How does Kafka know what was the last message it processed? Deep dive into Offset Tracking
Let’s say it’s Friday. Not party Friday, but Black Friday. You’re working on a busy e-commerce system that handles thousands of orders per minute. Suddenly, the service responsible for billing processing crashes. Until it recovers, new orders are piling up. How do you resume processing after the service restart? Typically, you use the messaging system to accept incoming requests and then process them gradually. Messaging systems have durable storage capabilities to keep messages until they’re delivered. Kafka can even keep them longer with a defined retention policy. If we’re using Kafka, when the service restarts, it can resubscribe to the topic. But which messages should we process? One naive approach to ensure consistency might be reprocessing messages from the topic's earliest position. That might prevent missed events, but it could also lead to a massive backlog of replayed data—and a serious risk of double processing. Would you really want to read every message on the topic from the very beginning, risking duplicate charges and triggering actions that have already been handled? Wouldn’t it be better to pick up exactly where you left off, with minimal overhead and no guesswork about what you’ve already handled? Not surprisingly, that’s what Kafka does: it has built-in offset tracking. What’s offset? Offsets let each consumer record its precise position in the messages stream (logical position in the topic portion). That ensures that restarts or redeployments don’t force you to re-ingest everything you’ve ever consumed.
Services that consume message streams can restart or be redeployed for countless reasons: you might update a container in Kubernetes, roll out a patch on a bare-metal server, or autoscale in a cloud environment. In this article, we’ll look at how Kafka manages offsets under the hood, the failure scenarios you must prepare for, and how offsets help you keep your system consistent—even when services are constantly starting and stopping. We’ll also see how other technologies tackle a similar challenge. As always, we take a specific tool and try to extend it to the wide architecture level. Check also previous articles in these series: Let’s do the thought experiment. Stop now for a moment and consider how you would implement offset storage for a messaging system. Remember your findings, or better yet, note them down. Are you ready? Let’s now discuss various options we could use, and check how Kafka offset storage evolved and why. 1. Early Attempts at Storing OffsetsDatabase Storage. A straightforward way to track what a consumer has processed is to store the last processed message ID in a relational database or key-value store. This can be fine if you have a single consumer, but you run into trouble as soon as you introduce multiple consumers. Each consumer must update the same record, raising the risk of race conditions, distributed locking or expensive transactions. Plus, if one consumer crashes mid-update, another might not know which offset is the latest. Local Files. Another idea is to write the current offset to a local file on the machine running the consumer. This might spare you the overhead of a database, but it quickly becomes unmanageable if the machine dies or you need to scale out. Each new consumer instance has its own file, and there’s no easy way to keep them all consistent. As soon as you have more than one consumer—or if you want failover without losing track of progress these approaches break down. That’s why Kafka uses a different model. 2. From ZooKeeper to special topicHistorically, Kafka itself used Apache ZooKeeper to store consumer offsets. ZooKeeper is a distributed key-value store with additional coordination features. It allows distributed systems to store and retrieve data across multiple servers. It acts like a centralized database that helps different parts of a system share and manage configuration information and state. Unlike a simple key-value store, it provides features like atomic writes, watches (notifications), and hierarchical naming, making it particularly useful for configuration management and synchronization in distributed computing environments. Using Zookeeper to store offsets might have worked fine when you had only a few consumer groups or infrequent commits, but it wasn’t designed to handle the constant stream of updates in larger deployments. Every offset commit triggered writes to ZooKeeper, and as the number of consumer groups and partitions grew, those writes multiplied, creating performance bottlenecks and stability concerns. ZooKeeper was never intended for high-throughput offset tracking, so teams running sizable Kafka clusters began encountering scaling issues—ranging from slower commit latencies to potential coordination timeouts—when offset commits overloaded ZooKeeper. To solve these problems, Kafka introduced the
Version 0.9 still allowed using Zookeeper through the offsets.storage=zookeeper 3. How offsets topic worksAlthough Topic Structure and PartitioningBy default, it’s partitioned into a fixed number of partitions (often 50), with each partition managing offset commits for a subset of consumer groups. This design ensures that offset storage can scale horizontally—no single partition is overloaded by too many commits.
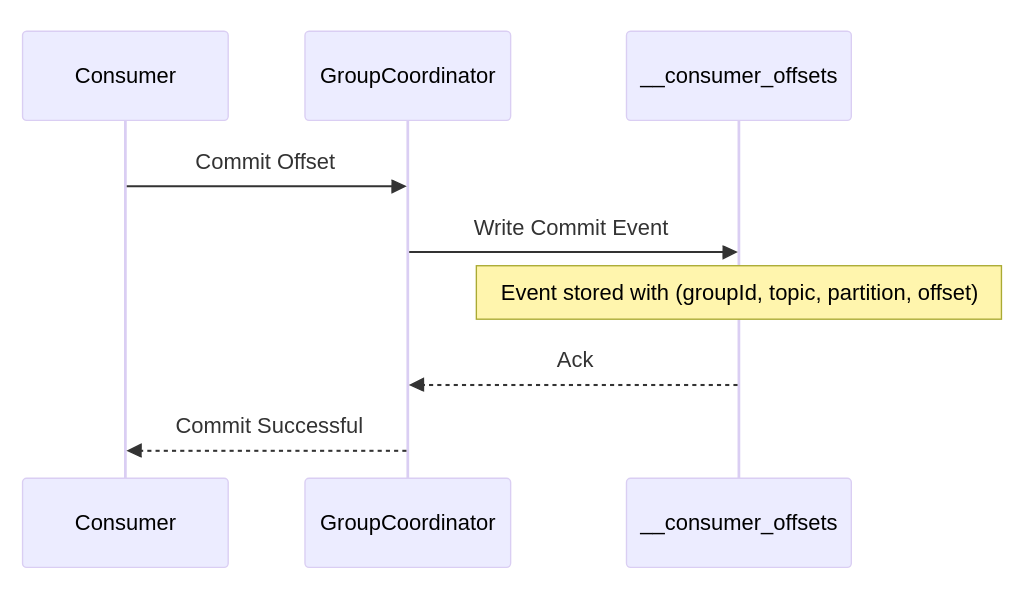
In this simplified flow, a consumer sends an offset commit to the Kafka broker, which appends a commit event to the appropriate partition in You should always consider how frequently you commit offsets to get the desired performance. Committing after every message assures minimal replays but burdens the broker with frequent writes. Committing in larger batches cuts down on overhead but means a crash could reprocess a bigger chunk of messages. Monitoring metrics like consumer lag, commit latency, and rebalance frequency helps you tune these factors for your workloads. Message FormatUnder the hood, each offset commit is stored as a small message. While the actual format is internal to Kafka, you can think of it in a simplified TypeScript-esque interface: Continue reading this post for free in the Substack app
|


Older messages
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
Pssst, do you want to learn some Event Sourcing?
Friday, February 14, 2025
Hi! Does Event Sourcing tempt you but don't know where to start? Is your business losing data? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
How a Kafka-Like Producer Writes to Disk
Monday, January 13, 2025
We take a Kafka client, call the producer, send the message, and boom, expect it to be delivered on the other end. And that's actually how it goes. But wouldn't it be nice to understand better
Invitation to the Event Sourcing workshop
Friday, January 10, 2025
Hey! I'm usually not making New Year commitments. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Thoughts on Platforms, Core Teams, DORA Report and all that jazz
Monday, January 6, 2025
Everyone's hyping “platform teams” like they're the next big thing—yet I see so many struggling, often for the same reasons core teams do. In latest edition I dive into why these big, central
You Might Also Like
💎 Issue 458 - Why Ruby on Rails still matters
Thursday, February 27, 2025
This week's Awesome Ruby Newsletter Read this email on the Web The Awesome Ruby Newsletter Issue » 458 Release Date Feb 27, 2025 Your weekly report of the most popular Ruby news, articles and
📱 Issue 452 - Three questions about Apple, encryption, and the U.K
Thursday, February 27, 2025
This week's Awesome iOS Weekly Read this email on the Web The Awesome iOS Weekly Issue » 452 Release Date Feb 27, 2025 Your weekly report of the most popular iOS news, articles and projects Popular
💻 Issue 451 - .NET 10 Preview 1 is now available!
Thursday, February 27, 2025
This week's Awesome .NET Weekly Read this email on the Web The Awesome .NET Weekly Issue » 451 Release Date Feb 27, 2025 Your weekly report of the most popular .NET news, articles and projects
💻 Issue 458 - Full Stack Security Essentials: Preventing CSRF, Clickjacking, and Ensuring Content Integrity in JavaScript
Thursday, February 27, 2025
This week's Awesome Node.js Weekly Read this email on the Web The Awesome Node.js Weekly Issue » 458 Release Date Feb 27, 2025 Your weekly report of the most popular Node.js news, articles and
💻 Issue 458 - TypeScript types can run DOOM
Thursday, February 27, 2025
This week's Awesome JavaScript Weekly Read this email on the Web The Awesome JavaScript Weekly Issue » 458 Release Date Feb 27, 2025 Your weekly report of the most popular JavaScript news, articles
💻 Issue 453 - Linus Torvalds Clearly Lays Out Linux Maintainer Roles Around Rust Code
Thursday, February 27, 2025
This week's Awesome Rust Weekly Read this email on the Web The Awesome Rust Weekly Issue » 453 Release Date Feb 27, 2025 Your weekly report of the most popular Rust news, articles and projects
💻 Issue 376 - Top 10 React Libraries/Frameworks for 2025 🚀
Thursday, February 27, 2025
This week's Awesome React Weekly Read this email on the Web The Awesome React Weekly Issue » 376 Release Date Feb 27, 2025 Your weekly report of the most popular React news, articles and projects
February 27th 2025
Thursday, February 27, 2025
Curated news all about PHP. Here's the latest edition Is this email not displaying correctly? View it in your browser. PHP Weekly 27th February 2025 Hi everyone, Laravel 12 is finally released, and
📱 Issue 455 - How Swift's server support powers Things Cloud
Thursday, February 27, 2025
This week's Awesome Swift Weekly Read this email on the Web The Awesome Swift Weekly Issue » 455 Release Date Feb 27, 2025 Your weekly report of the most popular Swift news, articles and projects
JSK Daily for Feb 27, 2025
Thursday, February 27, 2025
JSK Daily for Feb 27, 2025 View this email in your browser A community curated daily e-mail of JavaScript news Introducing the New Angular TextArea Component It is a robust and flexible user interface