SEO Best Practices for Syndicated Content
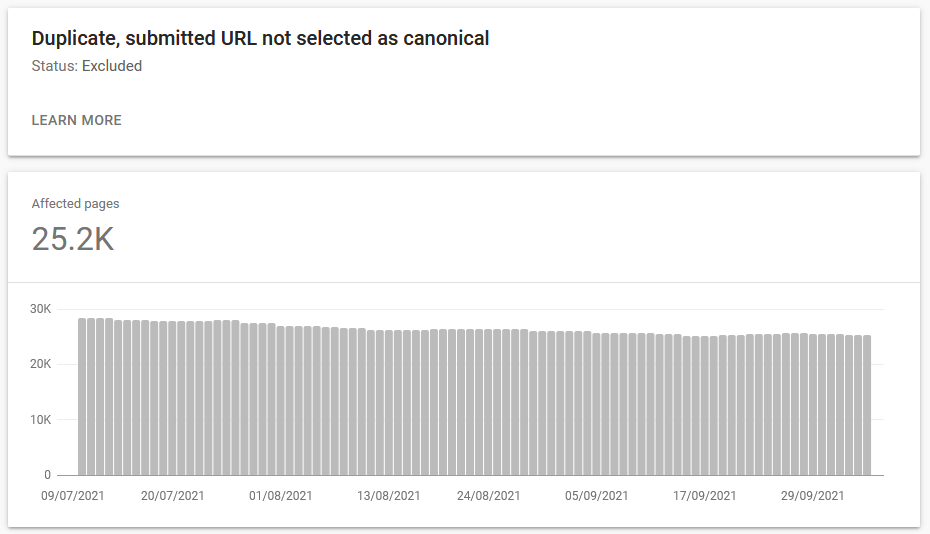
SEO Best Practices for Syndicated ContentWhen you republish content from another source, what should you do to maximise the SEO value?One topic I get asked about frequently is duplicate content. Especially how to handle articles syndicated from 3rd party sources like Reuters and Bloomberg, or articles from a national news site republished on local affiliate sites. This is a complicated topic that contains many different layers and aspects; from simply taking a feed from Reuters and publishing the articles on your own site, to a complex ecosystem of repurposed and monetised articles shared across a range of syndication platforms of varying quality. For the sake of this newsletter, I’ll keep it fairly simple and talk about the most basic form of article syndication: where you either take a feed from a 3rd party and publish it on your own site, or you supply a feed of your own articles to other publishers. Specifically, I’ll discuss best practices for republishing articles that have appeared elsewhere first in a (near-)identical format, and the weaknesses that Google News suffers from when it comes to identifying and ranking original publishers. Google and Duplicate ContentBefore we can dig into the specifics, we first have to understand why identical content published on multiple websites is a problem for Google. In a previous newsletter, ‘Technical Optimisation for Articles’, I outlined how Google has a multi-layered indexing system. In its simplest form, Google first indexes an article based on the raw HTML source, and later renders the webpage and loads all its associated resources so it can get a complete overview of the page’s layout and content. But that’s not all that happens. Google’s indexing is a complex interwoven system of many different processes that each do a specific thing as part of Google’s effort to paint a full picture of the webpage itself, its place on the website, and in the wider web. One of these additional processes is de-duplication. Essentially, Google doesn’t want to waste effort on webpages that are most likely duplicate versions of other pages that have already been crawled and indexed. De-duplication happens more than once in Google’s ecosystem. In fact, I believe it happens at each of the three main stages: crawling, indexing, and ranking. Crawl De-DuplicationIn the crawling stage, Google will look for URL patterns to determine the likelihood that a URL queued for crawling is in fact an exact duplicate of an already crawled URL. For example, a URL with GA tracking parameters appended to the end is, in all likelihood, the same webpage as the ‘clean’ version of that URL. There’s no new content for Google to discover, so it may decide to skip that URL for crawling. Index De-DuplicationWhen it comes to the indexing stage, Google also attempts to de-duplicates webpages. If Google finds two pages which contain the exact same content, Google can decide to include one in its index of the web and discard the other. We can find examples of this in the Index Coverage report in Google Search Console, as one of the reasons webpages are ‘Excluded’ from the index.
A canonical link tag helps Google decide which URL should be indexed. However, canonical tags are interpreted as hints, not directives. This means that Google can choose to ignore the canonical link, and index a different URL instead if it believes that one should serve as the canonical version. This can be the case when, for example, your internal navigation links point to a URL which you then canonicalise to a different URL. An internal link is a very strong canonicalisation signal for Google, so it may override your canonical meta tag and result in the ‘wrong’ version of the page getting indexed. Yet despite Google’s efforts, you frequently see two identical pages included in Google’s index. This is especially likely if the two pages exist on different websites, with different designs and boilerplate content surrounding the article. In those cases, Google prefers to keep both versions of the article in its index, and can rank them independently of one another depending on the context of the search and the intent of the query. Rank De-DuplicationWhen it comes to ranking pages in its search results, Google also tries to de-duplicate the webpages it shows. Google realises that showing multiple instances of the same content isn’t a great experience for its users, so it tries to show only the most relevant version of an article on a search result even when that same article is indexed on multiple websites. This is where ranking signals like editorial expertise come into play. When a website is seen to have strong editorial authority on a specific topic, articles about that topic that are hosted on that website are more likely to be chosen for ranking in Google’s results than those same articles hosted on a different website which lacks that editorial expertise. Basically, if your news site is known as an expert on a topic, your articles are likely to rank in Google’s results - even if your articles are exact duplicates of articles published elsewhere. This is not a perfect system, and Google’s ranking signals are incredibly varied and context-dependent, which is why it can be very hard to predict what Google will show for any given search. But hopefully the above gives you a bit of an idea of how duplicate content can end up in Google’s search results. And that’s without considering the special treatment that news gets in this regard. Crawling, Indexing, and Ranking for NewsWhat I’ve outlined above is all based on the assumption that Google completes all its crawling, indexing, and ranking processes and has had a chance to properly evaluate all relevant webpages. For news websites, this is not going to be the case. As we’ve discussed in previous newsletters, speed is a crucial factor for news. Google cannot afford to rank outdated news articles in its search results, especially for fast-moving news stories where people are looking for the latest developments. So for news articles, Google takes shortcuts and sacrifices some aspects of its indexing processes. We’ve previously discussed one of those shortcuts: rendering. I believe Google doesn’t wait for the rendering phase of indexing before it indexes and ranks news articles. I also believe that de-duplication is one of the casualties of speedy indexing in Google. For reasons of haste (and potentially for the sake of completeness), Google will not perform thorough de-duplication when it crawls, indexes, and ranks news articles. Google will simply crawl any new URL for an article published on a news site, and will index that article as-is so it can start ranking straight away. Canonical meta tags are taken into account to a certain extent, and Google will do its best to only rank the canonical version of an article. But this isn’t a perfect science, and news articles that are canonicalised to a different URL can still end up in Google’s news-specific ranking elements. So, what should you as a publisher do with duplicate content? Republishing Someone Else’s ContentWhen you take a feed from a content provider, for example Reuters or Bloomberg, and publish those stories on your website without modification, Google wants you to actively prevent them from indexing the article. According to Google’s official advice:
Basically, Google knows it has a weakness when it comes to de-duplicating news stories, so they want you to prevent the issue from occurring in the first place. With a robots meta tag, you can tell Google not to index the article for the purpose of news:
Note that here, Google does not recommend using a canonical tag to point to the original source. However, there’s somewhat conflicting advice on Google’s Publisher support center:
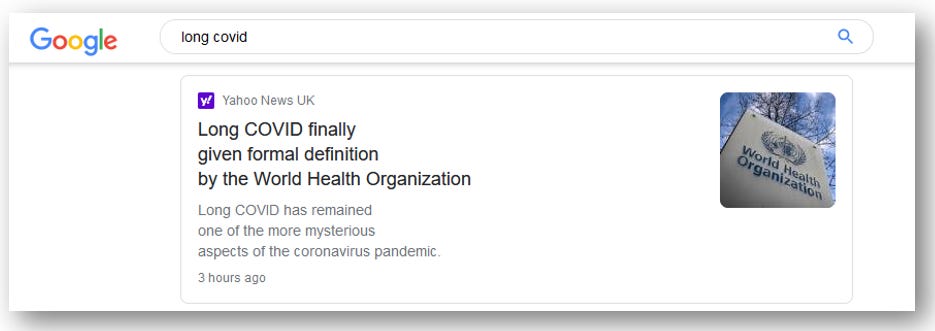
So, should you canonicalise or block? 😈 Evil Grin Emoji 😈My advice is somewhat different from Google. You see, what we have here is an exploitable weakness that Google suffers from. And I’d be remiss in my endeavour to help publishers grow their traffic if I didn’t at least point out that weakness and show how you could potentially profit from it. Instead of blocking Googlebot’s access to syndicated content, or canonicalising it to the original publisher, you can just publish it as your own. Canonicalise it to your own URL, and don’t attribute it to anyone else. This is, in fact, what most publishers do. Take Yahoo! News for example; they publish almost no original content at all, and yet they regularly show up in Top Stories for all kinds of queries with articles they’ve republished from others.
Now, you may ask, isn’t this risky? Won’t Google penalise me for republishing content from others and pretending it’s my own? The answer is no. You see, if Google were to penalise websites for not attributing duplicate content to original publishers, they’d have to penalise almost everyone. There’d be precious few publishers left, and Google’s news rankings would be very thin indeed. There’s no penalty for duplicate content. There never has been - and likely never will be. Duplicate content is intrinsic to the web. It’s up to Google to figure things out and filter the copies from the original. You can certainly help Google with that, by canonicalising or blocking, but you are under no obligation to do so. In fact, I’d argue it would be against your own self-interest if you helped Google on this front. So, yes, go ahead and publish that Reuters feed as your own. Put your own canonical tag on those Bloomberg stories. Take that AP article and throw it on your website without any attribution. It’s not going to harm your site in the least and, in fact, may send nice chunks of traffic your way. The Inevitable CaveatIt’s a bit more nuanced than that, obviously. Factors like editorial expertise, authorship, and quality signals all come into play. You have to make sure the bulk of articles you publish on your site are actually your own. When it comes to building a strong reputation as a news publisher, both in the eyes of Google and the general public, you have to invest in original reporting. You shouldn’t try to get to the top the easy way with other people’s content. That only works if you’re Yahoo!. And, guess what, you’re not. (Unless you’re actually a Yahoo! employee, in which case I congratulate you on what is arguably the best business model in online news at the moment.) And, you may ask, what then is the ideal ratio of original content to republished content? How many of our daily articles should be original and how many duplicated pieces can we get away with? I can construe a long and detailed argument about how that’s the wrong question to ask, but this newsletter’s word count is already getting quite formidable so I’ll take the easy way out and slap a somewhat plausible number on it: 70% original content, 30% syndicated content. If that turns out to be an entirely wrong ratio, don’t blame me. You’ve been warned. From The Other SideWhat if you’re a creator of original content and you supply a feed to other websites? How can you best ensure that your original versions rank in Google, and not the republished versions published on your clients’ sites? Well, of course you can ask your customers to play nice and canonicalise the republished articles to the original URLs on your own site. Or you can ask them to block Googlebot’s access to the syndicated articles. Some may even say yes. A smarter approach would be to not give them the content straight away. When you supply a feed of articles to a 3rd party republisher, you should build in a delay between when you publish the story and when it’s sent out on the feed. Such a delay means that Google will first see your version of the article, and crawl & index it (and hopefully rank it as well). Later, when it’s sent out on the feed and your customers publish their own versions, you’re more likely to be seen as the original publisher and Google will hopefully maintain your prime rankings in Top Stories and Google News. I’d recommend a minimum delay of 30 minutes. Longer is better - some feed suppliers build in a delay of an hour or more, giving them ample opportunity to claim original publisher status for their articles. Summarised…In Google’s news ecosystem, duplicate content is a known weakness. Google asks you to play nice with canonicalisation and blocking, but you are free to use that weakness for your own benefit. There may not be a duplicate content penalty in Google’s world, that doesn’t mean you can ignore the issue entirely. Identical articles on multiple websites are one thing, but when you have duplicate content issues on your own site, that can be a real problem. If you have multiple URLs with the exact same content on your own domain, you risk competing with yourself for rankings in Google - and the only winner there is your competition. At best, you’re wasting crawl budget that could be better spent elsewhere. So take the effort to analyse your own scenario, and come up with the best approach to solve your specific challenge. I hope my newsletters can help a bit with that. Update on the NESSOur inaugural News & Editorial SEO Summit, taking place as a virtual event later this month, is taking shape nicely. Since our announcement, the reception from the broader industry has been overwhelmingly positive and we have hundreds of attendees signed up. We’d already secured a superb speaker line-up with the likes of Christine Liang (New York Times), Shelby Blackley (Mashable) and Jessie Willms (The Globe and Mail), Dan Smullen (Mediahuis), Lily Ray (Amsive), John Shehata (Condé Nast) and yours truly - and that line-up got even better with the addition of Nicholas Thompson. Nicholas is currently the CEO of The Atlantic and previously served as Editor in Chief of WIRED. He’ll be delivering the closing keynote on day 2 of our event, where he’ll talk about the importance of SEO for the future of publishing.
You can still grab your ticket to the event. We’re very excited to deliver the NESS and hope it’ll be a useful and rewarding experience for everyone involved. MiscellaneaHere are some interesting articles and insights from the past few weeks:
That’s all for this edition of SEO for Google News. As always, thanks for reading and see you at the next one! If you liked this article from SEO for Google News, please share it with anyone you think may find it useful. © 2021 Barry Adams Unsubscribe
|



Older messages
Thoughts on Google's Algorithmic News Inclusion Process
Sunday, September 5, 2021
Since the manual Google News approval process was retired in December 2019, getting into Google News has been a murky and frustrating affair.
Announcing the News and Editorial SEO Summit
Sunday, September 5, 2021
John Shehata and I have teamed up to deliver the first online event dedicated exclusively to SEO for news and publishing, taking place on October 26 & 27 this year.
You Might Also Like
Community Tickets: Advanced Scrum Master (PSM II) Class of March 26-27, 2025
Tuesday, March 4, 2025
Save 50 % on the Regular Price ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
eBook & Paperback • Demystifying Hospice: The Secrets to Navigating End-of-Life Care by Barbara Petersen
Monday, March 3, 2025
Author Spots • Kindle • Paperback Welcome to ContentMo's Book of the Day "Barbara
How Homer Simpson's Comical Gluttony Saved Lives
Monday, March 3, 2025
But not Ozzie Smith's. He's still lost, right?
🧙♂️ Why I Ditched Facebook and Thinkific for Circle (Business Deep Dive)
Monday, March 3, 2025
Plus Chad's $50k WIN ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
I'd like to buy Stripe shares
Monday, March 3, 2025
Hi all, I'm interested in buying Stripe shares. If you know anyone who's interested in selling I'd love an intro. I'm open to buying direct shares or via an SPV (0/0 structure, no
What GenAI is doing to the Content Quality Bell Curve
Monday, March 3, 2025
Generative AI makes it easy to create mediocre content at scale. That means, most of the web will become mediocre content, and you need to work harder to stand out. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
mRNA breakthrough for cancer treatment, AI of the week, Commitment
Monday, March 3, 2025
A revolutionary mRNA breakthrough could redefine medicine by making treatments more effective, durable, and precise; AI sees major leaps with emotional speech, video generation, and smarter models; and
• Affordable #KU Kindle Unlimited eBook Promos for Writers •
Monday, March 3, 2025
Affordable KU Book Promos "I'm amazed in this day and age there are still people around who treat you so kindly and go the extra mile when you need assistance. If you have any qualms about
The stuff that matters
Sunday, March 2, 2025
Plus, how to build a content library, get clients from social media, and go viral on Substack. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Food for Agile Thought #482: No Place to Hide from AI, Cagan’s Vision For Product Teams, Distrust Breeds Distrust
Sunday, March 2, 2025
Also: Product Off-Roadmap; AI for PMs; Why Rewrites Fail; GPT 4.5 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏