The Sequence Chat: Shreya Rajpal, Co-Founder and CEO, Guardrails AI About Ensuring the Safety and Robustness of LL…
Was this email forwarded to you? Sign up here The Sequence Chat: Shreya Rajpal, Co-Founder and CEO, Guardrails AI About Ensuring the Safety and Robustness of LLMsThe co-creator of one of the most important LLM guardrails frameworks shares her perspectives on building safe, robust and efficient LLM applications, the architecture of Guardrails AI and more.
Quick BioShreya Rajpal is the creator and maintainer of Guardrails AI, an open-source platform developed to ensure increased safety, reliability, and robustness of large language models in real-world applications. Her expertise spans a decade in the field of machine learning and AI. Most recently, she was the founding engineer at Predibase, where she led the ML infrastructure team. In earlier roles, she was part of the cross-functional ML team within Apple's Special Projects Group and developed computer vision models for autonomous driving perception systems at Drive.ai. 🛠 AI Work
Guardrails AI began from my own exploration of building applications with Large Language Models (LLMs). I quickly discovered that while I could reproduce some really exciting GPT-application demos, deriving practical value from these applications repeatedly was challenging, mostly due to the inherent non-determinism of LLMs. There were significant parallels between the production gap with LLM apps that reminded me of my experience in self-driving cars. The new wave of applications people build with LLMs is more complex, more like a self-driving car's system, combining various specialized models to complete individual tasks. An early hypothesis I had was that the process of building reliable AI applications would be like the strict online verification processes used in self-driving cars. Guardrails AI came out of that hypothesis, with the goal of bridging the reliability gap between AI-driven and more traditional, deterministic software components.
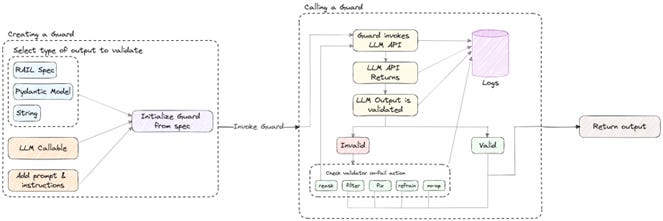
The core components of the Guardrails AI architecture are 1) Guards and 2) Validators. The Guard operates as a sidecar to the LLM. Whenever an LLM call is made, the Guard acts as an inline verification suite that ensures both inputs and outputs of the LLM are correct, reliable and respect specified constraints. If your application has a chain or an agent framework with multiple LLM calls, you will typically instantiate multiple LLM Guards to enforce validation at each stage and mitigate the risk of compounding errors. A Guard is composed of multiple Validators, where each validator enforces a specific requirement for “correctness”. For example, one Validator may ensure that the LLM's output adheres to a specific format like JSON. Another might check for hallucinations in the output, while yet another could screen for toxicity or profanity. These Validators programmatically assess LLM-generated outputs against their respective “correctness” criteria, which altogether builds a comprehensive verification system.
One of the early decisions in the development of the open-source project was to design something as user-friendly for non-technical users as ChatGPT-based prompting. I created RAIL as a solution to that problem and designed it to be a variant of XML. Since many non-programmers have at least a basic familiarity with HTML, the learning curve for RAIL is fairly straightforward. At its core however, Guardrails AI is a framework for enforcing constraints on AI applications. As such, both RAIL & Python are essentially interfaces that allow developers to specify which constraints matter to them and choose the interface that best suits their technical expertise.
I believe the current trend of using Large Language Models (LLMs) to validate other LLMs stems more from a lack of alternative validation tools than from its efficacy as a validation method, primarily because of these reasons:
However, this creates a 'who-will-guard-the-guards' problem. How can we be sure that the validating LLM is reliable and aligned with our expectations? Anecdotally, I've seen substantial variance using LLM self-validation across repetitive runs. While self-validation is a component of a verification system, developers typically want the bulk of validation to be more deterministic and interpretable. The Guardrails AI framework takes a much more grounded approach to validation. We break down the validation problem into smaller components and use a mix of heuristic rule-based engines, domain-specific finetuned models, and external systems for a more reliable and interpretable validation process. While scaling this approach takes longer, it builds a greater degree of trust in the overall system.
Great point! One unintended benefit of the current evaluation crisis is the wealth of valuable metadata generated during testing. Every request yields not only raw output from the LLM, but also multiple scores and metrics that capture the quality aspects you’re interested in. This data is extremely useful with two applications: it's a great resource for benchmarking existing applications and ends up being a rich goldmine for fine-tuning newer, smaller domain specific open-source models.
From a system-design perspective, the underlying philosophy of implementing guardrails is fairly consistent across different modalities. However, the actual guardrails implementations can vary significantly. Here’s what I mean by that: The key challenge with building guardrails lies in encoding “correctness” requirements into actual executable checks that function as a verification system around the foundation model. Because the tasks we use GenAI for are fairly complex when compared to previous generations of ML applications, evaluating their correctness is non-trivial. For example, two summaries could convey completely different information while still being “correct”. Our solution to this problem is to break down “correctness” into discrete validators, where each validator focuses on one aspect of the model’s performance. E.g., for generative text, different validators inspect structured output generation, hallucinations and toxic content. On the other hand, generative audio validators may look at the fidelity to the voice being replicated, the continuity of audio and the speaking speed. Compared to traditional unit testing frameworks, guardrails are domain specific and also inherently stochastic. 🛠 AI Work
Efficient ML! I worked on this in the past but thinking about how to take very large models and shrink them down to low latency, low memory versions of themselves without sacrificing performance is a super exciting problem.
I strongly believe that there is substantial room for specialized guardrails for LLMs. To unlock their full potential, we need to solve key challenges that allow us to use LLMs as reliably as deterministic software APIs today. It’s very hard to solve these challenges purely on the model level, which creates an opportunity for platforms working exclusively on Guardrails. For instance, consider a financial institution utilizing LLMs for automated customer support. Here, the guardrails must not only ensure data security, lack of hallucinations, etc. but also adhere to specific industry and company regulations.
Great question! NeMO is primarily a framework for building chatbots that allows you to create controlled dialog flows. Guardrails AI, on the other hand, is a framework for performing LLM validation – you can use the Guards that are created from Guardrails AI as checks in chatbots you create using NeMO. Additionally, Guardrails AI applies to all types of LLM applications in addition to chatbots and dialog systems.
I don’t think it's strictly either-or — I strongly believe that there's room for both open source and commercial models to co-exist. Currently, commercial models lead the way, especially in setting high-performance baselines on new benchmarks. However, the top open-source models are not far behind in terms of raw performance. Companies that will go for open-source models will do so for reasons related to cost, privacy, or explainability. At this stage however, the industry is focused on demonstrating the significant value that LLMs can bring; only then will it make sense for companies to invest in tuning and hosting their own custom models. You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|



Older messages
Edge 333: Understanding Parameter Efficient Fine Tuning
Tuesday, October 10, 2023
An overview of PEFT, one of the most important fine-tuning methods ever created;
📡 WEBINAR: Unraveling prompt engineering
Monday, October 9, 2023
You can't talk about LLMs without talking about prompt engineering – and at first glance, prompting may appear intuitive and straightforward, but well, it ain't. Join us for the next webinar of
The Most Obvious Secret in AI: Every Tech Giant Will Build Its Own Chips
Sunday, October 8, 2023
Sundays, The Sequence Scope brings a summary of the most important research papers, technology releases and VC funding deals in the artificial intelligence space.
📣 Webinar: Learn how to fine-tune RAG and boost your content quality with Zilliz and 🔭 Galileo
Friday, October 6, 2023
If you're trying to improve the quality of your LLM-generated responses, you've probably explored retrieval augmented generation (RAG). Grounding your model on external sources of information
Edge 332: Inside FlashAttention: The Method Powering LLM Scalability to Whole New Levels
Thursday, October 5, 2023
FlashAttention and FlashAttention-2 have been implemented by some of the major LLM platforms in the market.
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your