📝 Guest post: Active Learning 101: A Complete Guide to Higher Quality Data* (part 2)
Was this email forwarded to you? Sign up here In this article, Superb AI’s team explains the benefits of building an active learning flow for your computer vision project. In Active Learning 101: A Complete Guide to Higher Quality Data (Part 1), they outlined the basics of Active Learning, how it’s different from other types of computer vision, and its popular subtypes. If you haven’t already, we suggest starting there. A Quick RecapBuilding a machine learning model can be cumbersome, with data labeling being the most time-consuming aspect of the entire process. However, data annotation is arguably one of the most important factors in building your model, and the strategy you take determines its outcome. Choosing the wrong methodology could squash your entire results. Finding the appropriate workflow for building out data annotations, thus choosing the correct model for your project, will largely determine its outcome. And knowing how much time this step alone takes presents a considerable hurdle for ML teams, especially those that are smaller and lack the resources to carry out robust operations. Active learning then alleviates the need for large data labeling teams and involves a more automated workflow. Active learning is not a one-size-fits-all approach to model training. Depending on the data you’re working with and the end goal, a machine learning practitioner might want to choose one strategy over another. Random sampling, for example, grants each piece of data an equal likelihood of being chosen for labeling without any human influence. The purpose here is to avoid bias so that the results of the model are not skewed one way or another. In other instances, we can adapt active learning workflows to a lack of data samples in membership query synthesis. Here, we use basic editing tools to create new data samples. Need an image sample that’s close up? Use the cropping tool. Or maybe your data lacks images in a sunny setting; use the brightening tool. We also discuss pool-based sampling, which uses the labels with the lowest accuracy scores to tweak your model. And in stream-based selective sampling, your model uses its confidence threshold to dictate which pieces of data should be labeled. Knowing the basics of active learning and the different approaches is paramount in the project planning phase. In addition, understanding important measurements, such as accuracy, precision, and recall – and knowing how and when your data’s performance drops off are paramount. Active learning is best used in models trained to complete predictable, repeatable tasks and does not work as well for those who learn as they go along. In a phenomenon known as reinforcement learning, your model modifies its behavior based on the mistakes it makes, i.e., a robot learning to walk will almost certainly fall before perfecting this action. Active learning is best avoided when these types of patterns are desired. And although the cost savings and time reduction in active learning models make it a desirable training method for many ML teams, the technology isn’t necessarily there. Adapting a company’s current software to be compliant with active learning protocols is often more troublesome than it’s worth, so they may opt-out of this route. The Superb AI Active Learning Toolkit
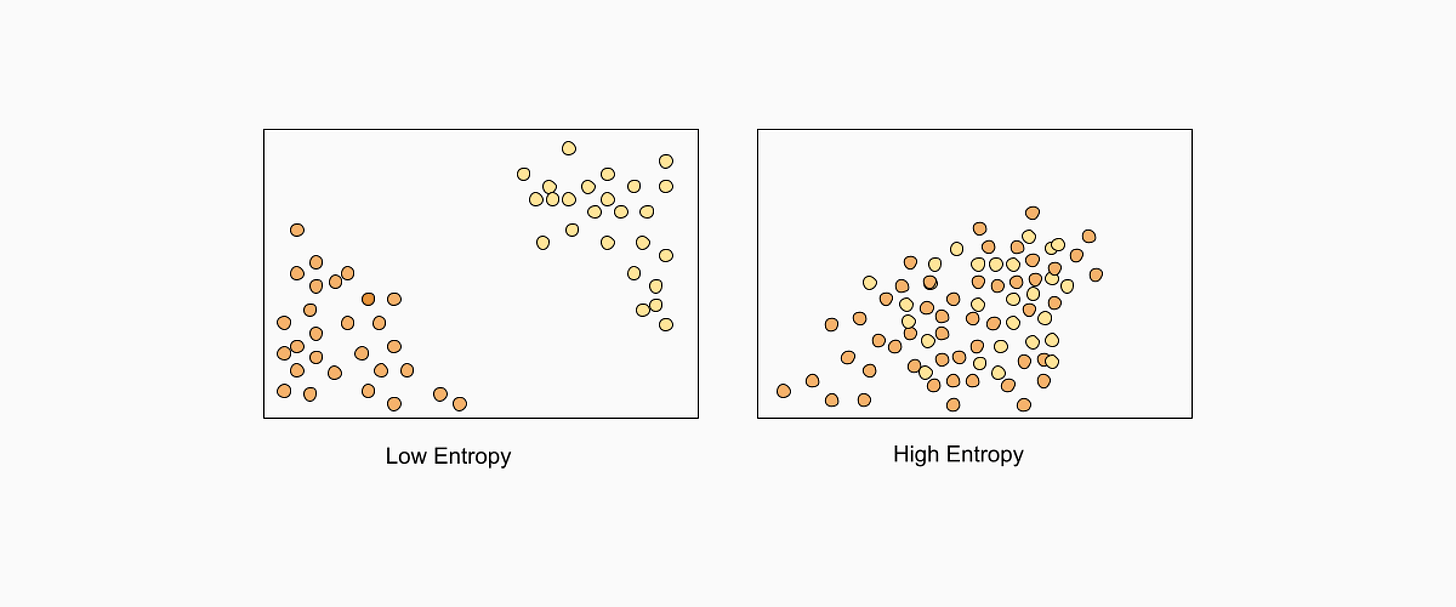
In traditional machine learning, data labeling is a highly manual process carried out by human annotators, which are then responsible for querying the effectiveness of a model by hand or with limited tools. On the other hand, active learning combats this bottleneck by implementing an algorithmic approach designed to proactively identify subsets of training data that most efficiently improve performance. Superb AI leverages active learning to identify gaps in the training data. Rather than weighing each piece of data equally, active learning works to find the most valuable data that will lead to higher accuracy and efficiency. Uncertainty EstimationDeveloping a robust active learning toolkit relies heavily on an auto-label AI to accurately annotate data outside of your manually labeled ground truth set. When approaching automation, one must look at its ability to assess an image fairly and apply a precise label; otherwise, this tool is rendered useless. Various measurement techniques can be applied to examine a label’s validity, but not all yield the most promising results. Least confidence, for example, is a technique in which your model selects the data it is least optimistic about to be labeled. It’s highly popular and performs well for many teams, but a common problem is its tendency to predict a high confidence level in error when the model has been overfitted to the training data. Alternatively, examining the uncertainty levels of your data provides a statistical measurement of trust. In essence, how uncertain your model is of a piece of data can tell an ML professional where improvement needs to be made. Though automating the labeling process is a huge win in machine learning, it poses the question of accuracy. If a machine annotates the remaining data, how do we know it can be trusted? Superb AI’s core active learning technology is rooted in the concept of uncertainty through its patented Uncertainty Estimation Tool, which is applied to auto-labeled datasets within each model. The Uncertainty Estimation tool works as an entropy-based querying strategy that selects instances within the training set based on the highest entropy levels in their predicted label distribution, using our underlying uncertainty sampling. This strategy uses a patented hybrid approach of both Monte Carlo and uncertainty distribution modeling methods. Entropy: What it is and How it Fuels Active Learning 🚀
To build an effective machine learning model, data must be diverse and represent highly possible, yet different, outcomes. We measure these dissimilarities using something known as entropy, which is used to identify pieces of data that may cause our model the most trouble or confusion. Highlighting differences and encouraging diverse examples in an active learning model leads to better results and faster adoption of the desired behavior. We use the principle of uncertainty sampling to highlight which pieces of data to use for querying. In essence, our uncertainty estimation and active learning feature set aims to identify labeled data that the model has determined to have the highest output variance in its prediction. High output variance refers to the fluctuating predictions a model may make based on its data. As part of the training process, it is essential to minimize these variances or differences and tighten the model’s predictions through a querying strategy known as variance reduction. Without eliminating high instances of variances, our final model will fail to make consistent and actionable predictions upon implementation. We apply these principles in the Superb AI Suite using our Uncertainty Estimation tool. With each iteration of CAL, a difficulty score of easy, medium, or hard is administered to calculate its information usefulness. An image that Custom Auto-Label found more challenging to annotate accurately will receive a higher difficulty score than its easily identifiable counterparts, rendering its predictions more uncertain. Images that present a greater obstacle for our auto-label technology to identify also pose the highest value by showcasing which types of examples can lead to better performance. On the contrary, images labeled as more difficult also strongly correlate with being incorrect. ML professionals can then focus on these individual labels and correct them, thus improving model performance. Monte-Carlo Sampling and Dropout
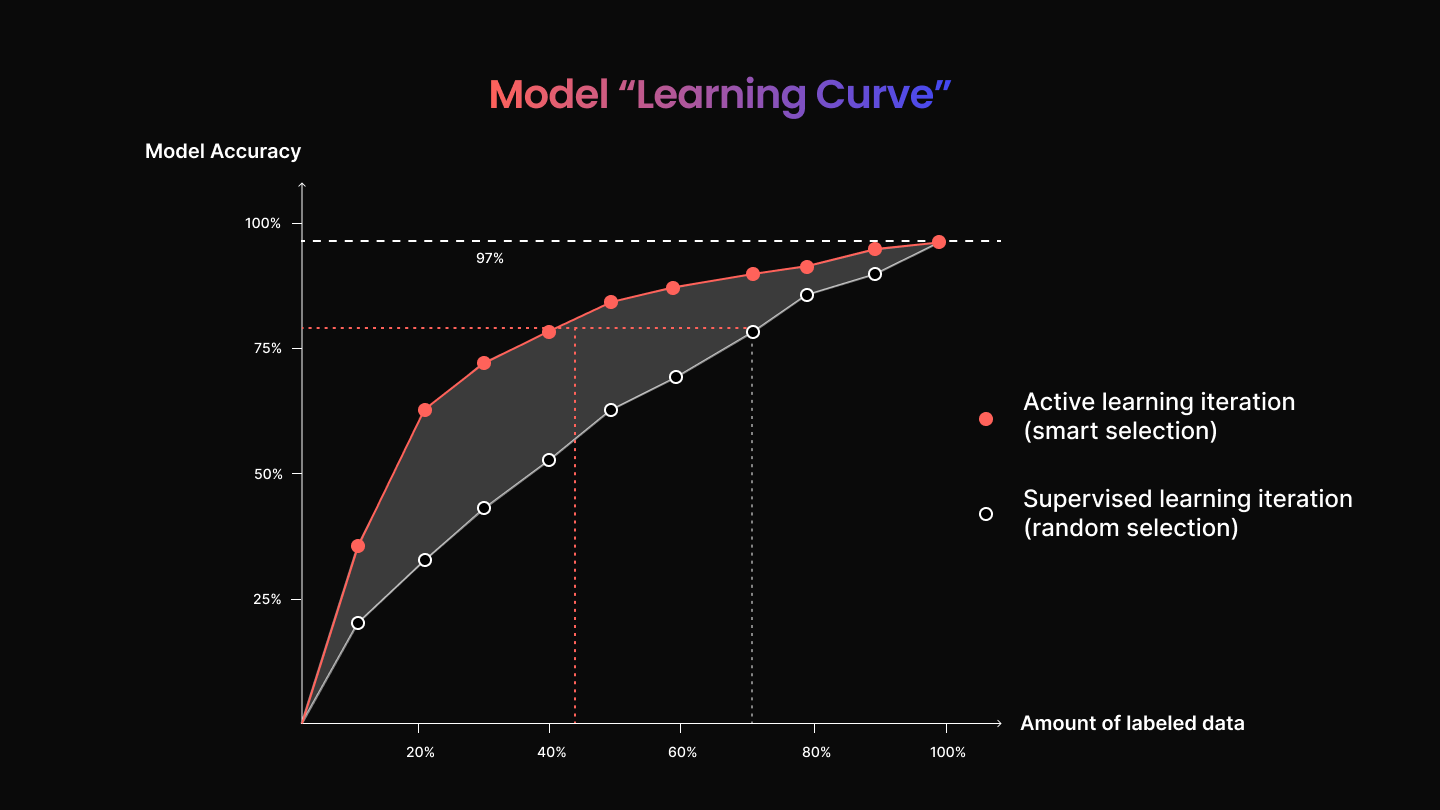
The Superb AI active learning tool kit relies heavily on uncertainty estimation and difficulty scores to enhance individual ML models. This is done through a method known as Monte-Carlo sampling, which aims to establish multiple model outputs for each data input through random selection. After each iteration, uncertainty levels are then calculated. But how do we continuously input the same data samples to paint a better picture of uncertainty? ML engineers will often implement the use of dropout layers. To do this, one must theoretically “switch” different pieces of data on and off for our model to evaluate. With a less predictable data input, our model becomes more sophisticated in making predictions. With Superb AI, your team can filter different data tags, such as your ground truth and validation sets, in multiple combinations to display different levels of uncertainty. Then, using these pieces of data with higher uncertainty, you can once again retrain your model to yield higher performance and accuracy. For a closer look at a real application please continue reading here.The Active Learning AdvantageThe above experiment showcases how using active learning increases the efficiency and accuracy of your project over time. But how does it compare to traditional methods, and how can we display this in our model? Taking this experiment a step further, we can unbiasedly create an additional subset of training data using random sampling. To carry this out, we need first to form a control group that is the same size as our GT2 dataset identified by active learning and then retrain a custom auto-label. The difference here is that the data applied to the control group will be randomly selected rather than strategically assigned. We’ll repeat the same steps above, labeling our CAL as Control to easily separate it from past iterations and then train the model. Once applied, Superb AI can calculate the efficacy of this model’s iteration.
You’ll find that the results from our control group show improvement over our initial iteration of custom auto-label, with increases in precision and recall and an efficiency boost score of 5.1x. This is to be expected, as our initial dataset only utilized our ground truth labels. However, the difference is even more significant when compared to our CAL 2 model using active learning. Examining these results, you’ll see that precision and recall improved in the majority of classes. From these findings, we can conclude that an active learning workflow not only enhances, but also accelerates model training and accuracy. The TakeawayImplementing active learning into your ML workflow is a sure-fire way to expedite and improve the model training process over traditional methods. Approaching your data intelligently and leveraging the most valuable examples to train your model leads to faster and more quantifiable improvements. The Superb AI Suite demonstrates how active learning and custom auto-label can be a superpower for your ML team and save you time and money. Because of how easy it is to edit and retrain your model, the Superb AI active learning toolkit is well-equipped to adapt to your business needs as they become greater and more complex. Stay tuned for our Active Learning 101: Part 3 to learn more about best practices, customer success stories, and what’s next for Superb AI. For a closer look at a real application please continue reading here. *This post was written by Tyler McKean, Head of Customer Success at Superb AI, and originally posted here. We thank Superb AI for their ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2022 Jesus Rodriguez, Ksenia Semenova Unsubscribe
|


Older messages
🧙🏻♂️ Edge#188: Inside Merlin, the Platform Powering Machine Learning at Shopify
Thursday, May 5, 2022
The eCommerce giant published some details about the platform powering its ML workflows
📝 Guest post: Testing feature logic, transformations, and feature pipelines with pytest*
Wednesday, May 4, 2022
Operational machine learning requires the offline and online testing of both features and models. In this guest post, our partner Hopsworks shows you how to design, build, and run offline tests for
🥢 Edge#187: The Different Types of Data Parallelism
Tuesday, May 3, 2022
In this issue: we overview the different types of data parallelism; we explain TF-Replicator, DeepMind's framework for distributed ML training; we explore FairScale, a PyTorch-based library for
📌 Event: SuperAnnotate’s Free Webinar Series on Automated CV Pipelines is Live
Monday, May 2, 2022
Join the Upcoming Session
🔎🧠 Improving Language Models by Learning from the Human Brain
Sunday, May 1, 2022
Weekly news digest curated by the industry insiders
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your