📝 Guest post: A Guide to Leveraging Active Learning for Data Labeling
Was this email forwarded to you? Sign up here In TheSequence Guest Post, our partners explain in detail what machine learning (ML) challenges they help deal with. In this post, Labelbox’s team offers you a complete guide on putting active learning strategies into practice. What is Active Learning?In short, active learning is the optimal selection of data to maximize model performance improvements given limited resources. Teams spend up to 80% of their time building and maintaining training data infrastructure, including cleansing, transforming, and labeling data in preparation for model training. Without an active learning strategy in place, teams see diminishing returns on their labeled data in terms of impact on model performance. Active learning can help streamline this bottleneck and increase your training data’s ROI. First, watch this video to understand why active learning is a valuable concept to help teams save time and resources on their path to production AI.  What will active learning help you accomplish?
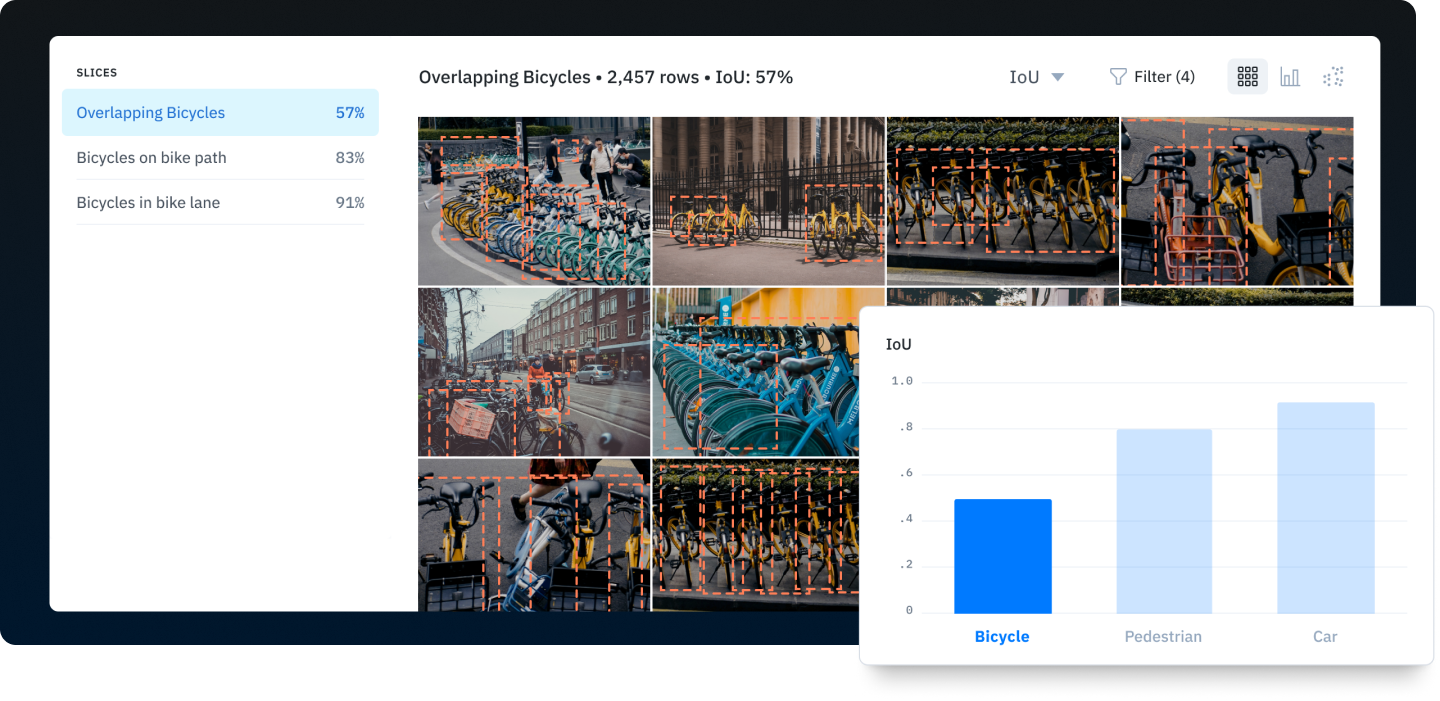
Label less dataWith state-of-the-art neural networks available for free and effective AI computation speed doubling every 3-6 months, training data is what fuels an ML team’s competitive advantage. In this data-centric approach, it’s essential for teams to focus on the right data, not just more data. ML teams spend most of their time and resources managing and labeling data, not building AI systems. Often, teams continue to label data and grow the size of a dataset despite no additional gains in performance. Better understand your model’s performance and edge casesTo find what data will drive the most meaningful improvements, you need to clearly understand where your model performs well and where it needs more attention to accurately address edge cases. This understanding will fuel your iteration cycle and help ensure each new batch of training data remains valuable. Most ML teams use a patchwork of tools and techniques to measure performance, such as:
Active learning strategies are based on uncovering the type of data that will improve performance most dramatically. To do this, it’s essential to learn why your model performs how it does and to diagnose errors quickly. Teams need to:
Measure performance metrics in one place with Model Diagnostics. These techniques will help you understand and diagnose model errors and position you to make more impactful improvements to your training data. Once this foundation is in place, you can start identifying and eliminating edge cases. (Read more: Stop labeling data blindly) In data-centric AI, it’s imperative to train your model to perform well against edge cases. You can relatively quickly train a model on common classes because there’s an abundance of data available for labeling, and these classes will show up regularly if you’re using a random sampling approach for gathering data. To surface edge cases, teams need to employ more sophisticated techniques for finding and prioritizing data for labeling. Model embeddings are a powerful tool to help understand your data and uncover patterns and outliers. (Learn more about embeddings.) With embeddings, you can:
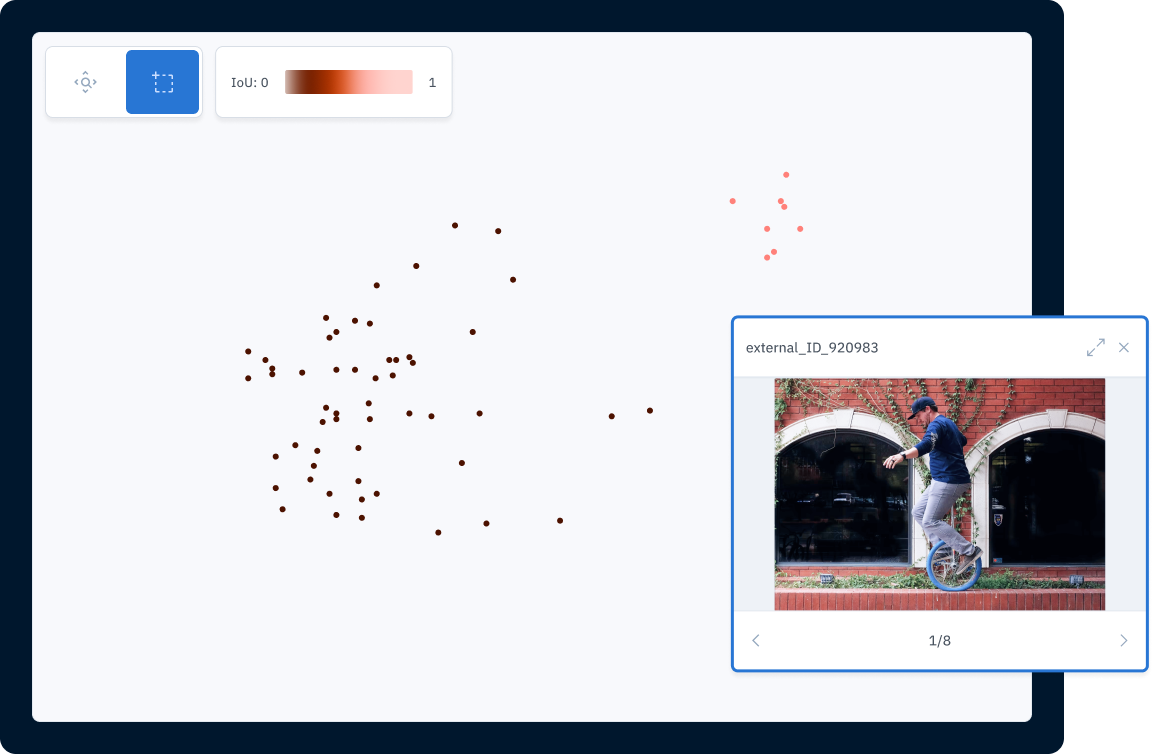
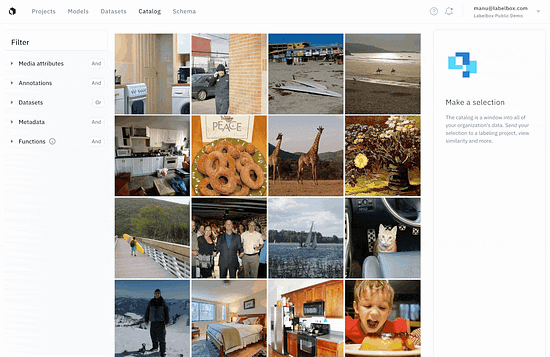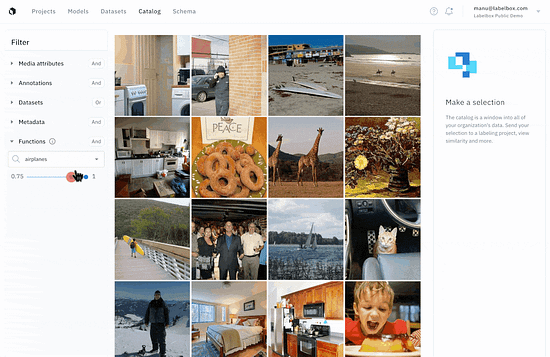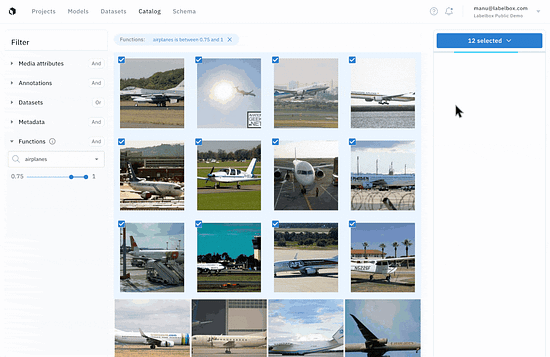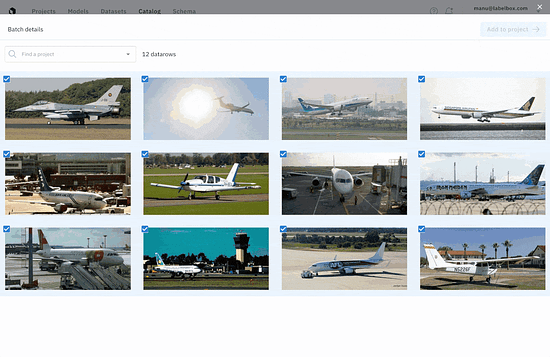
When looking at a selection of data in an embedding projector, visually similar examples will be clustered together. The example below illustrates how a collection of unicycles would show up as edge cases in a dataset mostly focused on bicycles. Using the embedding projector view, you can quickly identify edge cases to prioritize for future labeling iterations.
The embedding projector clusters visually similar data to help identify outliers. Find the right data fasterOnce you’ve diagnosed model errors and identified low-performing edge cases, you can start prioritizing high-value data to label. One of the biggest challenges of active learning at this point is sifting through the broader body of unstructured data available for labeling to actually find the data that’s most important. Unstructured data is inherently difficult to manage and search efficiently. Teams building ML products often need to access data from multiple locations and struggle seeing all their data in one place and understanding the true depth and breadth of their data. This complexity often stands in the way of teams identifying and prioritizing the most impactful data for labeling, leading to inefficient resource allocation and unnecessary labeling. (Read more: You’re probably doing data discovery wrong) To help with data discovery, teams must be able to:
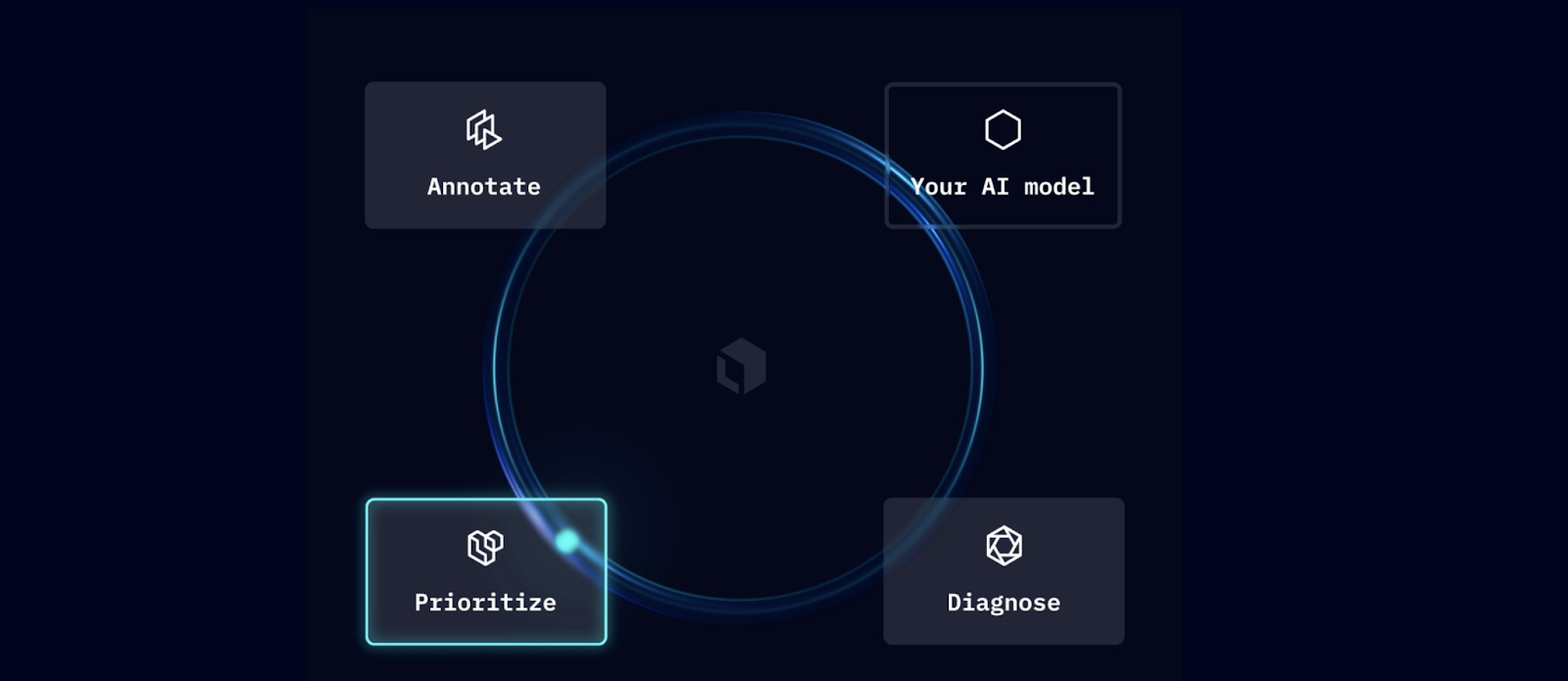
Labeling functions use embeddings to automatically label similar data to improve discoverability. These best practices will help you better understand what kind of unstructured data is available and help you find high-value data examples to train your model to perform well against edge cases. Active learning on LabelboxBy putting these active learning principles into practice, teams can create a more efficient data engine designed to diagnose model performance and prioritize high-value data for labeling. Labelbox is built around three pillars that help drive your iteration loop: The ability to quickly annotate data, diagnose model performance, and prioritize based on your results. All the tools you need for an active learning workflow are here in one place:
The Labelbox SDK powers the full active learning workflow, and you can easily get started with end-to-end runnable examples of common tasks. Manage data and ontologies, configure projects programmatically, and configure your pipeline for model-assisted labeling and model diagnostics all through the SDK. Labelbox is designed to be the center of your data engine, enabling a workflow of continuous iteration and improvement of your model. Learn more about active learning with Labelbox. P.S. We’re hiring!
Labelbox: Enabling the optimal iteration loop. You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2021 Jesus Rodriguez, Ksenia Semenova Unsubscribe
|

Older messages
🔬 Edge#145: MLOPs – model observability
Tuesday, November 30, 2021
plus an architecture for debugging ML models and overview of Arize AI
⚡️LAST DAY: 30% OFF⚡️
Monday, November 29, 2021
for the Premium subscription
👨🏼🎓👩🏽🎓 The Standard for Scalable Deep Learning Models
Sunday, November 28, 2021
Weekly news digest curated by the industry insiders
🙌 Subscribe to TheSequence with 30% OFF
Friday, November 26, 2021
Only four days left!
▪️▫️▪️▫️ Edge#144: How Many AI Neurons Does It Take to Simulate a Brain Neuron?
Thursday, November 25, 2021
A new research shows some shocking answers to that question
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your