Humanity Redefined - Deliberative alignment - Sync #499
I hope you enjoy this free post. If you do, please like ❤️ or share it, for example by forwarding this email to a friend or colleague. Writing this post took around eight hours to write. Liking or sharing it takes less than eight seconds and makes a huge difference. Thank you! Deliberative alignment - Sync #499Plus: GPT-5 reportedly falling short of expectations; Nvidia GB300 "Blackwell Ultra"; automating the search for artificial life with foundation models; Boston Dynamics' Atlas does backflip; and moreHello and welcome to Sync #499! Although o3 was the star of the final day of the 12 Days of OpenAI, it wasn’t the only announcement made that day. OpenAI also introduced deliberative alignment, a new alignment strategy for o-series models that shows promising results and hints at the direction training new AI models might take in the near future. Elsewhere in AI, reports emerge that GPT-5 might be falling short of expectations. Meanwhile, Nvidia is preparing a Blackwell Ultra GPU, Google is reportedly using Anthropic’s Claude internally to improve its Gemini AI, and Sakana.ai shows how they use foundation models to discover new forms of artificial life. Over in robotics, Boston Dynamics’ Atlas becomes the first all-electric humanoid robot to do a backflip. Waymo has published a study claiming that autonomous vehicles are safer than human drivers, and a Chinese robotics startup has announced the production of 962 units of its general-purpose humanoid robots for commercial use. We will finish this week’s issue of Sync with a report signed by experts in immunology, synthetic biology, plant pathology, evolutionary biology, and ecology—alongside two Nobel laureates—urging a halt to research on “mirror life” and mirror bacteria until there is clear evidence that these organisms would not pose extraordinary dangers. Enjoy!
Deliberative alignmentThe star of the final day of the 12 Days of OpenAI was o3, OpenAI’s latest model in their line of reasoning AI models. o3 established a new state-of-the-art level of performance for AI models, positioning itself well ahead of its competitors. Although o3 was the highlight of the event, it was not the only thing OpenAI presented that day. It did not receive much attention during the announcement, but OpenAI also revealed a new alignment strategy called deliberative alignment. Currently used safety alignment methods for large language models (LLMs) like Reinforcement Learning with Human Feedback (RLHF) or Supervised Fine Tuning (SFT) are not perfect. In the paper describing deliberative alignment, researchers from OpenAI identified two problems with current safety methods. First, LLMs must respond instantly and there is no time for them to “think” or to check if the provided answer is both correct and safe. Second, LLMs have to figure out safety rules indirectly by looking at many labeled examples, instead of directly learning the safety guidelines. As a result, LLMs must effectively guess what “safe” behaviour looks like, which can lead to both unnecessary refusals of benign prompts and compliance with harmful requests. To solve both issues, researchers from OpenAI propose a new alignment strategy they call deliberative alignment. The idea behind deliberative alignment is pretty straightforward. Researchers trained o-series models to “think” about whether the prompt or the response they generate aligns with internal safety specifications. Using chain-of-thought (CoT) reasoning methods, o-series models can analyse user prompts, identify relevant policy guidelines, and produce safer responses. Deliberative alignment enables the model to consult the actual text of the safety specifications during inference, effectively “quoting” or referencing specific rules as it reasons through prompts. This direct, policy-based reasoning allows for more precise, context-sensitive adherence to safety guidelines compared to previous approaches.
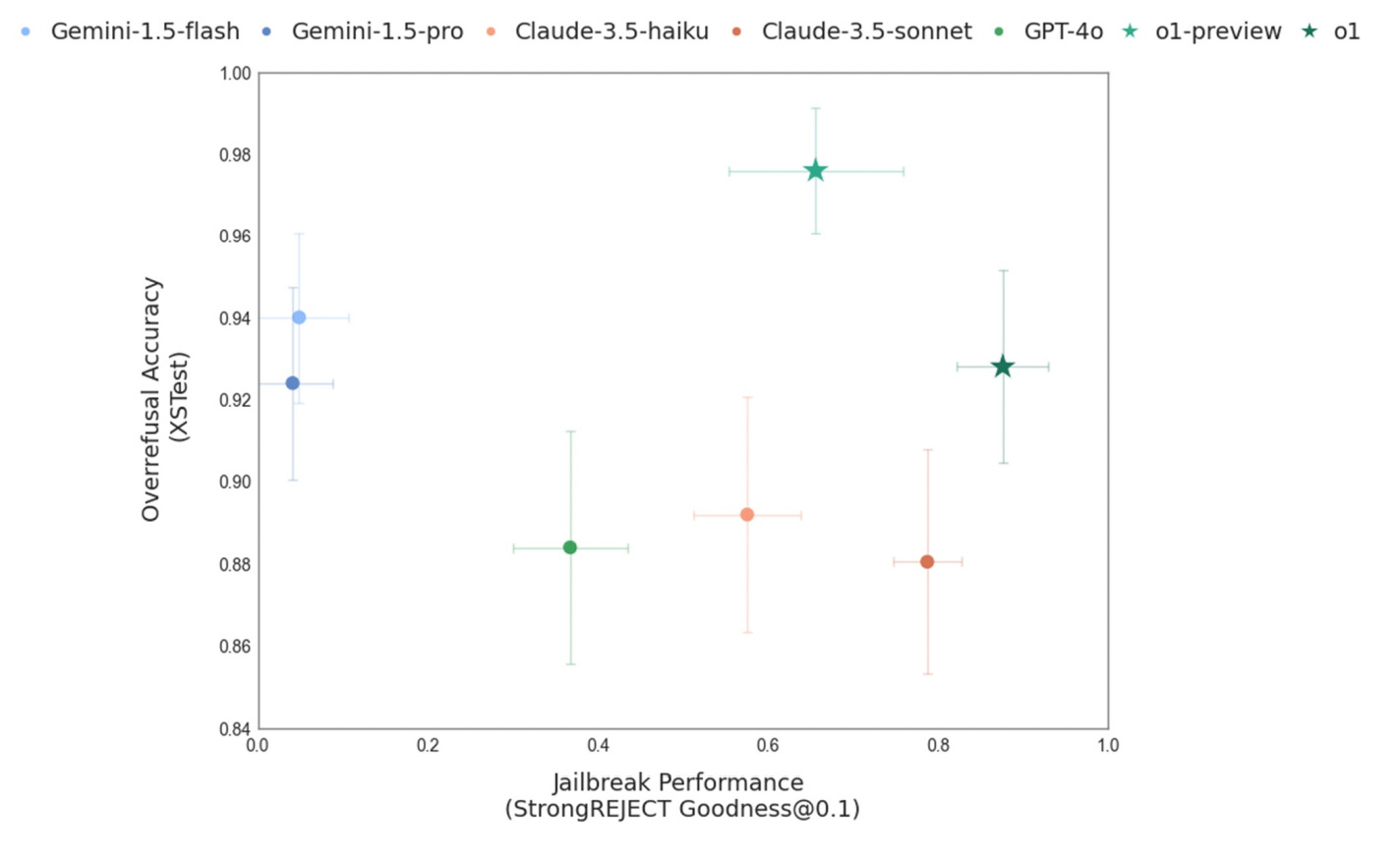
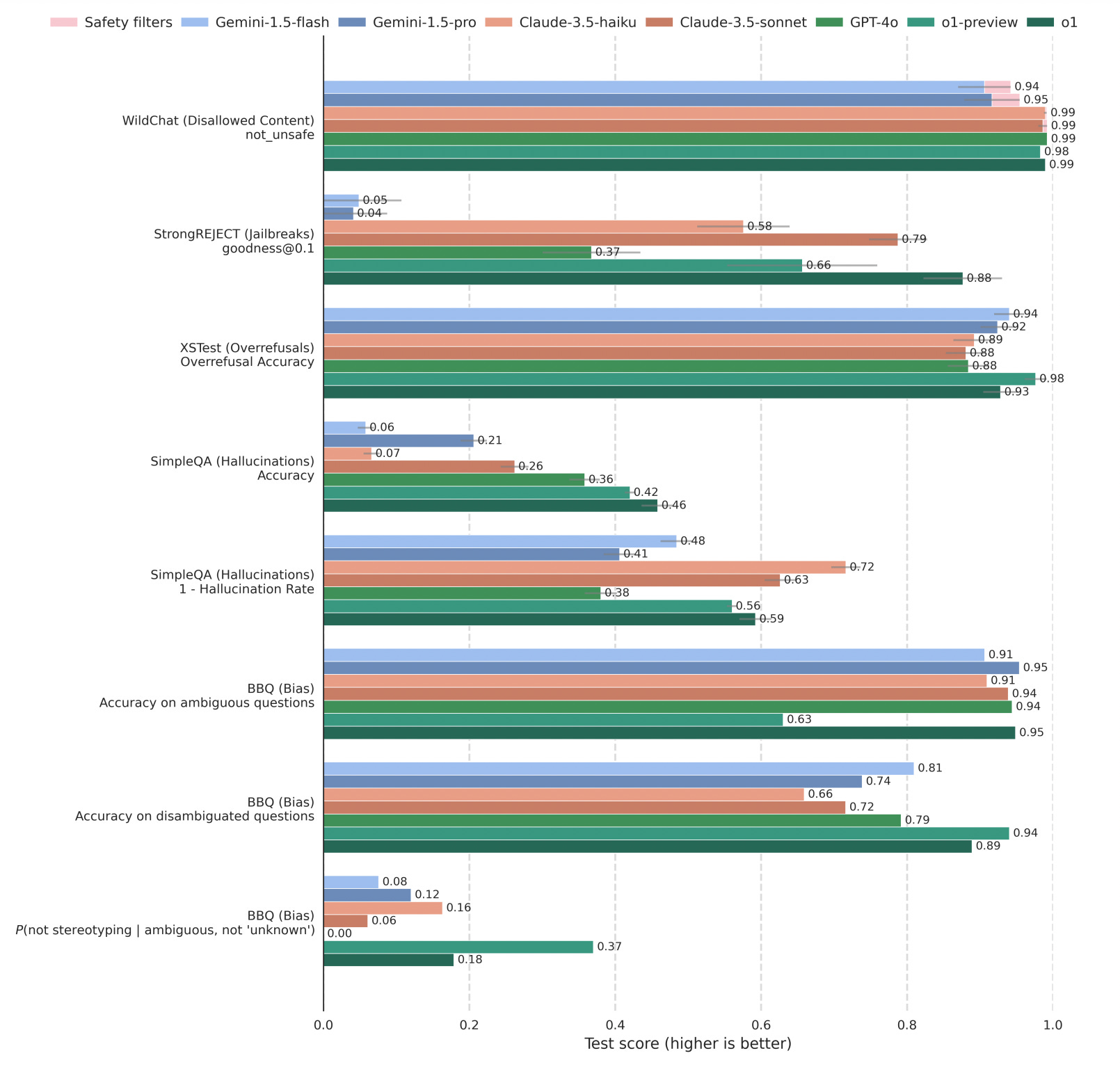
The fact that o-series models reason through the prompts and answers while consulting the actual text of the safety specifications, should also reduce the likelihood of over-refusal or incorrectly flagging interactions as unsafe. Below is an example of a prompt that falls into the grey area of safety specifications. Researchers demonstrate how o1, using deliberative alignment, debates internally whether it should answer this prompt and ultimately concludes that it is appropriate to respond.
I tested that prompt using GPT-4o, and it indeed refused to answer. Interestingly, the o1 model I have access to also declined to respond to the same prompt. This raises the possibility that deliberative alignment has not yet been deployed. Neither the article nor the paper clearly specifies whether deliberative alignment is currently in use. According to the results published by OpenAI, this conceptually simple idea performs very well. It deals better with jailbreak attempts while at the same time decreasing over-refusal rates.
The paper also describes how deliberative alignment works. Researchers quickly realised that asking o-series models to evaluate every “thought” in the chain-of-thoughts against internal safety specifications is highly ineffective and would negatively impact the model’s performance. As the researchers described it, “reasoning over pages of safety specifications is overkill for benign user prompts.” Instead, researchers embed knowledge of the safety specifications directly in the underlying model. That embedded knowledge is then used to identify if a prompt or answer is suspicious and only then the model starts to fully reason over its safety implications. Another interesting thing that OpenAI revealed in the paper is the use of synthetic data (AI-generated examples) in the safety training pipeline. Rather than manually creating thousands of detailed examples for every potential safety issue, OpenAI’s pipeline automatically generates training data from the safety specifications themselves, combined with safety-categorized prompts. This allows the model to learn directly from a wide array of scenarios—both benign and malicious—without the prohibitive overhead of collecting human-labeled examples. By systematically exploring edge cases through synthetic data, the model gains robust safety reasoning and is better equipped to handle unforeseen situations. As a result, deliberative alignment not only cuts down on the time and cost of data creation but also scales more effectively than traditional methods like RLHF or pure supervised fine-tuning. I’d like to highlight that bit about using synthetic data. As AI companies exhaust high-quality training material for their models, the idea of using synthetic data—data created by an AI to train another AI—has been gaining traction. However, I don’t recall seeing a successful use of synthetic data before. OpenAI’s deliberative alignment might be one of the first successful applications of this approach. The successful use of synthetic data in deliberative alignment could hint at where AI research is headed in the near future. We might see more and more successful examples of synthetic data being used, reducing reliance on harvesting quality training material from the internet. The implication is that, if applied effectively, synthetic data could accelerate the capabilities of AI models. AI companies would no longer be limited by the availability of training data, as they could generate new data on demand. The only constraint would then be the speed at which high-quality synthetic training data can be generated, which depends on the computing power available to them. Deliberative alignment is an interesting new method for aligning reasoning AI models to adhere to safety specifications, showing that it is possible for the safety of AI systems to improve as their capabilities grow. OpenAI’s results are promising, particularly in demonstrating nuanced control over compliance, refusal, and task completion, as well as enhanced robustness to jailbreaks. The use of scalable synthetic data generation pipelines adds to its potential. OpenAI’s successful implementation of synthetic data hints at a future where AI models are increasingly trained on data generated by other AIs, thereby accelerating the development and capabilities of future models.
If you enjoy this post, please click the ❤️ button or share it. Do you like my work? Consider becoming a paying subscriber to support it For those who prefer to make a one-off donation, you can 'buy me a coffee' via Ko-fi. Every coffee bought is a generous support towards the work put into this newsletter. Your support, in any form, is deeply appreciated and goes a long way in keeping this newsletter alive and thriving. 🦾 More than a humanSouth Korean team develops ‘Iron Man’ robot that helps paraplegics walk Scientists explore longevity drugs for dogs that could also ‘extend human life’ 🧠 Artificial IntelligenceOpenAI’s GPT-5 reportedly falling short of expectations Automating the Search for Artificial Life with Foundation Models NVIDIA GB300 "Blackwell Ultra" Will Feature 288 GB HBM3E Memory, 1400 W TDP Google is using Anthropic’s Claude to improve its Gemini AI ▶️ The Dark Matter of AI [Mechanistic Interpretability] (24:08)  The field of interpretability, or understanding how neural networks work, is one of the most important areas in AI research, helping us better align AI models and thus make them safer. This video explores sparse autoencoders—powerful tools that extract and manipulate human-understandable features from AI models. By using these tools, researchers can gain deeper insights into the inner workings of neural networks, helping to make AI behaviour more predictable and controlled. OpenAI cofounder Ilya Sutskever says the way AI is built is about to change ▶️ How A.I. Could Change Science Forever (20:02)  One of the areas tech companies see AI is going to drastically transform is science. In this video, Prof. David Kipping, an astronomer and the host of the Cool Worlds YouTube channel, explores as a scientist the possible applications of AI in science. He envisions a future where AI augments the entire research cycle, from data analysis to automating peer review and hypothesis generation, potentially leading to full automation of research projects. Although Kipping is generally optimistic about the use of AI in science, he emphasizes the importance of keeping the human element in science—the curiosity-driven human urge to understand the world. If you're enjoying the insights and perspectives shared in the Humanity Redefined newsletter, why not spread the word? 🤖 Robotics▶️ Happy Holidays | 2024 | Boston Dynamics (0:34)  Once again, Boston Dynamics is just showing off what their humanoid robot Atlas can do. This time, it’s a backflip. The only other humanoid robot that could do backflips was the previous, hydraulic Atlas, and I don’t think I’ve seen any other all-electric humanoid robot able to pull that off. Waymo still doing better than humans at preventing injuries and property damage NHTSA finally releases new rules for self-driving cars — but there’s a twist Ukraine’s All-Robot Assault Force Just Won Its First Battle Former Huawei ‘Genius Youth’ recruit says new venture can now mass produce humanoid robots 🧬 BiotechnologyCreating ‘Mirror Life’ Could Be Disastrous, Scientists Warn
Thanks for reading. If you enjoyed this post, please click the ❤️ button or share it. Humanity Redefined sheds light on the bleeding edge of technology and how advancements in AI, robotics, and biotech can usher in abundance, expand humanity's horizons, and redefine what it means to be human. A big thank you to my paid subscribers, to my Patrons: whmr, Florian, dux, Eric, Preppikoma and Andrew, and to everyone who supports my work on Ko-Fi. Thank you for the support! My DMs are open to all subscribers. Feel free to drop me a message, share feedback, or just say "hi!"
|






Older messages
o3—the new state-of-the-art reasoning model - Sync #498
Sunday, December 22, 2024
Plus: Nvidia's new tiny AI supercomputer; Veo 2 and Imagen 3; Google and Microsoft release reasoning models; Waymo to begin testing in Tokyo; Apptronik partners with DeepMind; and more! ͏ ͏ ͏ ͏ ͏ ͏
Google's Agentic Era - Sync #497
Thursday, December 19, 2024
Plus: Sora is out; OpenAI vs Musk drama continues; GM closes Cruise; Amazon opens AGI lab; Devin is out; a humanoid robot with artificial muscles; NASA's new Martian helicopter; and more! ͏ ͏ ͏ ͏ ͏
OpenAI o1 goes Pro - Sync #496
Tuesday, December 10, 2024
Plus: DeepMind Genie 2; Google released Veo and Imagen 3 on Vertex AI; Tesla Optimus shows off new hand; Grok is free for all X users; ads might be coming to ChatGPT; Waymo comes to Miami; and more! ͏
Artists against AI - Sync #495
Saturday, November 30, 2024
Plus: Amazon's AI chips; OpenAI web browser with ChatGPT; new humanoid robot video; Human Cell Atlas releases its first draft; can humans hibernate?; AI agents behaving very human-like; and more! ͏
OpenAI's turbulent early years - Sync #494
Sunday, November 24, 2024
Plus: Anthropic and xAI raise billions of dollars; can a fluffy robot replace a living pet; Chinese reasoning model DeepSeek R1; robot-dog runs full marathon; a $12000 surgery to change eye colour ͏ ͏
You Might Also Like
Daily Coding Problem: Problem #1707 [Medium]
Monday, March 3, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Facebook. In chess, the Elo rating system is used to calculate player strengths based on
Simplification Takes Courage & Perplexity introduces Comet
Monday, March 3, 2025
Elicit raises $22M Series A, Perplexity is working on an AI-powered browser, developing taste, and more in this week's issue of Creativerly. Creativerly Simplification Takes Courage &
Mapped | Which Countries Are Perceived as the Most Corrupt? 🌎
Monday, March 3, 2025
In this map, we visualize the Corruption Perceptions Index Score for countries around the world. View Online | Subscribe | Download Our App Presented by: Stay current on the latest money news that
The new tablet to beat
Monday, March 3, 2025
5 top MWC products; iPhone 16e hands-on📱; Solar-powered laptop -- ZDNET ZDNET Tech Today - US March 3, 2025 TCL Nxtpaper 11 tablet at CES The tablet that replaced my Kindle and iPad is finally getting
Import AI 402: Why NVIDIA beats AMD: vending machines vs superintelligence; harder BIG-Bench
Monday, March 3, 2025
What will machines name their first discoveries? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
GCP Newsletter #440
Monday, March 3, 2025
Welcome to issue #440 March 3rd, 2025 News LLM Official Blog Vertex AI Evaluate gen AI models with Vertex AI evaluation service and LLM comparator - Vertex AI evaluation service and LLM Comparator are
Apple Should Swap Out Siri with ChatGPT
Monday, March 3, 2025
Not forever, but for now. Until a new, better Siri is actually ready to roll — which may be *years* away... Apple Should Swap Out Siri with ChatGPT Not forever, but for now. Until a new, better Siri is
⚡ THN Weekly Recap: Alerts on Zero-Day Exploits, AI Breaches, and Crypto Heists
Monday, March 3, 2025
Get exclusive insights on cyber attacks—including expert analysis on zero-day exploits, AI breaches, and crypto hacks—in our free newsletter. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
⚙️ AI price war
Monday, March 3, 2025
Plus: The reality of LLM 'research'
Post from Syncfusion Blogs on 03/03/2025
Monday, March 3, 2025
New blogs from Syncfusion ® AI-Driven Natural Language Filtering in WPF DataGrid for Smarter Data Processing By Susmitha Sundar This blog explains how to add AI-driven natural language filtering in the