2025. Right before christmas, I wrote a longer thread in social media with my thoughts on the hot topic: platform teams. I see many of my clients trying to apply it, some succeeding, some more, but all struggling. I’m not an expert in the internal platforms, but I was a part of the core teams, shaping continuous integration and delivery processes, and I see many similarities. As my thoughts spin up some good discussion (see here or there), I decided to also share it today with you. And that’s a free post, so if you enjoyed, feel free (pun intended) to share it with your friends! The challengeThe longer we work on some code, the more polished it gets? Actually, it’s not always like that. Past me believed in shared reusable code. Now, I’m looking at it from a different angle. Platforms, shared code, core libraries - they’re all faces of the same issue. We try to build one tool to rule them all, which never works. At least for a longer time. Whether you call it a “platform team“ or a “core team” the nature of the struggle remains the same: both groups aim to provide foundational solutions across the organization. They often wrestle with the same problem—trying to anticipate every scenario in a single, central codebase or service. Over time, these monolithic solutions become harder to maintain, and the team maintaining them drifts away from the real-world issues developers face day-to-day. That’s how both platform teams and core teams can fall into the trap of delivering an all-in-one system that erodes under the weight of endless patches and shifting priorities. Fallacy of the one to rule them allI believe that even in internal projects, we should focus more on small, focused tools rather than a monolithic platform. Tools are built for something; they don’t need to fulfil every possible scenario but can instead home in on a specific area. And I don’t mean only technical tools; I’m also talking about business features for user-facing areas—think back offices. Why does that matter? For most of our business, building one massive internal solution won’t ever be a business per se. It can only be a priority when it truly provides direct business value. That’s how we get to the counterintuitive part of “the longer honed the better.” Those big core/platform components tend to be the most stable after one or two years, when we already have a solid grasp of what we’re doing. Then they slowly degrade as the need for rapid delivery of internal capabilities becomes a priority, and teams focus back on their domain. Don’t believe me? Check this diagram from DORA Accelerate State of DevOps report 2024:
Do you see the peak in 1-2 years? That’s when erosion starts. When we add more features, we already get an understanding of what we do. Then, they slowly degrade as the need for rapid delivery of internal capabilities slows down and thus becomes a priority. Teams start to focus on their domain. Adding a quick patch to a stable core won’t seem like a big deal, but it piles up. Meanwhile, the tech landscape changes. Better tooling emerges, and our homebrew solutions become obsolete. Add to that the fact that it’s hard to justify constantly working on a tech-focused platform that, according to management, “should have been already done.” Then the platform team often becomes detached from the daily struggles of other teams, and we start seeing Conway’s Law in action. Not great. What does that mean detached?
If you think that’s only my anecdotal evidence, check the interesting findings from DORA report. It can bring the instability of the development process:
And on skewed perspective of the organisation about the platform team impact:
Generic does not mean SimpleThat’s why I always say that “Generic does not mean Simple”. Reusability and maintainability are not values per se. My suggestion is to focus on delivering precise business or tech tools. You may not need to maintain them forever, and it can be simpler to justify and explain to management why you must keep them fresh. Of course, it’s less sexy than playing with the newest stack, but it pays off in the longer term. That’s what I was also doing with my OSS work. I have Event Sourcing samples that I delivered in the form: “take them in whole or parts, adjust to your needs”. Then observing how people interacted with them, seeing the usage patterns, motivated me to pack them into the reusable toolbox like Emmett. You can do it in the same way in your regular projects. Of course, we need to be careful. Copy/pasted templates can help, but they’re also cumbersome if we need to update them later and replicate changes across the organization. It’s more about “catalogue how we do it” than “enforce how we must do it” aiming to reduce the boring, repeatable setup. Creating a generic internal platform from the very beginning of a project can introduce artificial limitations. We’re making those hard decisions in the worst possible moment: when we’re dumbest. We don’t know the tech stack, we don’t know the domain, we’re shaping our product vision. We try to predict where and how the business and tech will evolve. Frankly, we’re more guessing than predicting. It’s often a sign of being too self-assured or short-sighted: it’s easy to whip up the solution that feels quick and friendly for a single case, but once we reach the long tail of features, we realize we didn’t anticipate everything. For example, rather than providing an all-encompassing core “everything module” that does automatic mapping, calls pluggable services, generates docs automatically, and so on, it’s more sustainable to offer smaller modules specifically focused on handling particular concerns. A huge internal platform must handle all possible scenarios, and maintainers have to guess the usage, whereas smaller, dedicated solutions let teams solve specific use cases based on the patterns they want to promote. People can also diverge more easily and adopt new tech when they’re not locked into an all-encompassing internal platform. It’s simpler to remove a small, now-obsolete piece of code than to tear out something massive. Plus, when multiple teams use those small modules, they can contribute improvements and provide feedback. Let’s quote DORA report again:
Plaform takes the painI love the term Platform Takes The Pain, it’s a great motto stated by Pia Nilsson responsible for Spotify platform. She explained it in the Corecursive Podcast episode. She told how they traansitioned from isolated teams into centralised, but focused platform. It’s a great story on transitioning the platform team mentality from playing with CI/CD tools and experimenting to becoming an enabling team for others. So yes, centralisation is not always bad. Some elements - like cross-service communication, documentation, or security - have to be enforced to keep consistency, but for most things, gentle guidance is enough. In Spotify they realised that platform should not be the elitist team enforcing on others how to behave, but helping them proactively, contributing hand in hand to introduce the new approach. That means making the actual Pull Requests to business modules modernising they’re way. That’s also a similar advice that Hazel Weakly did in our webinar on Applying Observability. She told on how to add observability and instrumentation:
Such approach, helps to set the priorities right, so enabling not enforcing. I saw that platform teams believe they’re the foundational and elitist team. At the same time, they’re there to help others deliver business value. We need to avoid the story shared by Ben Dumke-von der Ehe on his work in the Stack Overflow core team.
Pitfals and solutionsPart of the problem is also a mix of lack of trust and the mistaken assumption that centralizing everything will save development time overall. Early on, it might—but soon the Pareto principle hits, and we spend 80% of our time on the last tricky 20%. I’ve fallen into this trap myself, creating classes with 14 generic parameters or pipelines that claimed “zero config.” This quickly becomes a vicious circle: by dictating everything from the center, we don’t teach genuine ownership or a learning path. I’ve witnessed plenty of trouble arising from piling everything into one core. It might not be obvious at first, but after a year or two, a single, centralized repository of random code becomes an unmaintainable anchor. That’s not to say it can’t work—it’s just more likely to work with smaller teams that share an understanding of the domain. It’s also about how much knowledge each team has and how we foster continuous learning. A helpful tool might say: “If you stick to the recommended approach, you get OpenAPI for free. If you don’t, that’s fine, but then you own it and must maintain it.” Or another example: When building CI/CD pipelines, avoid magical, behind-the-scenes processes. Instead, provide plugins or templates with safe defaults. Infrastructure-as-Code tools like AWS CDK make it possible to build well-defined components rather than black boxes. In this way we’re showing people benefits. We’re giving the a carrot, not only a stick. And option to diverdge if that makes sense. It also gives people ownership and making them accountable. As Charity Mayors say: you build it, you run it. She did a nice talk Perils, Pitfalls and Pratfalls of Platform Engineering. She outlined the following pitfalls in her talk:
And that’s nicely wraps up on what we should avoid and what we also discussed so far. Platform as a backofficeI love the idea that Andreas Pinhammer explained in his talk DDD in large product portfolios. A key takeaway was how their “platform team” ended up being a business back-office focused on enabling others instead of just a “Kubernetes-and-other-technical-stuff” team. They focused on the business features that are not user facing, but can help other business teams to do stuff faster. The good example for that could be payment-module-as-a-platform. Multiple modules can require payments, there’s no point in repeating that features all around. We can gather the requirements, form a dedicated team that will be responsible for delivering business capabilities to other teams. There are good tools that can help in that Context Mapping and Team Topologies. You can start with those two talks:
In short that’s also the impact of the Conway Law, that we just cannot avoid. We discussed that in details in: Final adviceIf you’re already in the scenario where your platform/core is going rogue then my suggestion is to focus on delivering exact business instead of tech tools. You can start with the following steps:
By that we adapt by delivering smaller, targeted solutions, better tooling, and real synergy between operations, coding, and design. It’s all about enabling teams to be effective, accountable, and ready to adjust as our business grows and our tech evolves. Of course, it’s less sexy than playing with the new tech stack, but it will pay off in the longer term. What’s your experience, challenges and piece of advice? Please share it with me, I’m more than curious! Cheers! Oskar p.s. Ukraine is still under brutal Russian invasion. A lot of Ukrainian people are hurt, without shelter and need help. You can help in various ways, for instance, directly helping refugees, spreading awareness, and putting pressure on your local government or companies. You can also support Ukraine by donating, e.g. to the Ukraine humanitarian organisation, Ambulances for Ukraine or Red Cross. You're currently a free subscriber to Architecture Weekly. For the full experience, upgrade your subscription.
|
Older messages
Locks, Queues and business workflows processing
Monday, December 30, 2024
Last week, we discussed Distributed Locking. Today, we'll continue with it but doing it differently: with a full backflip. We'll see how and why to implement locks with queuing. Then we'll
Distributed Locking: A Practical Guide
Monday, December 23, 2024
If you're wondering how and when distributed locking can be useful, here's the practical guide. I explained why distributed locking is needed in real-world scenarios. Explored how popular tools
On getting the meaningful discussions, and why that's important
Thursday, December 19, 2024
To put our design into practice, we need to be able to persuade our colleagues, stakeholders, and other peers. Without the ability to explain and persuade, even the best design will not be applied. And
The Write-Ahead Log: The underrated Reliability Foundation for Databases and Distributed systems
Tuesday, December 10, 2024
The write-ahead log (WAL) is everywhere. Yet, many people miss it and are not aware of it. The simple idea powers reliability in databases, messaging systems, and distributed systems. Let's discuss
Applying Observability: From Strategy to Practice with Hazel Weakly
Monday, December 2, 2024
Have you considered applying observability but struggled to match the strategy with the tooling? Or maybe you were lost on how to do it? I have something for you!I had a great discussion with Hazel
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your