📝 Guest post: The Original Open Source Feature Store - Hopsworks*
Was this email forwarded to you? Sign up here In TheSequence Guest Post our partners explain in detail what machine learning (ML) challenges they help deal with. This article reintroduces the core concepts of a Feature Store; the dual storage logic (online and offline) and how data scientists and ML practitioners can use APIs to establish a DevOps process for feature pipelines. IntroFeature stores for machine learning have become a key piece of data infrastructure for putting models in production. As with all key data infrastructure, there is demand for open source feature stores, and Feast has gained much attention as a framework for building your own feature store. But, if you need an open-source feature store that, out of the box, comes with its own offline and online stores, a user interface, enterprise-level security, high availability, and scalability, Hopsworks might be what you are looking for. Stand Alone Feature Store
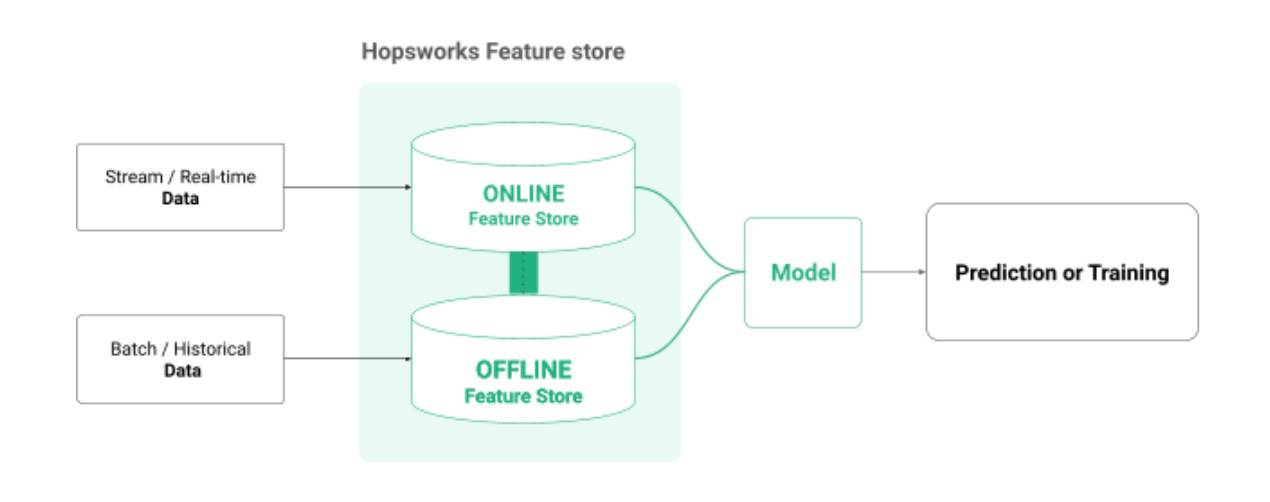
Hopsworks is widely used as a stand-alone feature store. A feature store provides Offline and Online Stores for large volumes of historical feature values and real-time access for current feature values. A feature store also provides an API for creating, reading, updating, and deleting feature values, and retrieving training data and feature vectors. Offline StoreHopsworks comes with its own offline store, based on Apache Hudi, but you can also use your own data warehouse/lake as an offline store. The offline store contains historical feature values and is used to create training data and provide features for offline batch scoring. Features stored in Hudi are known as cached features, while features stored in external stores are known as on-demand features, and the Hopsworks offline feature store can have a mix of cached and on-demand features. Maybe you already have all of your features in Snowflake or Redshift or Delta Lake, then you just need to mount them in Hopsworks as on-demand features. Or maybe you prefer the low-cost, high-performance cached features, that are stored in object stores in the cloud (S3, ADSL, GCS) or on commodity servers on-premises using the award-winning, HDFS-compatible, HopsFS file system. Online StoreHopsworks online feature store is built on RonDB, the only database optimized for feature store use cases. The online store contains the latest feature values and is used to provide feature vectors to deployed models at runtime. Any historical or context data that is used by your models to make predictions is typically stored as pre-engineered features in the online store, and retrieved using entity ids. For example, you might retrieve a customer’s recent history using a customer or session ID. Hopsworks Online Store provides sub-millisecond feature vector lookups, high throughput (scales to 10s of millions of reads or writes per second), high availability (with 7 nines availability in the telecom space), disaster recovery, elastic scalability, and MySQL support. The Hopsworks Feature Store (HSFS) API
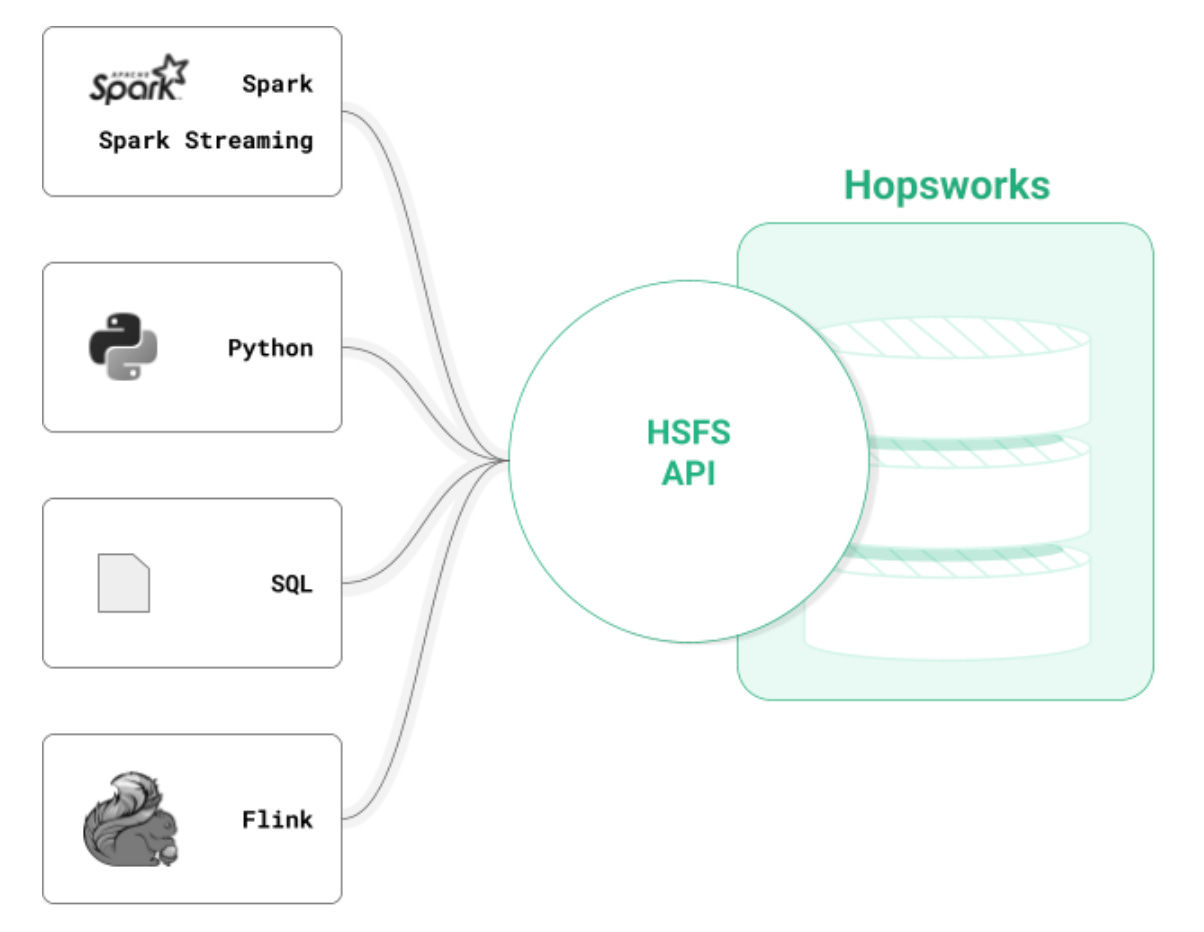
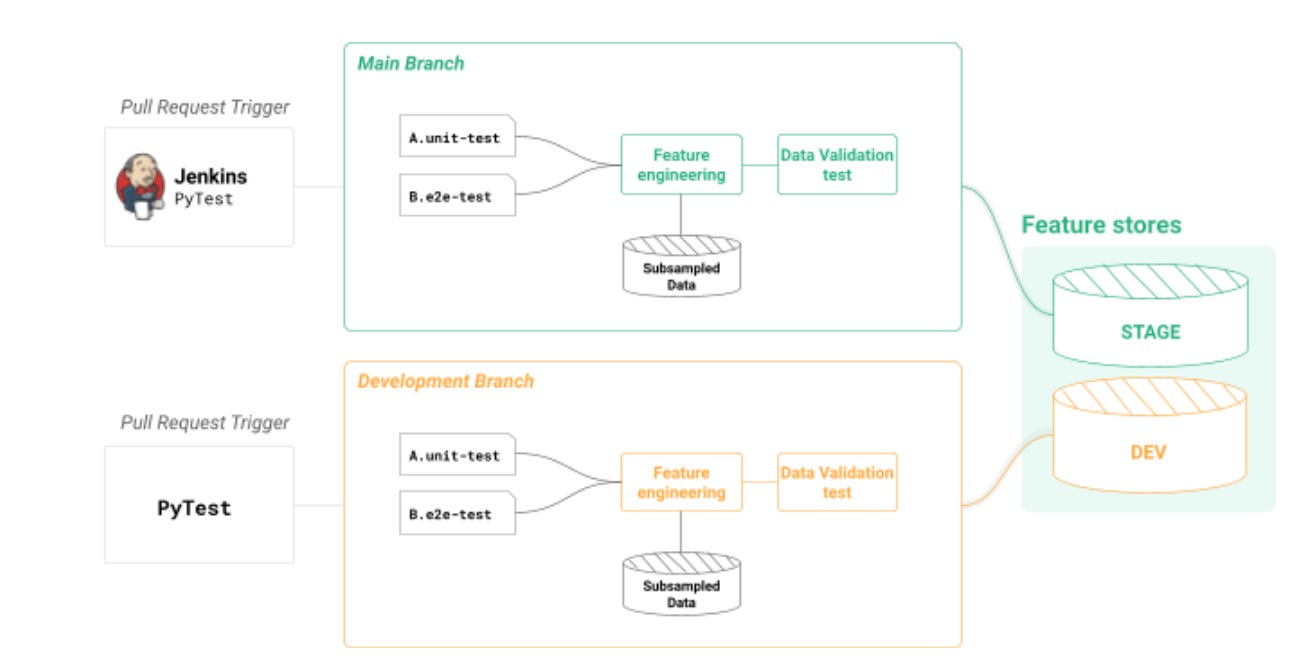
You interact with the Hopsworks Feature Store using the Hopsworks Feature Store (HSFS) API, with implementations in Python, PySpark, and Spark (Scala and SQL). For programs that run outside Hopsworks, you need to know the endpoint for Hopsworks, which feature store you are connecting to, and an API key to be able to connect. Python developers can create features in Pandas and write the Dataframe directly to the feature store. You can create training data by joining features together with Pandas-like commands, ensuring point-in-time correctness. When you have a deployed model, you can retrieve individual feature vectors from the feature store with a Python or Scala method call. If you have large volumes of data, you can use Spark to engineer your features and write them to the feature store as dataframes. If your features reside in a table in an external data warehouse or data lake, like Snowflake or Parquet on S3, respectively, you can use SQL to compute your features as aggregations. And if you need very fresh features, you can use Spark Streaming or Flink to compute your features on real-time data, HSFS provides a data-scientist-friendly Python API to create training data by joining features together (with no data leakage), filtering feature values, and applying transformations on features from the feature store before they are returned as training data. The transformation functions, defined in Python, are re-used both to create training data to transform feature vectors retrieved with the Online API when serving a model online. DevOps for Feature PipelinesOne of the challenges in writing feature pipelines is testing both the feature computation logic and also validating the data that passes through the pipeline. The HSFS API enables you to develop your features on any Python or Spark environment, and test those features in a local development environment as well as test them with a continuous integration platform, like Github Actions or Jenkins. Feature pipelines commonly include three different types of tests:
Open Source InstallationHopsworks consists of a number of open-source services, including HopsFS, RonDB/MySQL, Apache Spark, Apache Flink, Conda, Docker, Apache Hive, OpenSearch, Kafka, Prometheus, and Grafana. The recommended way to install Hopsworks is with a bash script that downloads all the software and configures the services. Hopsworks currently runs on Linux (Ubuntu, RHEL/Centos). If you have access to GCP or Azure command-line utilities, and you have privileges to create virtual machines, you can also create the virtual machines and install the platform in a single script. This script also allows you to stop, start, and suspend (GCP-only) your Hopsworks cluster, so you only pay for the compute you use. Managed PlatformLike most open-source projects, Hopsworks is also available as a managed platform on AWS, Azure, and soon GCP at www.hopsworks.ai. It is the quickest way to get started and try out Hopsworks. *This post was written by Hopsworks’s team. We thank Hopsworks for their ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2022 Jesus Rodriguez, Ksenia Semenova Unsubscribe
|

Older messages
🟢 ⚪️Edge#158: A Deep Dive Into Aporia, the ML Observability Platform
Thursday, January 27, 2022
Read it without subscription
📝 Guest post: Data Labeling and Its Role in E-commerce Today – Recent Use Cases*
Wednesday, January 26, 2022
No subscription is needed
🔄🔄 Edge#159: MLOps Full Recap
Tuesday, January 25, 2022
Dive in!
👷♀️🧑🏻🎓👩💻👨🏻🏫 The MoE Momentum
Sunday, January 23, 2022
Weekly news digest curated by the industry insiders
📌 Learn from 40+ AI experts at mlcon 2.0 ML dev conf <Feb22-23>
Friday, January 21, 2022
Our partner cnvrg.io is hosting another incredible virtual conference mlcon 2.0! It is FREE
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your