📝 Guest post: How to build SuperData for AI [Full Checklist]*
Was this email forwarded to you? Sign up here In TheSequence Guest Post our partners explain in detail what machine learning (ML) challenges they help deal with. In this post, SuperAnnotate’s team offers you a full checklist for building a robust data pipeline. IntroPredominant methodologies in developing artificial intelligence (AI) and machine learning (ML) models advocate the use of vast amounts of data. It often becomes challenging to roll back for fixes in algorithms after the implementation, which points to the significance of integrating quality datasets at the outset. Whether feeding off-the-shelf pre-built data or collecting on our own, an initially established error-and-bias-free dataset can help build better-performing models. Be that as it may, we are not here to provoke deeper thinking about AI or reignite the endless debate on algorithms vs. data. We are data-driven. Experiencing the value of quality data firsthand made us almost impatient of sharing how to build better data to give your models a significant advantage in the long run. In the following, we’ll discuss:
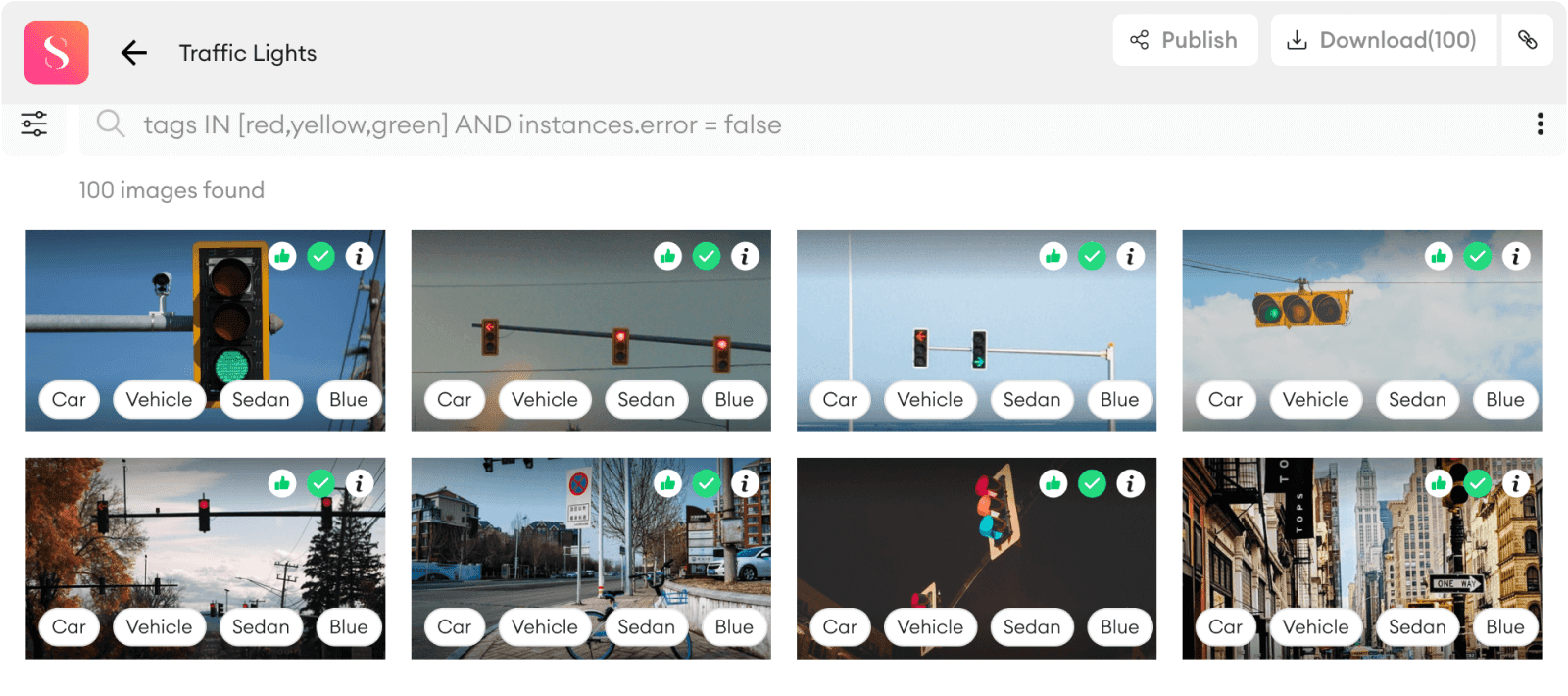
The art of collecting dataAs a primary step in developing a model, data collection requires a nuanced and all-around perspective. What is the data that we need? A question as simple as that opens up room for further planning on how to gather training data, how to warrant its quality, or make sure it is what the model will “see” throughout the deployment. Depending on the application, collecting data manually can take a significant cut of time and resources. The price of a single satellite image, for example, is in the range of hundreds to thousands of US dollars, and the exact impact it has on our model can only be known after training it on the new data point. However, to the best of our knowledge, the influence of new images can still be efficiently estimated. A few alternatives to data acquisition include using public datasets (COCO dataset, the Cityscapes, BDD100K, Pascal VOC, etc.) and synthetic datasets. While collecting data consumes time and resources, it is vital to take precautions to analyze the dataset and ensure it corresponds with project requirements. Otherwise, issues such as dataset imbalance may prevail. A model might have difficulties detecting the road signs if the data introduced contains only daytime images, for instance. Now, how will that affect your output? Flawed predictions, in all likelihood. Building a robust data pipelineData collection is usually followed by the next staple: An effective data pipeline glues the puzzle together, establishing a viable system to navigate through the data path, from raw inputs to predicted deliverables. This often allows typing, reviewing, and polishing your data much more efficiently to assure you can easily refer back and apply changes to the dataset or dataset version as per need. Instead of standardizing on a single data format, also consider building up and bolstering a format-agnostic pipeline that can generate data from a wide range of formats, including image, text, and video. Besides, it is paramount to estimate ahead of time the volume of your data to start developing a process for saving images and accessing them later on. Spilling the beans just a tiny bit, one way to automate uploading massive volumes of data is through SuperAnnotate’s SDK function. Our users prefer SDK integration as it minimizes manual processes, reduces workflow complexity, and helps complete tasks way faster than existing alternatives. Let us know whether you agree once you check it out.
Annotation and QA (Quality Assurance)The quality of raw data directly impacts your AI performance. This comes to the fore especially during training, where your goal is to end up with a model that is unbiased. Confidence in raw data and a rigorous pipeline will lead you to the next stage of building premium-quality data: annotation and QA, which requires special attention to detail. After all, you don’t want to annotate facial features with bounding boxes or a text body by semantic segmentation, correct? If you want to develop robust and reusable training data, be cautious of the annotation techniques used. Make use of QAs for additional rounds of examination, but first, you have to be sure people in the loop understand the project’s end goal to generate appropriate instructions and annotations. If you want to learn more on how to build SuperData click the button below to download all our insights in a single checklist. Data management and versioningLeaning on the latest AI capabilities allows you to not only exclude data from your training set if not relevant but also to generate versions of data for prospective use. This way, you will build models on the most reliable datasets only while cutting down on the building process. In case anything crashes, you will always be able to smuggle back for changes in training data. You can also version different random splits of the same dataset in order to study the bias induced by partitioning training and test data. This is also known as cross-validation. By and large, data versioning helps keep track of different sets of data, compare model accuracies and analyze the pain points and emerging tradeoffs. Keep in mind that depending on your use case, it may make sense for you to combine several datasets. This practice will serve best, especially if every dataset is too small for high-accuracy predictions or if it doesn’t provide you with balanced data. Error finding and curationOne of the most common problems with data is that its quality is often uneven. In some places, it might be inaccurately labeled or low-resolution. If you're going to train AI, you need an easy way to see how the data you're feeding into the model is free from such impurities. A curation system can be a huge help in detecting these issues and performing comparative dataset analysis. Moreover, training data can be enormous, and it becomes even more gigantic if you're planning to test various versions of your model. With SuperAnnotate's curation system, you get a clear idea of your data quality through wider filtering options, data visualization, and team collaboration opportunities.
Building and versioning modelsImplemented in a timely manner, the model versioning can be a boon to AI, cranking out necessary variations and updates and reducing pitfalls in the final output. When you are ready to roll out your work, though, testing and revision might limit the pace of development. Hence, it becomes useful to know why some model A is better than model B and where data stands within that comparison. Be mindful of the fact that versioning should be implemented early on in the process. If you track changes to your models and document why you made them, it's easier to maintain consistency in delivery over time, even if it’s limited to a certain extent. By revising your model frequently, you can make sure you're using the best models you could develop, which in turn will guarantee maximum accuracy in predictions. Deployment and monitoringRule of thumb: It’s not enough to deploy your model in production. You also have to keep an eye on how it’s performing. If the model doesn’t deliver the results as expected, there should be a way to revert quickly. Here is where knowing the influence of the data on the model becomes crucial, and curation plays a fundamental role in spotting data-related issues. Follow-up maintenance is essential to ensure the model is working as planned, that there are no run-time issues, and even if there are, fix them before they become significant. Creating triggers to notify you when there are changes in metrics can save a lot of back-and-forth revisions. Nonetheless, we can't always predict the consequences of deployment. Extra caution and preparation are necessary to manage any possible side effects. Deploying a failure detection algorithm together with partial human supervision is a very good idea; the supervision level can be reduced over time. On-time monitoring and fixation would have reduced the probability of unfortunate upshots. Key takeawaysThe process of building SuperData entails more questions than answers: progress here is being made by asking better questions that redefine and spruce up the data quality. A vast amount of similar questions will be drawn from the sections of the checklist above, which we recommend downloading and embedding into your agenda. We at SuperAnnotate will gladly offer a helping hand at any stage of your pipeline. *This post was written by SuperAnnotate’s team and originally published on their blog. We thank SuperAnnotate for their ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2021 Jesus Rodriguez, Ksenia Semenova Unsubscribe
|




Older messages
🏷 Edge#138: Toloka App Services Aims to Make Data Labeling Easier for AI Startups
Thursday, November 4, 2021
New tools on the market
📌 Event: MLOps Cocktails Done Right: How to Mix Data Science, ML Engineering, and DevOps*
Wednesday, November 3, 2021
[FREE Virtual Event]
🤓 Edge#137: Self-Supervised Learning Recap
Tuesday, November 2, 2021
As requested by many of our readers, we put together a recap of the SSL series.
🤔🤯 Addressing One of the Fundamental Questions in Machine Learning
Sunday, October 31, 2021
Weekly news digest curated by the industry insiders
🤩 Early access: try the world's most flexible AI cloud*
Friday, October 29, 2021
only for TheSequence readers
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your