|
Hey 👋, We could consider this a follow-up to my previous post on web3. But this one goes more into the details that I just mention there. TLDR; web3 development is not so different from web2 development. Feel free to reply with your experience. I'd love to hear from other people. IntroductionIn February, I started a new role as a software engineer at DFINITY Foundation. DFINITY is building a blockchain similar to Ethereum; it’s called the Internet Computer or IC for short. In the Internet Computer, you can build smart contracts (or canisters), computer programs that run in the blockchain. These blockchain technologies enable the new trends of NFTs, DAOs, and cryptocurrencies.
I didn’t know much about web3 and smart contracts when I first started. To help others understand the technology, I would like to share the experience of building my first decentralized application. A decentralized application (dapp for short) is an application that runs on a blockchain network instead of a standard server.
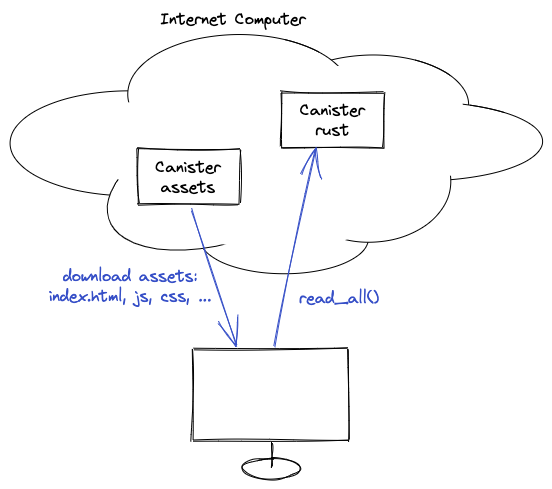
This article is based on building a dapp on the Internet Computer (or IC). It might be different in other blockchains, but the idea and concepts should be very similar. “Hello, World” DappThe preferred tutorial is a “Hello, World.” In this tutorial, we learn about canisters (or smart contracts). We also install the command-line tool “dfx” to help us in most devops tasks. A part that I found very cool is that with “dfx,” we run an Internet Computer replica on our computer. It’s as if we would run a full AWS copy to work with AWS. I used the AWS comparison because it’s the best way to understand the Internet Computer. In most applications, we use a cloud provider (such as AWS) to deploy our frontend and backend. Yet, in this tutorial, we deploy them to canisters in the IC. Imagine a canister as a small virtual machine running in the cloud. The “Hello, World” teaches us how to deploy the frontend and the backend to this “cloud provider.” It also teaches us how the frontend talks with the backend. Note: There is a huge difference between AWS and IC, but they both share the functionality of a cloud provider. My Survey DappThe example application is a survey management tool where users can create surveys, select, and reply to one. There are no login or registration capabilities; everybody works on the same surveys and data. My Survey Dapp: Frontend DeploymentI was surprised to see how easy it was to deploy a frontend to the “IC Cloud.” The “dfx” tool works perfectly and helps you do most of the heavy lifting. In my case, I decided to go for a Svelte frontend. This is because the application I am working on is built on Svelte, and I wanted to also learn about Svelte at the same time. But it does not change anything that I explain here. The “dfx” cli creates and then reads a configuration file written in JSON: "dfx.json." Let’s take a look at the part of the configuration related to the frontend: "frontend": {
"frontend": {
"entrypoint": "src/frontend/public/index.html"
},
"source": [
"src/frontend/public"
],
"type": "assets"
}
The first key, “frontend,” is how “dfx” refers to this part of the project. - “type” defines the kind of project. It can be a smart contract built on Rust, Motoko, static assets, or others. In the frontend example, the canister is of type “assets” because we use it as a static web server.
- “source”: since it’s of type “assets”, we need to tell “dfx” where the assets are located. My Svelte configuration builds the assets inside the “public” folder.
- “frontend.entrypoint”, the assets have a default entry file, like a static web server uses “index.html. In this case, we tell it that the default asset is the “index.html” inside the “public” folder.
Once this frontend is deployed, the canisters work like a server of static files. My Survey Dapp: Backend DeploymentHere comes the fun part of the IC. The canister also works as a backend, but the functionality is different from a standard server. This is where AWS and IC are most different. Canisters on the IC are not standard servers, and we cannot choose what kind of server we want or in which language to write them. Canisters run Web Assembly (wasm) code. Therefore, our code must be compiled to wasm and then deployed to the IC. But, you might ask, what about the data? Where is it stored? The data is stored along with the code in the same canister in memory: no more MongoDB, PostgreSQL. Instead, we keep the data in memory and access it like a normal variable. The DFINITY Foundation has built a programming language to help developers build applications, compile them to wasm and deploy them to the IC easily: Motoko. I chose Rust for my backend, and this is how the data is stored in my canister: static SURVEYS: RefCell<Vec<Survey>> = RefCell::new(Vec::new());
static NEXT_USER_ID: Cell<u64> = Cell::new(0);
It might seem fancy if you don’t know Rust (I am learning, and it still looks very fancy to me), but in the end, these are just variables that are read and changed. Therefore, the code has everything that we need to run the backend of our dapp: how to access data and the business logic. Let’s look is the “dfx.json” part of the backend: "surveys": {
"type": "rust",
"package": "surveys",
"candid": "src/surveys/surveys.did"
},
- “type”: tells “dfx” what kind of canister, in this case, a “rust” canister.
- “package”: is the name of the folder.
- “candid”: is the file with the interface, which we discuss next.
As you see, different “types” of canisters have different properties. My Survey Dapp: Backend InterfaceIn a regular backend, we use endpoints. The most popular patterns are either REST or GraphQL. These endpoints expose the functionality of the backend to the frontend. In IC, the canisters expose functions to read and update data. The same way a class or a module exposes some methods or functions to interact with it. How this interface is defined depends on the technology. With Motoko, we need less work, but with Rust, we need to define the interface with a file of type “candid.” Then in the code, we mark the interface functions with a macro. The candid file looks like typescript types to me: // other type definitions
service : {
"read_all": () -> (vec Survey) query;
"create": (title: text, questions: vec text) -> (Survey);
}
My Survey Dapp: NetworkingHow does the backend call these functions? The simple answer is through HTTP requests. Yet, the requests have a particular content type called CBOR. See an example from the Dev Tools below: To help integrate with the IC, the SDK team at DFINITY has built libraries that developers can install and use. They take care of serializing and deserializing the data and certifying that it comes from the canister. The libraries go as far as to read the candid files and create a javascript object with the same interface as the canister. For example, in our case, it exposes a function “read_all” and “create.” For example, if I want to read all the surveys when the component is mounted, this is the code: // createActor is built by “dfx” and uses DFINITY’s SDK
surveysActor = createActor(
canisterId,
{ agentOptions: { host: 'http://localhost:8000' } },
);
// call the method “read_all” in the canister
surveys = await surveysActor.read_all();
The method read_all from the surveysActor calls the function read_all in the Rust code: #[query]
fn read_all() -> Vec<Survey> {
SURVEYS.with(|surveys| {
return surveys.borrow_mut().clone();
})
}
The backend has been transformed into a module to be used from the frontend. My Survey Dapp: Canister IdsWe deploy both the backend and frontend to canisters; how do they find each other? Each canister has an id, which we use to make requests. In production, they all live in the same domain: "ic0.app". Therefore, to access a frontend dapp stored in a canister in the IC, the URL is “<canister_id>.ic0.app”. The canister id can be added as an environment variable and used when creating the actor mentioned in the previous section to connect to the backend. The code added by dfx generate expects this environment variable; here is the specific line. In my sample app, this is done in the rollup configuration in a function called “initiCanisterIds” that reads a file that “dfx” creates when deploying the canisters with the ids it has created. My Survey Dapp: Development ModeSince my code runs in canisters, do I need to redeploy every change I make to test it during development? In the backend, yes (for now); in the frontend, we can set a development server with hot reloading. Remember that “dfx” runs a local replica of the IC where the canisters are deployed. Our backend is in this local replica and runs by default on “localhost:8000”. Yet, our development server might be running in another host, let’s say “localhost:5000”. We can specify a host when creating an actor with the SDK to differentiate ports. // notice the “host” property
surveysActor = createActor(
canisterId,
{ agentOptions: { host: 'http://localhost:8000' } }
);
This way, the actor knows that instead of making a relative call, as it happens in production, it needs to change the host. This speeds up development with a faster feedback loop when building the frontend. There is a long way, from the “Hello, World” tutorial, to a fully-size and production-ready application, like in any other tutorial. But the concepts are the same. What I found most surprising was that the data is stored in memory. We store it as we use it in variables. Data modeling is still important because we need to ensure we have easy access to read and update as the data scales. Therefore, new best practices might appear. The same way new best practices exist for Amazon DynamoDB or Google Firestore. Think of a canister as a lambda function with memory. Actually, more than just one function, maybe a “lambda class” 😂? Canisters can also talk to each other through the same interface they expose. Therefore, we might consider using multiple ones for our application in a microservices fashion. This was my first experience with web3 technology. That’s why I tried to compare the new concepts to ones I already know, like AWS and lambda. But I didn’t yet talk about the new functionalities that dapps offer. The fact that the canisters run in a decentralized blockchain network where the data is public and immutable offers functionality that no other cloud provider can match. These new functionalities created the new world of NFTs, DAOs, and cryptocurrencies. And who knows what else awaits us.
If you like this post, consider sharing it with your friends on twitter or forwarding this email to them 🙈 Don't hesitate to reach out to me if you have any questions or see an error. I sincerly appreciate it. And thanks to Sebastià for reviewing this article 🙏
|