🔶◽️Edge#170: Superb AI, a DataOps Platform to Automate Data Preparation
This is an example of TheSequence Edge, a Premium newsletter that our subscribers receive every Tuesday and Thursday. On Thursdays, we dive deep into one of the freshest research papers or technology frameworks that is worth your attention. 💥 Deep Dive: Superb AI, a DataOps Platform to Automate Data PreparationDataOps, a term only popularized in the last few years, is a discipline that has been rapidly gaining in popularity as it helps organizations more effectively manage and govern their data. DataOps is the combination of practices that help an organization quickly get data into a state where it can be used for analysis, decision-making, and machine learning. It is an evolution of traditional data management practices and is brought about by the increased rate of data creation, the need for faster insights, and the growing popularity of machine learning (ML). One of the most important aspects of DataOps is the automation of data preparation. This is the process of getting data ready for analysis, often by cleansing it, transforming it into a specific format, and adding labels. Automating this process helps to ensure that data is always ready for use and eliminates the need for excessive manual steps, which can often be error-prone and time-consuming. Automated data preparation also allows analysts to focus on more complex tasks and makes it possible to quickly prepare data for analysis on demand. Superb AI is a company that has been developing a DataOps platform that automates the data preparation process for developing computer vision (CV) applications. Superb AI’s platform powers curation, labeling, and observability to help CV teams be more impactful. This allows CV engineers and scientists to quickly and easily prepare high-quality data for model experimentation and deployment without worrying about tedious and error-prone data preparation tasks. Let’s dive into the challenges of data preparation and how Superb AI deals with that. The Challenges of Data PreparationThere are many challenges when it comes to data preparation for CV. In particular, data preparation can be time-consuming and complex, requiring expertise from various roles. Three challenges stand out in particular:
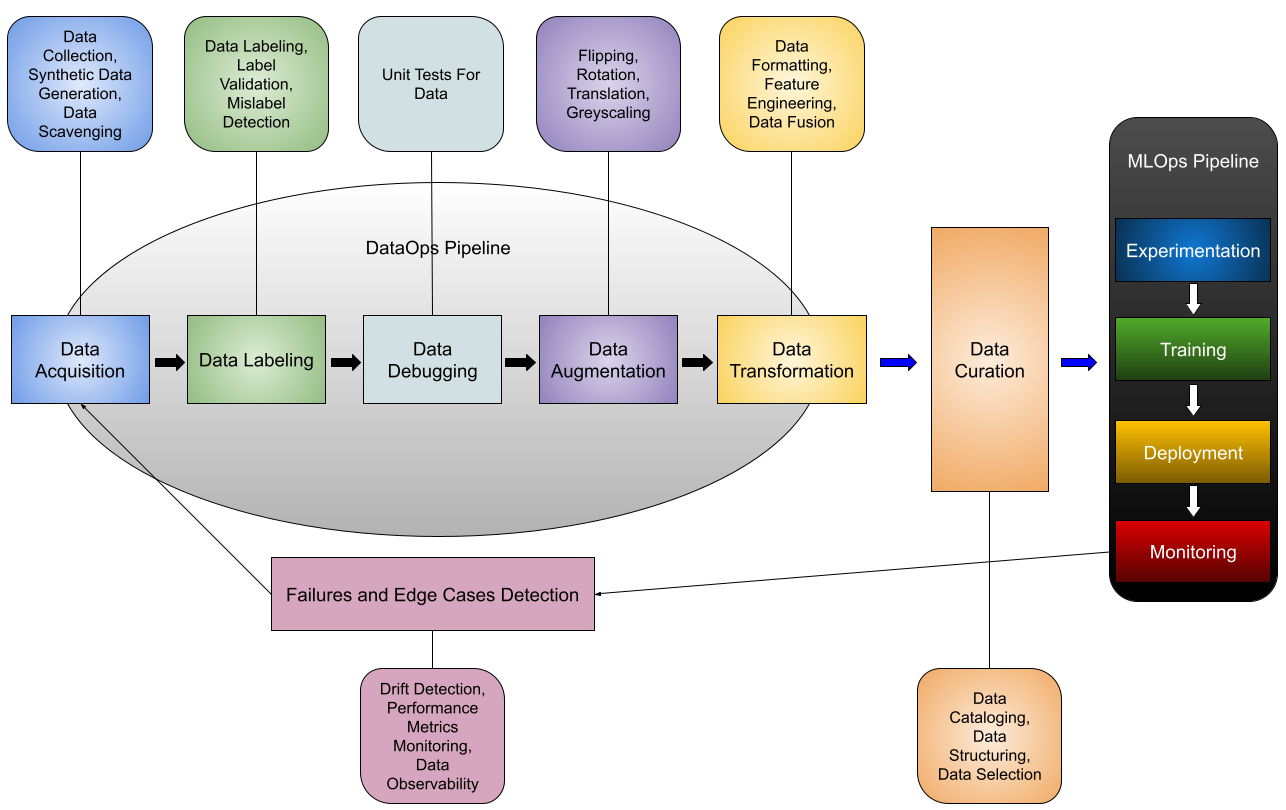
1. Curating High-Quality Data PointsData curation is the process of discovering, examining, and sampling data for a specific analytics/prediction task. It is an inevitable data management problem for any organization that wants to extract business value from data—otherwise, the adage “garbage in, garbage out” holds. In the context of ML, data curation entails collecting, storing, and archiving the data for future reuse. In the context of CV, data curation is massively under-rated as there is no streamlined method to understand what kind of data has been collected and furthermore, how to curate into a well-balanced high-quality dataset other than writing ETL jobs to extract insights. However, the value created through good data curation is tremendous. On the other hand, the mistakes that happen here will cost you dearly later on when low accuracy and high costs occur. Unfortunately, data curation remains the most time-consuming and least enjoyable work of data scientists and engineers. Data curation tasks often require substantial domain knowledge and a hefty dose of “common sense.” Existing solutions can’t keep up with volume, velocity, variety, and veracity in the ever-changing data ecosystem. Furthermore, these solutions are narrow because they primarily learn from the correlations present in the training data. However, it is pretty likely that this might not be sufficient, as you won’t be able to encode domain knowledge in general and those specific to domain curation, such as data integrity constraints. 2. Labeling and Auditing Data at Massive ScaleTraining CV models require a constant feed of large and accurately labeled datasets. The label accuracy is essential because the algorithm learns from ground-truth data, so the label quality ultimately defines the model quality. Therefore, any error induced by the data labeling process will negatively impact the model performance. However, this typically requires a considerable time and capital commitment, especially since most of the labeling and quality assurance is done manually by humans. Let's say you have a successful Proof-of-Concept project and now want to deploy models in production. As your project progresses, you'll have to constantly collect and label more data to improve the model performance. When you rely on brute-force manual labeling, the labeling cost increases linearly proportional to the number of labels created. What makes things even worse is that you will need exponentially more data and more money as your model performance improves. Unfortunately, your model performance plateaus as the number of labels increases. In other words, the marginal gain of your data diminishes to improve your model performance. 3. Accounting For Data DriftCV systems suffer from a major limitation that constrains their accuracy on real-world visual data captured at a specific moment in the past. They have a built-in assumption where the mapping function of input data used to predict the output data is assumed to be static. In practice, the visual data drifts over time because it comes from a dynamic, time-evolving distribution. This phenomenon is known as data drift. In these cases, predictions made by a model trained on historical data may no longer be valid, and the model performance will begin to decrease over time. As more ML applications move toward streaming data, the potential for model failure due to data drift exacerbates. There are various causes of data drift, such as upstream process changes (changing user behavior or changing business KPIs), data quality issues (systems go down due to increasing web traffic), natural drift in the data (temporal changes with seasons), and covariate shift (change in the relationship between features). Enter Superb AI
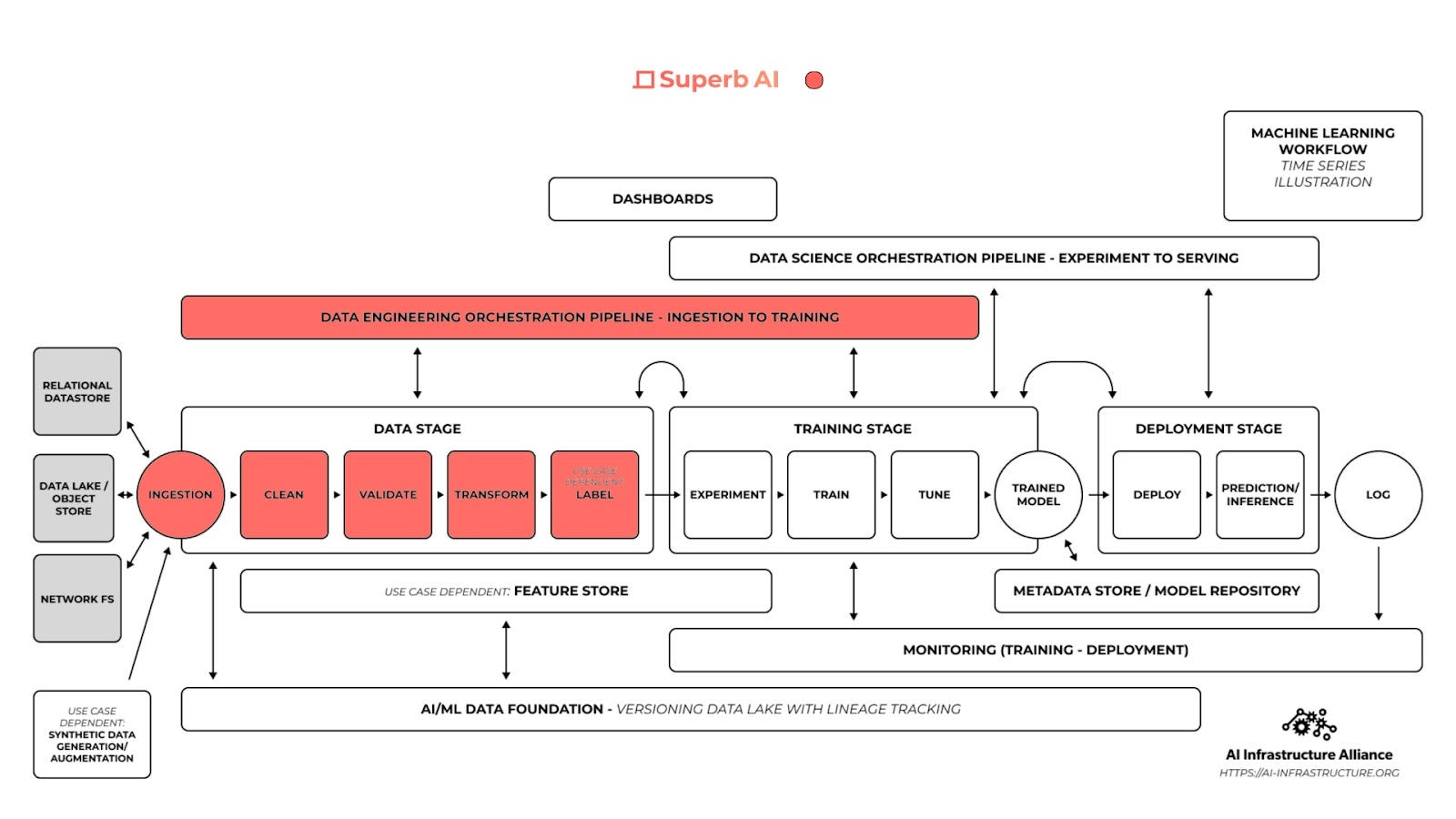
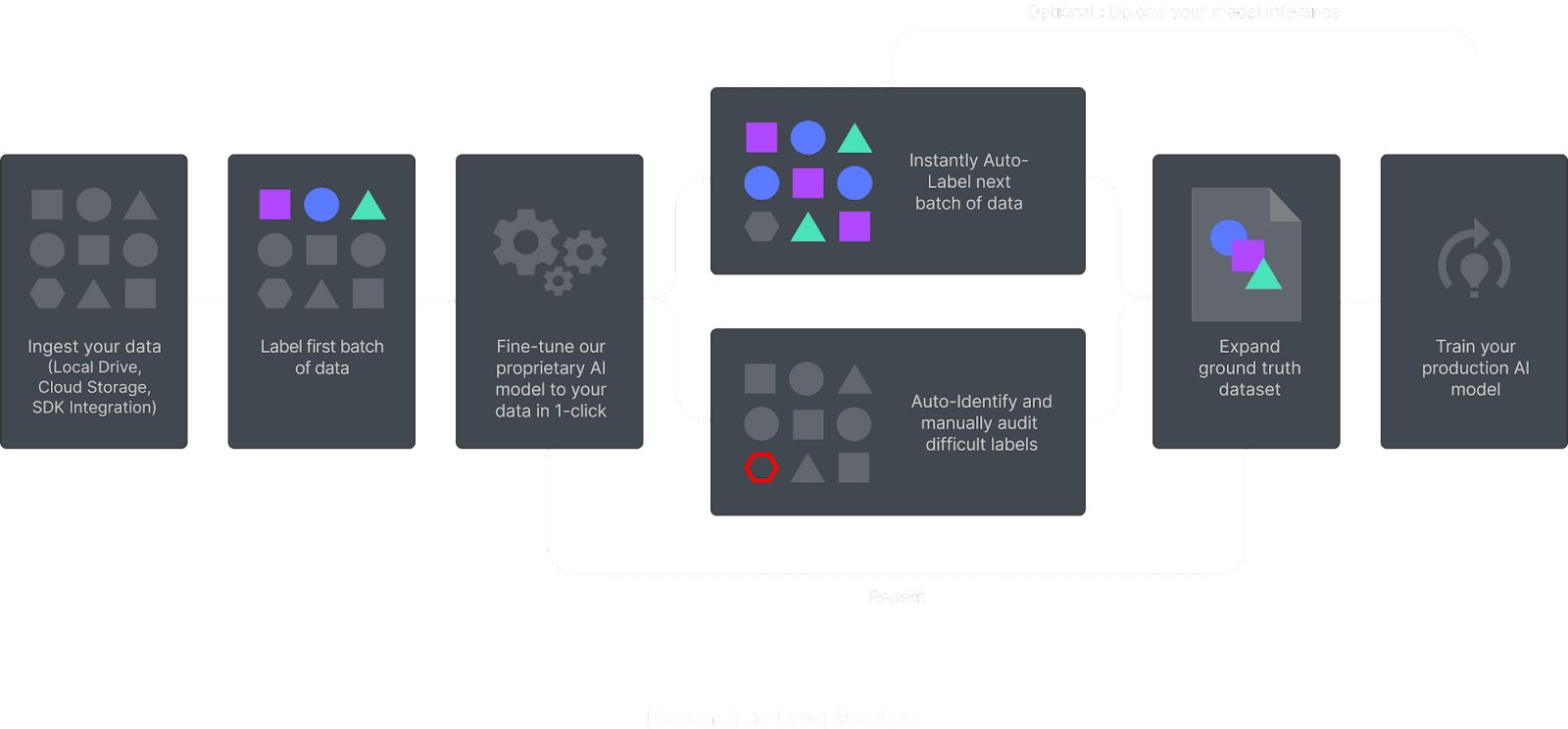
Superb AI is an ML DataOps platform that helps CV teams automate and manage the entire data pipeline: from data ingestion and data labeling to data quality assessment and data delivery. Initially, they want to challenge the notion that data labeling needs to be difficult and cumbersome. Superb AI Suite is a data labeling product that allows product leaders, CV engineers, and anyone else to scale up quickly and effectively by providing CV data management and labeling capabilities. The Suite offers a host of features from annotation and user analytics, a robust manual QA workflow, direct integration with cloud providers, and a robust CLI coupled with Python SDK. 1. Auto-Label TechnologyWith its no-code platform, Superb AI offers the ability to achieve ground truth with only a few hundred labeled images or video frames using its common objects auto-labeling system or its custom auto-labeling system. Superb AI grants clients the choice of using their own pre-labeled data to fine-tune a customized model (custom auto-label) or use one of Superb AI’s pre-trained models (common objects auto-label). In the latter process, Superb AI’s auto-label AI utilizes a plethora of open source, pre-trained datasets to label your model through a process known as transfer learning. These datasets are derived from a model or task similar to your project and automatically generate label annotations using its common objects auto-label AI. Clients are able to implement labels based on existing datasets, speeding up the overall process and streamlining the QA process.
Alternatively, custom auto-label (CAL) offers flexibility outside of transfer learning when building a model. Utilizing few-shot learning, Superb AI uses a small amount of labeled data (around 2,000 annotations per object class, though sometimes it can be much lower) from your own dataset to train a model. The amount of data needed to train your model is significantly less than that of other AIs, drastically reducing the time, manpower, and cost of labeling your dataset--and it doesn’t require a pre-trained model. CAL is a fantastic tool for newer companies in the CV space as well as those working on niche projects. If you already have a model running in production and are confident in its predictions, you can upload your own pre-labeled data and continue with your AI development lifecycle. 2. Active Learning ToolkitSuperb AI’s active learning toolkit allows teams to leverage uncertainty estimation and difficulty scoring to quickly and efficiently identify high-value examples for your model. Your dataset is audited by an uncertainty estimation AI, which can point out any areas of uncertainty that may indicate mislabeling. Showing only the labels this AI is unsure of reduces the time required to audit your dataset dramatically. After the first go-around, CV engineers can correct any discrepancies within their model, feed it through again, and maintain a higher level of accuracy. This is done multiple times until the CV model achieves a high level of precision. By leveraging auto-label in conjunction with uncertainty estimation, CV teams can scale the performance of their models more rapidly than ever.
3. DataOps CapabilitiesAlthough data labeling has been their bread and butter, Superb AI has started to form a thesis around building the DataOps platform for the modern computer vision stack in a data-centric AI development world. They are working on new DataOps capabilities such as an embedding store, image/video search, metadata analysis, data pre-processing, mislabel detection and debugging, workflow automation, data versioning/branching for data engineers, and more. These capabilities will enable data and CV engineers to understand the collected data, identify important subsets and edge cases, curate custom training datasets to put back into their models, and identify where the distribution changes occur in order to reduce the amount of labeling. We will follow these updates to tell you more. Using Superb AI To Build Efficient Active Learning WorkflowsActive learning is an ML training strategy designed to enable an algorithm to proactively identify subsets or elements of training data that may most efficiently improve performance. ML teams can leverage active learning principles and feature sets to automatically uncover gaps in their training data or models breadth. Rather than having to weigh all elements of a training data set equally, we can use active learning to identify the most valuable elements that will likely result in the model becoming more accurate. Superb AI’s core active learning technology is referred to as Uncertainty Estimation. It is an entropy-based querying strategy that selects instances within the training set based on the highest entropy levels in their predicted label distribution using underlying uncertainty sampling. The underlying technology for the Superb AI uncertainty estimation feature-set uses a patented hybrid approach of both Monte Carlo and uncertainty distribution modeling methods. This technology helps users identify and label data that the model has determined to have the highest output variance in its prediction. Such data points will form the training set for subsequent model iterations. Here are the two best practices for using their uncertainty estimation feature for active learning: 1. Efficient Data Labeling and Quality AssuranceOne of the most effective ways to use uncertainty estimation is labeling training data. First, a user can run Superb AI’s Auto-Label to obtain auto-labeled annotations and the estimated uncertainty. The uncertainty measure is shown in two ways:
2. Efficient Model Training by Mining Hard ExamplesAnother way to use uncertainty estimation is to efficiently improve production-level model performance. Most samples in a training dataset are “easy examples” and don’t add much to improving the model’s performance. It’s the rare data points with high uncertainty, or the “hard examples,” that are valuable. Therefore, if one can find “hard examples” from the haystack, the model performance can be improved much more quickly. ConclusionData is the most important component of any ML workflow that impacts the performance, fairness, robustness, and scalability of the eventual ML system. Unfortunately, the data work has traditionally been underlooked in both academia and industry, even though this work can require multiple personas (data collectors, data labelers, data engineers, etc.) and involve multiple teams (business, operations, legal, engineering, etc.). Using such ML DataOps platforms as Superb AI helps automate data preparation at scale and make building and iterating on datasets quick, systematic, and repeatable. You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2022 Jesus Rodriguez, Ksenia Semenova Unsubscribe
|

Older messages
🔁 Edge#169: Understanding CycleGANs
Tuesday, March 1, 2022
In this issue: we explain CycleGANs; the original CycleGAN paper; and GAN library Mimicry.
🧠 Meta AI Ideas for Autonomous Intelligence
Sunday, February 27, 2022
Weekly news digest curated by the industry insiders
📌 Register for the inaugural ML observability summit featuring Chime, DoorDash, Etsy, Kaggle & more…
Friday, February 25, 2022
Awesome lineup! Join us on March 29
🏆 Edge#168: OpenAI’s GPT-3 Inspired Model can Solve Problems from the Math Olympiads
Thursday, February 24, 2022
Formal mathematics has long been considered one of the toughest challenges for deep learning. OpenAI shows that we are a step closer to a solution
🙌 Why subscribe to TheSequence?
Wednesday, February 23, 2022
Hello there! Important question How do you stay up-to-date with the fast-moving AI&ML industry? We heard that question a lot. Some people thought that was impossible. Then we started TheSequence.
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your