📝 Guest post: Fast Access to Feature Data for AI Applications with Hopsworks*
Was this email forwarded to you? Sign up here In this article, Hopsworks’s team dives into the details of the requirements of AI-powered online applications and how the Hopsworks Feature Store abstracts away the complexity of a dual storage system.
Enterprise Machine Learning models are most valuable when they are powering a part of a product by guiding user interaction. Oftentimes these ML models are applied to an entire database of entities, for example users identified by a unique primary key. An example for such an offline application, would be predictive Customer Lifetime Value, where a prediction can be precomputed in batches in regular intervals (nightly, weekly), and is then used to select target audiences for marketing campaigns. More advanced AI-powered applications, however, guide user interaction in real-time, such as recommender systems. For these online applications, some part of the model input (feature vector) will be available in the application itself, such as the last button clicked on, while other parts of the feature vector rely on historical or contextual data and have to be retrieved from a backend storage, such as the number of times the user clicked on the button in the last hour or whether the button is a popular button. Machine Learning Models in ProductionWhile batch applications with (analytical) models are largely similar to the training of the model itself, requiring efficient access to large volumes of data that will be scored, online applications require low latency access to latest feature values for a given primary key (potentially, multi-part) which is then sent as a feature vector to the model serving instance for inference. To the best of our knowledge, there is no single database accommodating both of these requirements at high performance. Therefore, data teams tended to keep the data for training and batch inference in data lakes, while ML engineers built microservices to replicate the feature engineering logic in microservices for online applications. This, however, introduces unnecessary obstacles for both Data Scientists and ML engineers to iterate quickly and significantly increases the time to production for ML models:
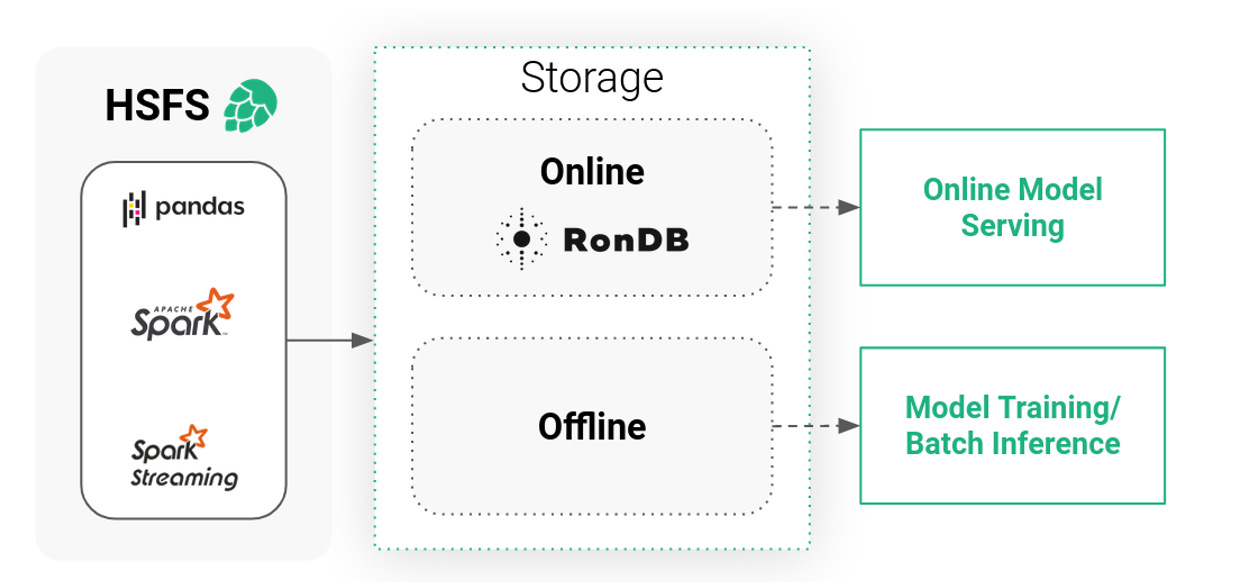
Hopsworks Feature Store: A Transparent Dual Storage SystemThe Hopsworks Feature Store is a dual storage system, consisting of the high-bandwidth (low-cost) offline storage and the low-latency online store. The offline storage is a mix of Apache Hudi tables on our HopsFS file system (backed by S3 or Azure Blob Storage) and external tables (such as Snowflake, Redshift, etc), together , providing access to large volumes of feature data for training or batch scoring. In contrast, the online store is a low latency key value database that stores only the latest value of each feature and its primary key. The online feature store thereby acts as a low latency cache for these feature values. In order for this system to be valuable for data scientists and to improve the time to production, as well as providing a nice experience for the end user, it needs to meet some requirements:
The Hopsworks Online Feature Store is built around four pillars in order to satisfy the requirements while scaling to manage large amounts of data:
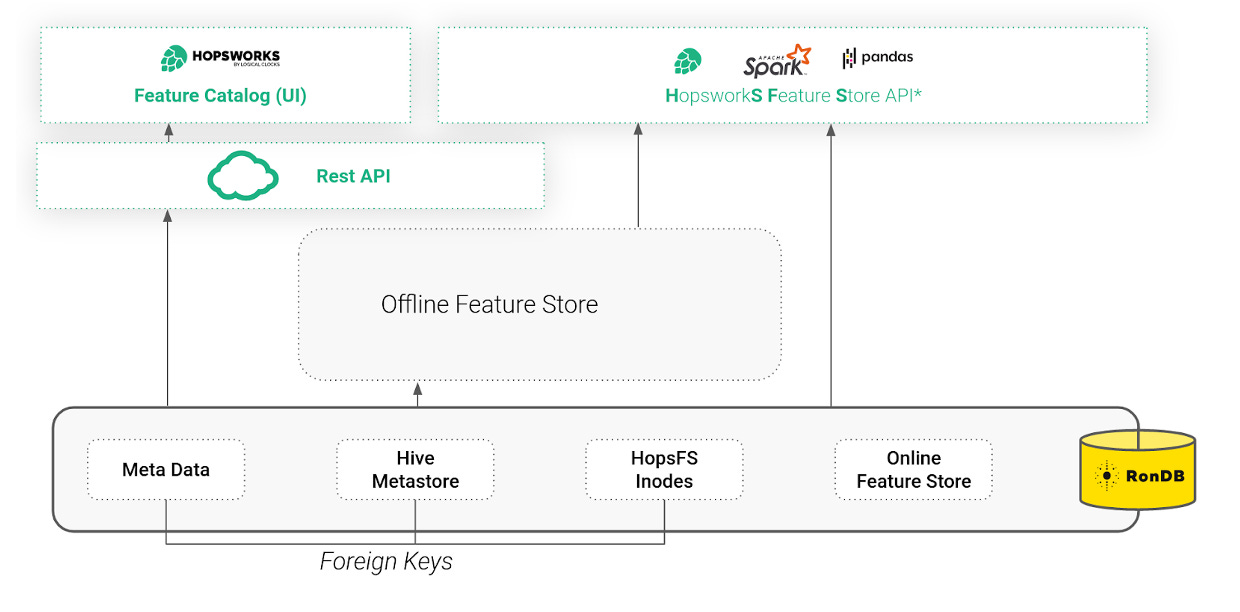
RonDB: The Online Feature Store, Foundation of the File System and MetadataHopsworks is built from the ground up around distributed scaleout metadata. This helps to ensure consistency and scalability of the services within Hopsworks as well as the annotation and discoverability of data and ML artifacts. Since the first release, Hopsworks has been using NDB Cluster (a precursor to RonDB) as the online feature store. In 2020, we created RonDB as a managed version of NDB Cluster, optimized for use as an online feature store. However, in Hopsworks, we use RonDB for more than just the Online Feature Store. RonDB also stores metadata for the whole Feature Store, including schemas, statistics, and commits. RonDB also stores the metadata of the file system, HopsFS, in which offline Hudi tables are stored. Using RonDB as a single metadata database, we use transactions and foreign keys to keep the Feature Store and Hudi metadata consistent with the target files and directories (inodes). Hopsworks is accessible either through a REST API or an intuitive UI (that includes a Feature Catalog), or programmatically through the Hopsworks Feature Store API (HSFS).
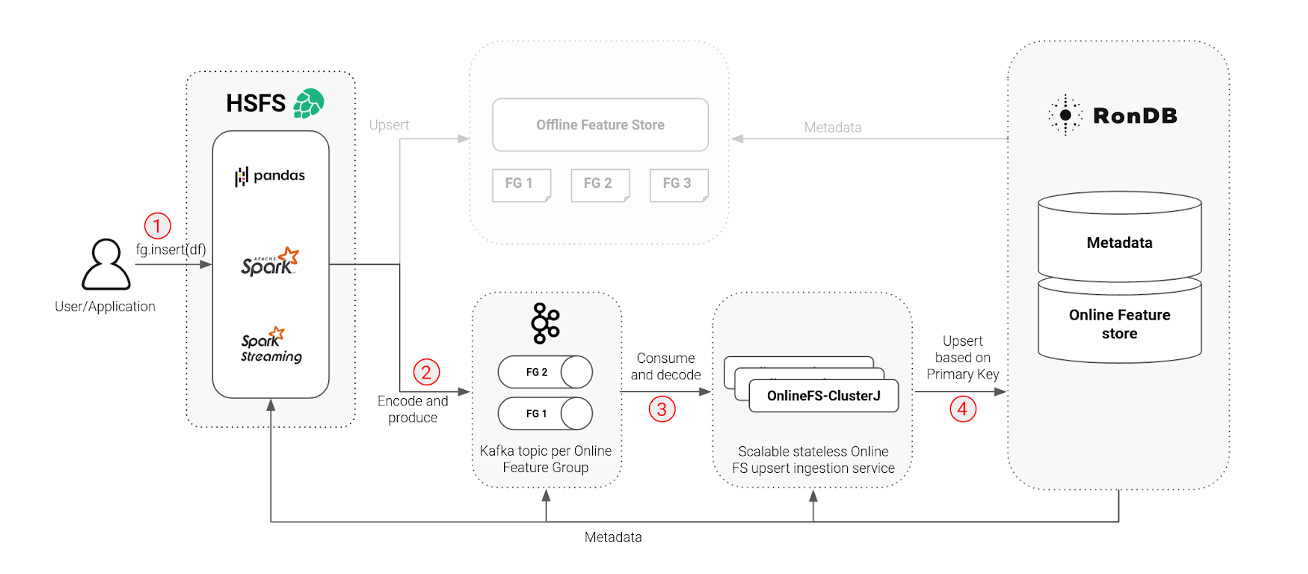
With the underlying RonDB and the needed metadata in place, we were able to build a scale-out, high throughput materialization service to perform the updates, deletes, and writes on the online feature store - we simply named it OnlineFS. OnlineFS: The Engine for Scalable Online Feature MaterializationWith the underlying RonDB and the needed metadata in place, we were able to build a scale-out, high throughput materialization service to perform the updates, deletes, and writes on the online feature store - we simply named it OnlineFS. OnlineFS is a stateless service using ClusterJ for direct access to the RonDB data nodes. ClusterJ is implemented as a high performance JNI layer on top of the native C++ NDB API, providing low latency and high throughput. We were able to make OnlineFS stateless due to the availability of the metadata in RonDB, such as avro schemas and feature types. Making the service stateless allows us to scale writes to the online feature store up and down by simply adding or removing instances of the service, thereby increasing or decreasing throughput linearly with the number of instances. The steps that are needed to write data to the online feature store:
To learn more about each step and transparency in distributed systems please continue to read here. In our blog, we also provide some benchmarks for quantitative comparison. *This post was written by the Hopsworks team and originally posted here. We thank Hopsworks for their ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
© 2022 Jesus Rodriguez, Ksenia Semenova Unsubscribe
|


Older messages
🟧 Edge#192: Inside Predibase, the Enterprise Declarative ML Platform
Thursday, May 19, 2022
Our goal is to keep you up to date with new developments in AI and introduce to you the platforms that deal with the ML challenges
📝 Guest post: How to Measure Your GPU Cluster Utilization, and Why That Matters*
Wednesday, May 18, 2022
In this article, Run:AI's team introduces rntop, a new super useful open-source tool that measures GPU cluster utilization. Learn why that's a critical measure for data scientists, as well as
📨 Edge#191: MPI – the Fundamental Enabler of Distributed Training
Tuesday, May 17, 2022
In this issue: we discuss the fundamental enabler of distributed training: message passing interface (MPI); +Google's paper about General and Scalable Parallelization for ML Computation Graphs; +
📌Event: Join the Largest Conference on MLOps: 3rd Annual MLOps World 2022! 🎉
Monday, May 16, 2022
We are happy to support the 3rd Annual MLOps World 2022! The MLOps World Committee would like to invite you this June 9-10th for a truly must-attend event, and an unforgettable experience in Toronto,
Google’s Big ML Week
Sunday, May 15, 2022
Weekly news digest curated by the industry insiders
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your