🎙 Olga Megorskaya/Toloka: Practical Lessons About Data Labeling
Was this email forwarded to you? Sign up here 🎙 Olga Megorskaya/Toloka: Practical Lessons About Data Labelingand balance between fully automated, crowdsourced or hybrid approaches to data labelingIt’s inspiring to learn from practitioners. Getting to know the experience gained by researchers, engineers, and entrepreneurs doing real ML work is an excellent source of insight and inspiration. Share this interview if you find it enriching. No subscription is needed.
👤 Quick bio / Olga Megorskaya
Olga Megorskaya (OM): I’ve got a degree in Mathematical modeling in Economics, with my research interest related to expert judgments and how they can be used to empower statistics-based models. I even started my Ph.D. thesis on this topic but gave up lacking data needed for my research (so many good ideas die due to lack of data, don’t they?). Now I’ve got lots of data on expert judgments (Toloka generates more than 15 million labels every day!), but now I don’t have time for my thesis. However, I found myself in the ML domain quite accidentally: while studying, I made some extra money as a Search quality assessor at Yandex, the largest Russian IT company and search engine. Later, when I joined the Yandex Search team, I had a chance to participate in the development of a search quality evaluation system based on human judgments and then oversee providing all ML-powered services of Yandex with data labeling infrastructure. That was when we started Toloka. We created it to fit our own needs in large-scale industrial ML pipelines and have a proven track record of using it to build successful products. I’m proud to know that under the hood of every Yandex product, be it Search, Self-driving Rovers, Voice assistants, or whatever else, there is Toloka technology. 🛠 ML Work
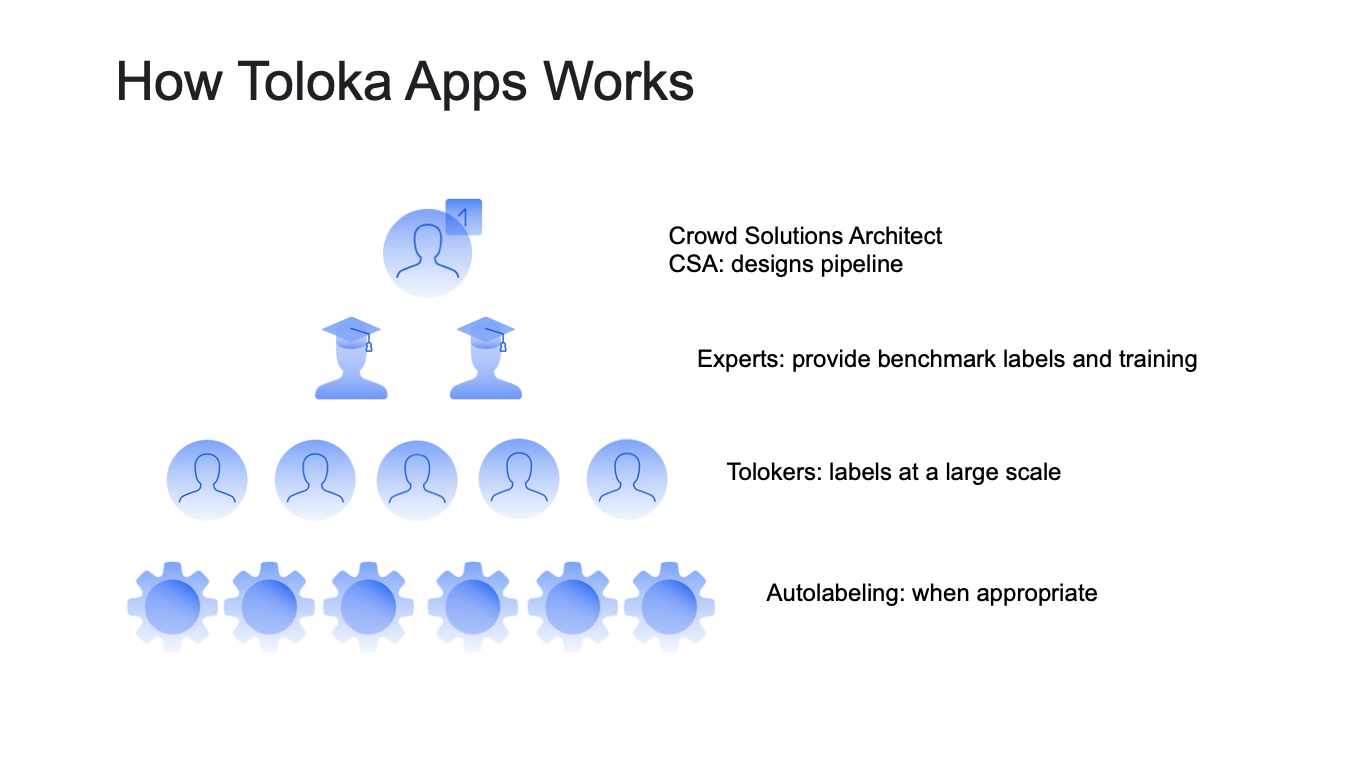
OM: We started working with data labeling production more than ten years ago and helped hundreds of teams set up thousands of projects. And we know that there is no silver bullet. The key is the optimal combination of different methods.
Interestingly, the lower the pyramid level is, the harder it is to build such a solution, the more technologies it requires, and the more scalability and effectiveness it provides. It is much easier to train and manage a limited number of annotators, but the labeling production that relies solely on them is expensive and, what is worse, does not scale. At the same time, relying only on a purely automated solution may limit the useful signal in your models. So, in my opinion, the optimal combination consists of:
At Toloka, we provide an infrastructural platform for engineers to build their optimal pipelines integrated into ML production cycle and pre-set optimal pipelines combining all the three components: experts, crowd, automation to obtain the best result.
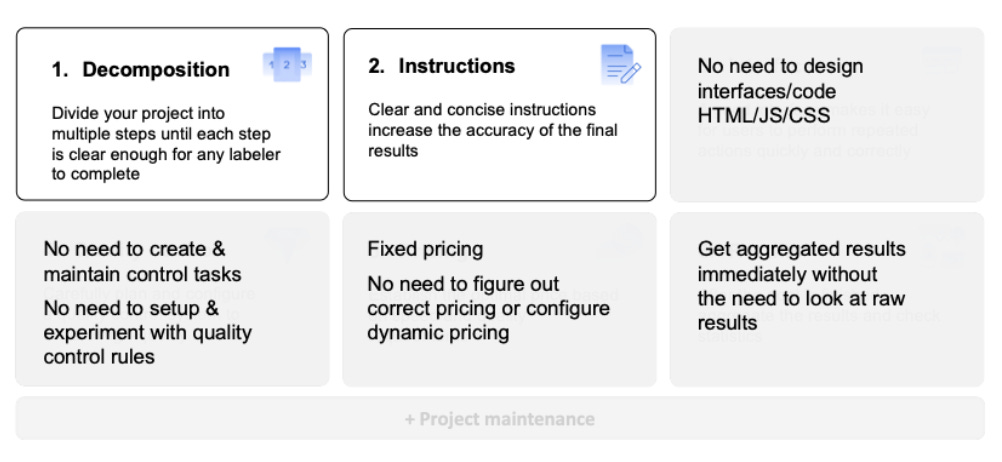
OM: Creating an effective data labeling pipeline able to provide stable, high-quality labels at scale requires six steps:
By taking these steps, you'll get to the most cost-effective, high-quality data labeling pipeline at scale. We provide an open platform for engineers with all the necessary components: the global crowd, full range of automated quality control methods, the pre-set interfaces, dynamic pricing and tools for balancing speed/quality ratio, optimal matching of tasks and performers, and so on. As well as a free powerful API to integrate it into the ML production pipeline. However, not every team has resources to set up all the processes themselves, and time-to-result is often the key factor. For such teams, we created a specific solution: pre-set pipelines with the optimal combination of Toloka’s in-house expert labelers, crowd, and automation to provide the best quality at minimal efforts from the requester's side.
OM: Indeed, the industry is developing fast, and we are expecting the further rise of such technologies soon. I pay attention to the trends that align with our product vision:
OM: Well, the benefits are obvious: adding auto labeling helps increase the quality and quantity of collected labels. However, one should be careful not to overfit the model on the same datasets and not lose the important additional signal obtained only from an independent source (human labels). So, ML specialists should not forget to validate the quality of their models on independent datasets correctly.
OM: First of all, bias should be considered and avoided on the stage of choosing the data to label, not at the stage of labeling. If we speak about classic data labeling tasks and follow the steps I described above, the problem of bias is reduced by writing comprehensive guidelines that leave minimal room for subjective judgments. However, in some cases, subjective human judgment is required to obtain important signals. For example, the side-by-side tasks are purely subjective to allow for digitizing subjective perception of objects. In these cases, specific models (such as Bradley-Terry) will enable us to avoid systematic bias. Speaking about fairness, I would like to talk about how the annotators are treated. This topic is personally important to me since I had the experience of working as a data annotator. I think it is a true shame of our industry that AI development is still powered by efforts of poorly treated annotators who are forced to sit in gloomy offices for many hours in a row without the ability to choose tasks, without career perspectives, and without free time to devote to education, hobbies or any other sources of joy and self-development in life. At Toloka, we organize everything flexibly when self-sufficient people plug into the platform when interested and are free to choose any task they want based on the open rating of requesters and spend as much time on it as they find reasonable. In the former case, you need strict managerial efforts to provide good quality of labeling. In the latter case, it is managed mathematically. That is why we support the research about crowd workers’ well-being to make sure we develop our platform with respect to their interests. 💥 Miscellaneous – a set of rapid-fire questions
Monty Hall paradox is an excellent illustration of the Bayes Theorem. Bayesian methods are one of the cornerstones of quality management techniques in Toloka: aggregation models, dynamic pricing, dynamic overlap, etc. All the cases when we reconsider our understanding of the unknown every time we obtain a new piece of information. And the famous Butterfly Effect. It is tightly connected to your previous question about biases in training models. AI will soon be woven into every sphere of our lives. It is trained on data mostly labeled by humans. Any systematic bias incorporated into a dataset on the stage of its annotation may lead to systematic bias in the model. As I said, systematic bias can come from poorly formulated guidelines. So, such a seemingly minor part of ML production as writing guidelines for annotators can have a far-going effect in the future.
The Toloka team is full of great ML engineers, so I decided to ask them for the best advice. Our team recommends Introduction to Machine Learning with Python: A Guide for Data Scientists and Machine Learning Engineering.
If you intuitively understand the Turing Test as "does the computer convincingly answer the questions asked by a person", then there is a very interesting article where the author asks GPT-3 questions, and it turns out that GPT-3 answers consistently incorrectly. There are ways to improve the model specifically for this case, but there are other examples. For instance, here, the authors show that GPT-3 does not cope well with the task of writing analogs.
If it is, we are in trouble:) You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2021 Jesus Rodriguez, Ksenia Semenova Unsubscribe
|



Older messages
🔵⚪️Edge#136: Kili Technology and Its Automated Data-Centric Training Platform
Friday, October 29, 2021
Let's dive in
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your