Playing with Streamlit and LLMs. @ Irrational Exuberance
Hi folks,
This is the weekly digest for my blog, Irrational Exuberance. Reach out with thoughts on Twitter at @lethain, or reply to this email.
Posts from this week:
-
Playing with Streamlit and LLMs.
Playing with Streamlit and LLMs.
Recently I’ve been chatting with a number of companies who are building out internal LLM labs/tools for their teams to make it easy to test LLMs against their internal usecases. I wanted to take a couple hours to see how far I could get using Streamlit to build out a personal LLM lab for a few usecases of my own.
See code on lethain/llm-explorer.
Altogether, I was impressed with how usable Streamlit is, and was able to build two useful tools in this timeframe:
- a text-based LLM notebook key, with prompt history
- a spreadsheet-based LLM notebook
It would be pretty easy to port over the tooling to query embeddings from my blog, which I build in an earlier blog post, as well as to index and query against arbitrary pdfs following the ask-my-pdf demo.
These are just rough notes, if you’re not interested in Streamlit, consider just skimming for the screenshots below to get a sense of what you can build in a couple hours.
Installation
First, let’s create a new virtualenv to play around in:
mkdir llm-streamlit && cd llm-streamlit
python3 -m venv env
pip install streamlit
Then we can run the “Hello world” script to verify the install:
streamlit hello
This should bring you to a streamlit page.
Making our own Hello World
Next, we can follow these instructions to write a very simple Streamlib page:
import streamlit as st
import pandas as pd
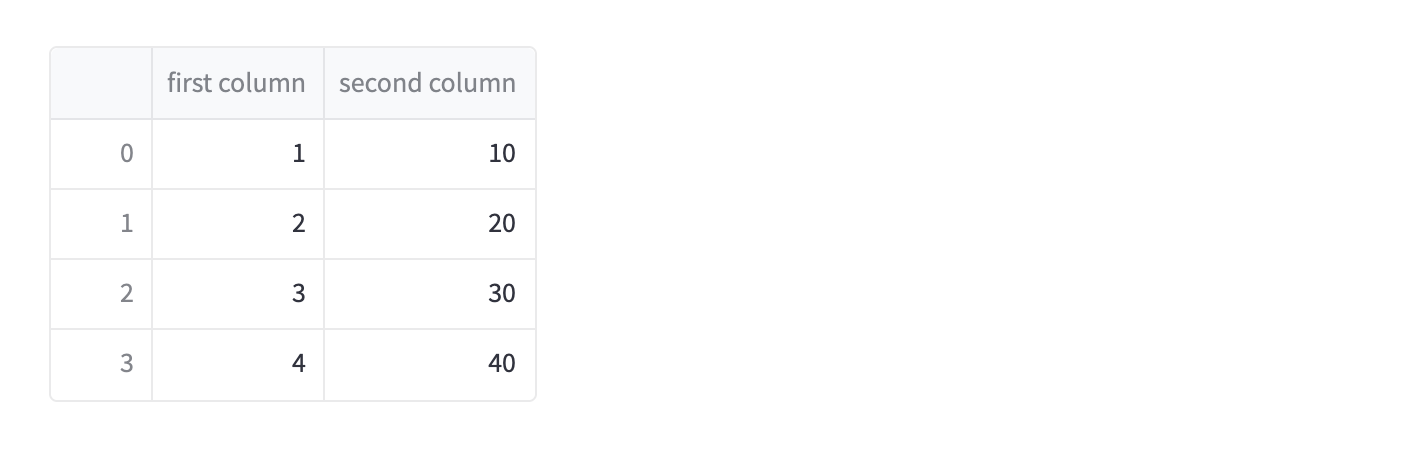
df = pd.DataFrame({
'first column': [1, 2, 3, 4],
'second column': [10, 20, 30, 40]
})
df
Which we can then run via:
streamlit run main.py
Which turns into this website at localhost:8501.
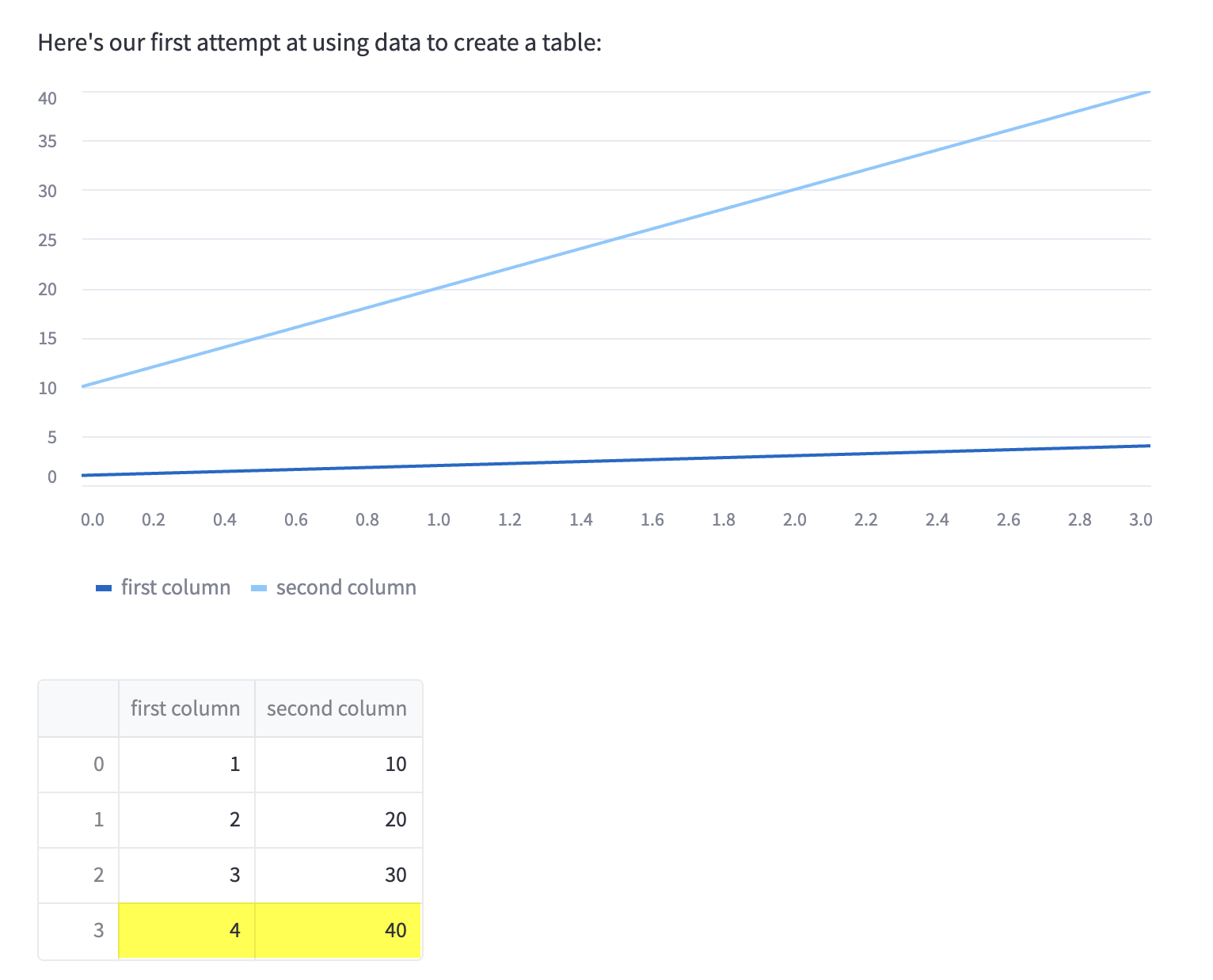
We can also add a linechart and highlight the maximum value by replacing df
with more explicit commands:
st.line_chart(chart_data)
st.dataframe(df.style.highlight_max(axis=0))
Which gives us a nice little linechart on top of our table.
Now, let’s experiment with creating a widget:
import streamlit as st
st.text_input("Your name", key="name")
name = st.session_state.name
st.write(f"This table is created by {name}:")
Which allows us to

Next, let’s add a second page so we can see how we’ll create different pages.
We’ll keep our main.py, adding a call to st.sidebar.markdown to populate
content for our sidebar:
import streamlit as st
import pandas as pd
st.markdown("# LLM Notebook")
st.sidebar.markdown("# LLM Notebook")
df = pd.DataFrame({
'first column': [1, 2, 3, 4],
'second column': [10, 20, 30, 40]
})
st.text_input("Your name", key="name")
name = st.session_state.name
st.write(f"This table is created by {name}:")
st.dataframe(df)
Then we’ll create a second page in pages/pdf.py
that is a stub for later adding a tool:
import streamlit as st
st.markdown("# PDF Extraction")
st.sidebar.markdown("# PDF Extraction")
Now we’ve pulled together a very simple scaffold that we’ll extend with interacting with OpenAI’s LLM APIs.
Interfacing with LLMs
For this section, I’m leaning on Langchain_Quickstart from Streamlit.
Our first step is to install LangChain to simplify interacting with LLMs:
pip install openai langchain
Then we’ll want to figure out how to load our OpenAI API key. The standard example includes an input in the sidebar for the OpenAI API key, but I don’t want to have to paste my key in every time, so I’m reusing a key loading pattern that I borrowed from Simon Willison in my last experiments with OpenAI.
I’ve created a oai_utils.py and adding this function to it:
import os
def get_openai_api_key():
api_key = os.environ.get('OPENAI_API_KEY')
if not api_key:
key_file = os.path.join(os.path.expanduser("~"),
".openai-api-key.txt")
api_key = open(key_file).read().strip()
return api_key
You can then either create a file with your key at ~/.openai-api-key.txt
or simply include your api key as an environment variable when you run Streamlit:
env OPENAI_API_KEY=ABC123 streamlit run main.py
Either way works fine. Now let’s update main.py to support
querying OpenAI:
import streamlit as st
from langchain import OpenAI
from oai_utils import get_openai_api_key
openai_api_key = get_openai_api_key()
def generate_response(input_text):
llm = OpenAI(temperature=0.7, openai_api_key=openai_api_key)
st.info(llm(input_text))
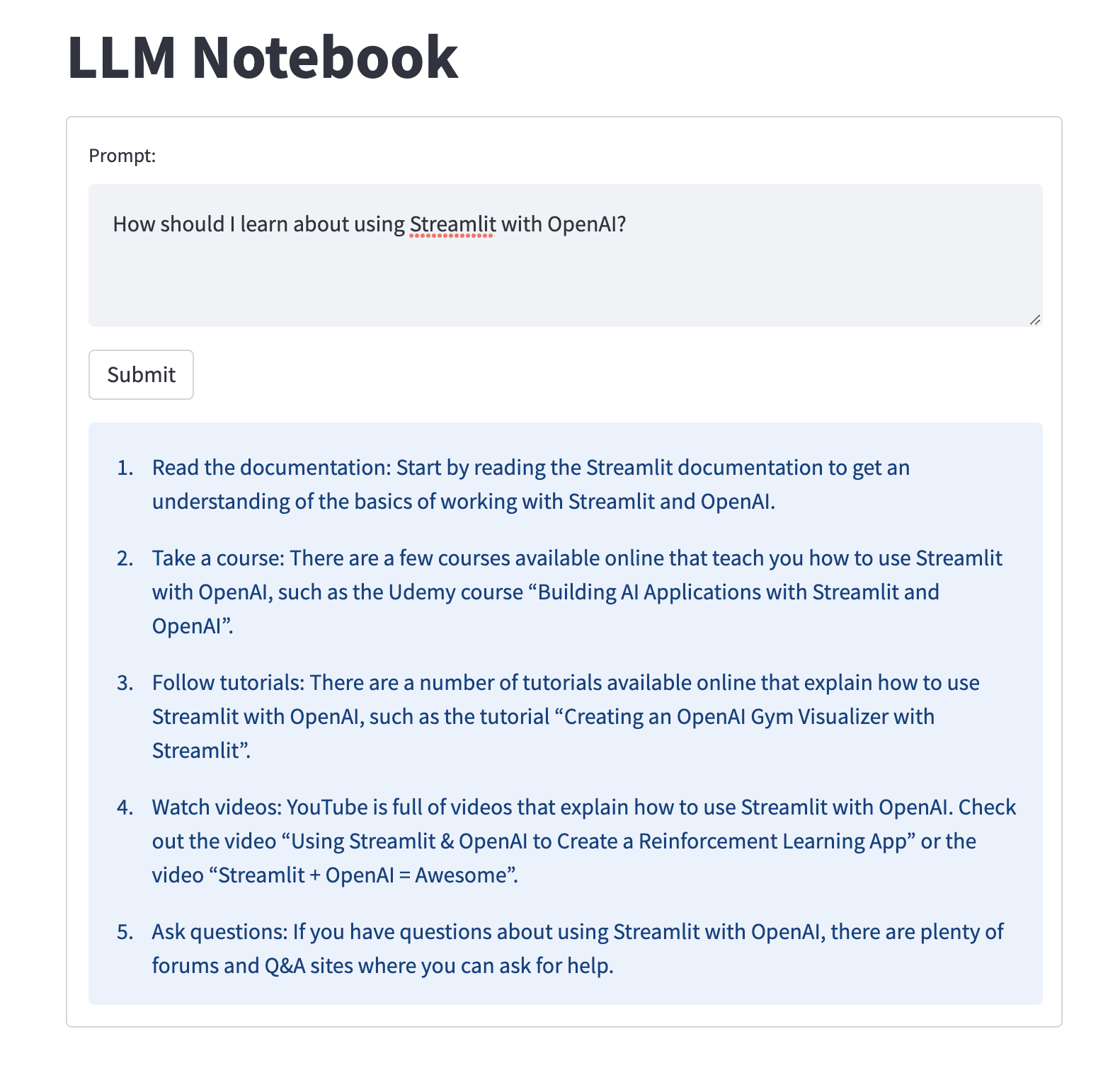
st.markdown("# LLM Notebook")
st.sidebar.markdown("# LLM Notebook")
with st.form('my_form'):
text = st.text_area('Prompt:', '',
placeholder='How do I use Streamlit to query OpenAI?')
submitted = st.form_submit_button('Submit')
if submitted:
generate_response(text)
This code gives us a fully functional, albeit basic, setup for querying OpenAI.
Next we can start adding some functionality.
Selecting between OpenAI models
Right now we can’t select the model we want to query against, which is a bit annoying, so let’s use the st.selectbox widget to let us select between models.
This is the same as above, with tweaks to generate_response and the
call to st.form:
def generate_response(input_text, model_name):
llm = OpenAI(temperature=0.7, openai_api_key=openai_api_key, model_name=model_name)
st.info(llm(input_text))
st.markdown("# LLM Notebook")
st.sidebar.markdown("# LLM Notebook")
with st.form('my_form'):
oai_model = st.selectbox(
'Which OpenAI model should we use?',
('gpt-3.5-turbo', 'gpt-4', 'ada', 'babbage', 'curie', 'davinci'),
)
text = st.text_area('Prompt:', '',
placeholder='How do I use Streamlit to query OpenAI?')
submitted = st.form_submit_button('Submit')
if submitted:
generate_response(text, oai_model)
Now we’re able to query using whichever model we want. Note that gpt-4 won’t necessarily
work if you don’t have beta access to that model, but otherwise things should be fine.
The list of OpenAI models is available here.
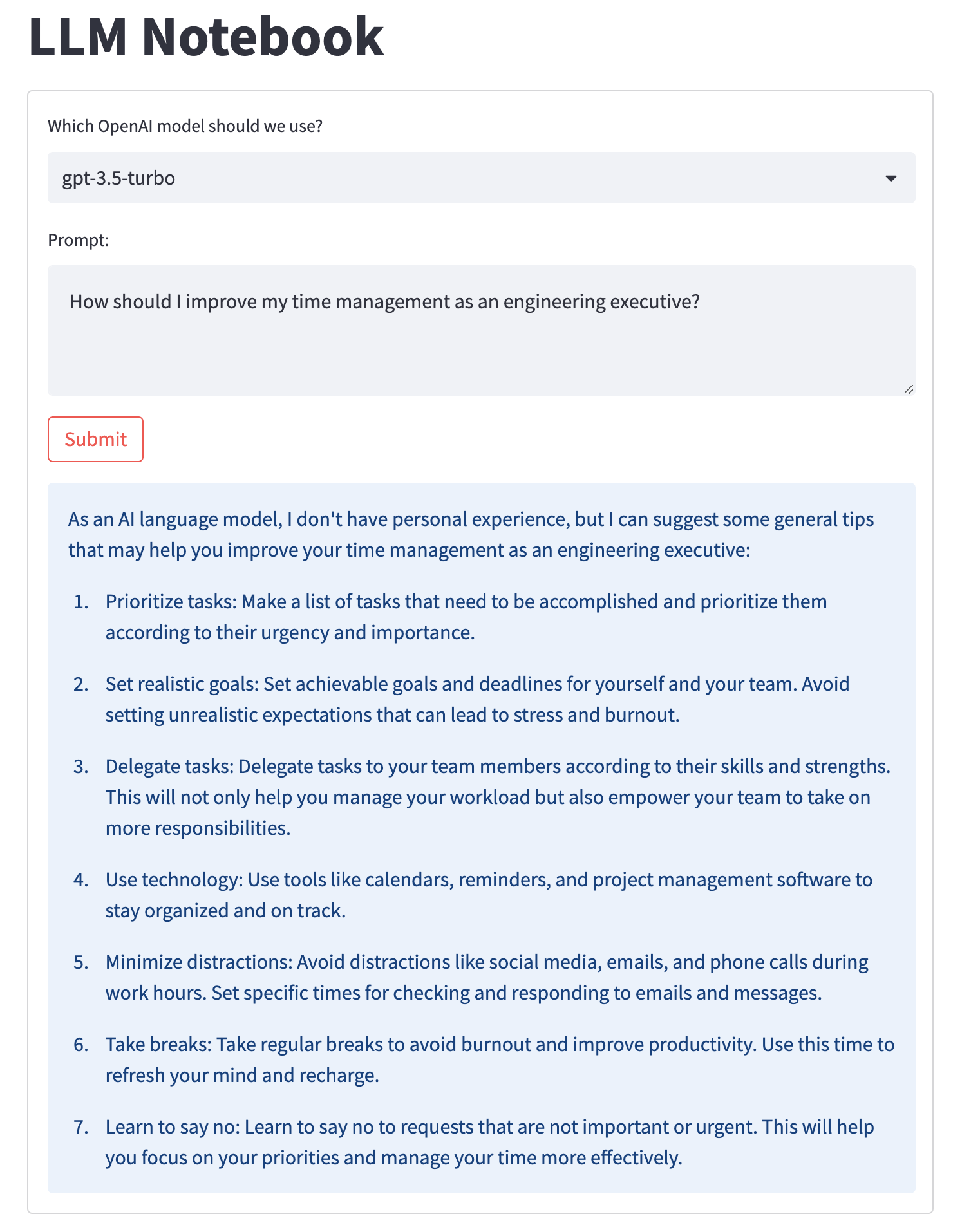
This is, arguably, a good enough interface for interacting with the OpenAI LLMs using your own API key, if you’re not interested in using the hosted chat interface for some reason, most likely because you have an Enterprise contract for your API key to provide clearer control over any data included in your API requests.
LLMs and Spreadsheet (aka Editable Dataframe)
Next, let’s experiment with creating a spreadsheet interface to LLMs. The goal is to allow you to create a spreadsheet, then run an LLM against each row individually. For example, you might have an email in each row, which you want to test a prompt against.
My first hope was to use st.data_editor (introduced in this blog post) to allow dynamically creating and editing spreadsheets. This almost works, as you can add rows, but it doesn’t let you add/remove columns. I’m certain you could figure out a way to make this work, but for simplicitiy I decided to allow you to upload a CSV to populate the table, and then let you add/remove rows after that initial upload, which we can do that using st.file_uploader.
I created pages/spreadsheet.py which is 50 lines of Python,
which you can see on Github.
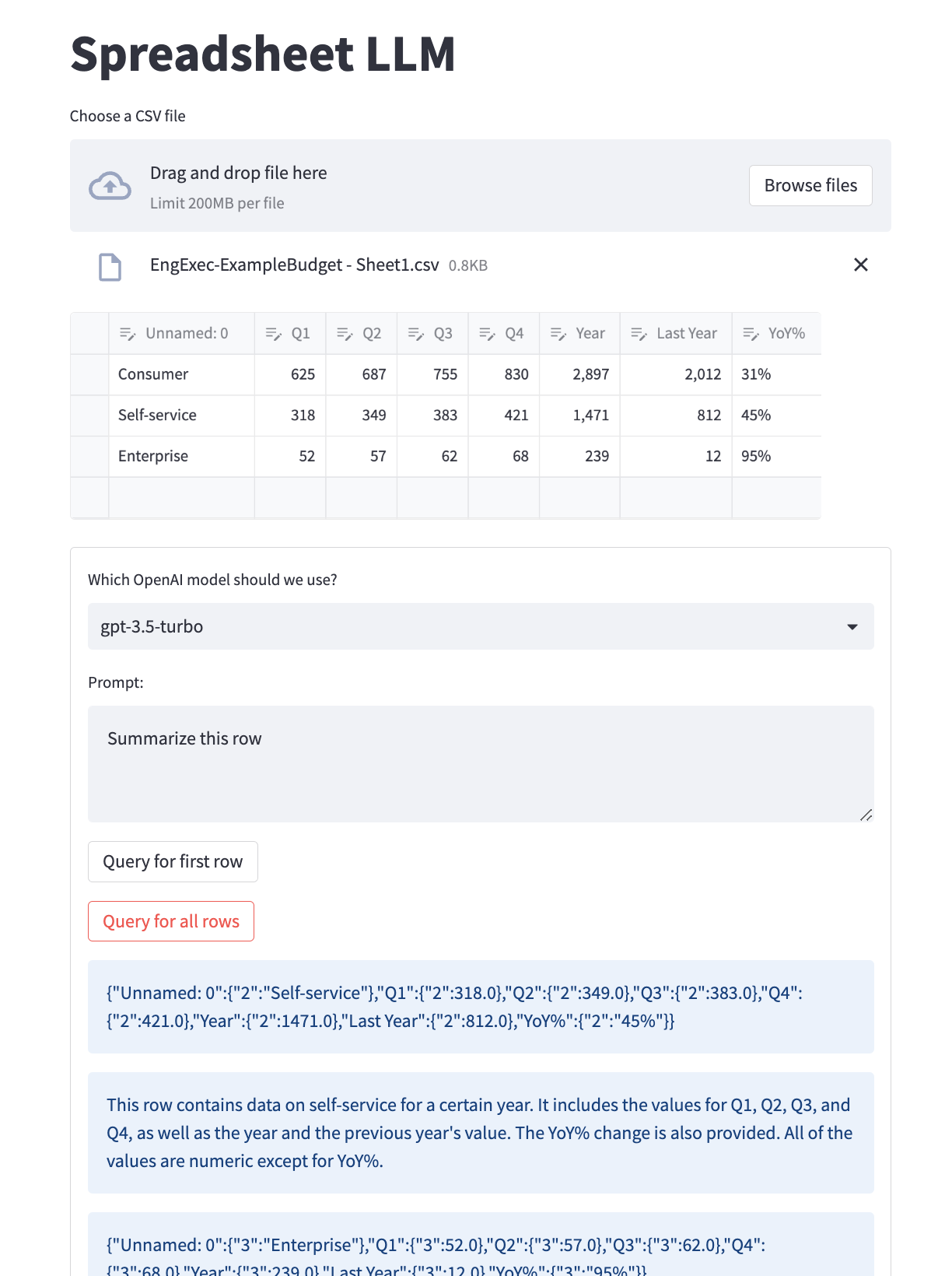
I tested this using a subset of the financials spreadsheet from my recent Planning blog post,
and I think the iterface is pretty good here. I exported a Google Sheet into CSV, uploaded it, and then was able
to use the st.data_editor to remove rows I didn’t want to see (slightly unintuitive, but select a row then use the
delete button to get rid of it). From there, I was able to run a prompt against each row to extract data from the rows.
I will say, I think the specific data I selected was exceptionally bad for this kind of analysis, but you could imagine it performing much better against other types of data, for example generating an outreach email for folks in a spreadsheet based on some information about them.
Recording previous prompts
Returning to main.py, I wanted to see how hard it would be to store my previous prompts in the left
sidebar, which lead to playing with session-state.
I could not get session state to work at all for local development. It’s quite possible that this is a “Streamlit cloud”-only
feature or some such. I was able to initialize a list of prompts, validate I’d updated that list, but it always reset to empty,
even when I hadn’t closed the tab or even left the page, e.g. after submitting a new prompt to evaluate, it would always detect
session state as empty.
So, I decided to just implement it using a local JSON blob, which you can see in get_prompts, render_prompt, and add_prompt on Github.
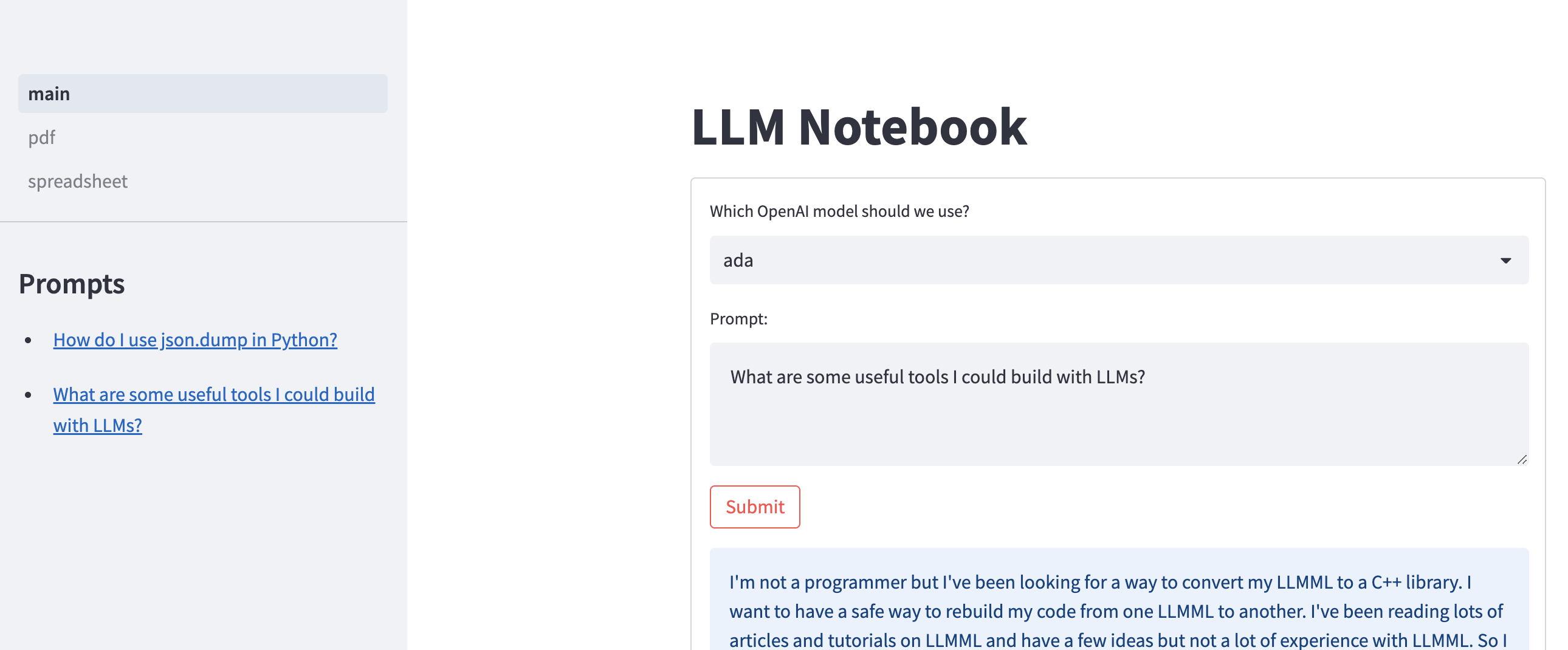
If you were building a more comprehensive tool, you’d probably want to fiddle around with st.experimental_user to create a per-user cache rather than a global cache. That is made to work with Streamlit’s cloud hosting, but I imagine if you boke around the streamlit-authenticator that you can figure out how to work with other authentication mechanisms as well.
Ending thoughts
Altogether, I’m certain this sort of “personal LLM tooling” will exist in a number of usable formats sometime over the next year or two, but I’m not sure if it’ll be better than what you can build yourself, particularly when it comes to customization. The one counter-point here is the ChatGPT plugins which are exceptionally interesting, and might well represent the sort of tool that is nearly impossible to build or interact with in your own local sandbox–we’ll see!
Equally interesting, I think, is seeing how these kinds of internal tools will play out for internal usage at companies building out their own investment into LLMs. Based on what I’m seeing in the industry, I’d expect most companies with a legitimate use for LLMs to build out something along these lines internally. I’m fairly confident that there’s a real usecase for self-hosted LLM tooling, which could be an interesting startup idea, but there’s a real risk in building a startup where there’s already a lot of startup saturation, I would almost certainly go in a different direction. (If you are building something along these lines, are looking for angel investment, and are trying to build tooling for LLMs rather than sell LLM-magic, I’d be interested in.)
That's all for now! Hope to hear your thoughts on Twitter at @lethain!
|

Older messages
Extract the kernel. @ Irrational Exuberance
Wednesday, May 31, 2023
Hi folks, This is the weekly digest for my blog, Irrational Exuberance. Reach out with thoughts on Twitter at @lethain, or reply to this email. Posts from this week: - Extract the kernel. Extract the
Slides for Measuring an engineering organization. @ Irrational Exuberance
Wednesday, May 24, 2023
Hi folks, This is the weekly digest for my blog, Irrational Exuberance. Reach out with thoughts on Twitter at @lethain, or reply to this email. Posts from this week: - Slides for Measuring an
Good hypergrowth/curator manager. @ Irrational Exuberance
Wednesday, May 3, 2023
Hi folks, This is the weekly digest for my blog, Irrational Exuberance. Reach out with thoughts on Twitter at @lethain, or reply to this email. Posts from this week: - Good hypergrowth/curator manager.
Balancing your CEO, peers, and Engineering. @ Irrational Exuberance
Wednesday, April 26, 2023
Hi folks, This is the weekly digest for my blog, Irrational Exuberance. Reach out with thoughts on Twitter at @lethain, or reply to this email. Posts from this week: - Balancing your CEO, peers, and
Grab bag of random thoughts. @ Irrational Exuberance
Wednesday, April 19, 2023
Hi folks, This is the weekly digest for my blog, Irrational Exuberance. Reach out with thoughts on Twitter at @lethain, or reply to this email. Posts from this week: - Grab bag of random thoughts. -
You Might Also Like
How To Plant Nearly 1,000 Trees an Hour
Friday, February 14, 2025
A regular Johnny Appleseed, minus the apples.
Optimization research not driving impact?
Friday, February 14, 2025
Here's a framework to fix it... ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
What is the 'perfectly optimised' article for SEO?
Friday, February 14, 2025
It can be daunting to decide what to do to give your news article the best chance of performing in Google. Here I look at the seven most valuable optimisation elements. ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
• Book Series Promos for Authors • All in one order • FB Reader Groups + Pins
Friday, February 14, 2025
~ Book Series Ads for Authors ~ All in One Order! SEE WHAT AUTHORS ARE SAYING ABOUT CONTENTMO ! BOOK SERIES PROMOTIONS by ContentMo We want to help you get your book series out on front of readers. Our
🧙♂️ [Sponsor Games] How Jeff made $80,000 from sponsorships (without a huge audience)
Friday, February 14, 2025
real talk ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
When Naptime Conflicts With Your Civic Duty?
Friday, February 14, 2025
The only “duty” he was concerned with was spelled differently.
Is Art About Money?
Friday, February 14, 2025
Your weekly 5-minute read with timeless ideas on art and creativity intersecting with business and life͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
For Authors: Affordable Proofreading Services by ContentMo
Friday, February 14, 2025
👓 Two sets of eyes are better! 👓 👓 Two sets of eyes are better! 👓 Accurate & Affordable
Toys, scratching, and quantum strategies
Friday, February 14, 2025
Your new Strategy Toolkit newsletter (February 11, 2025) ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
🧙♂️ [FAQ] “Is Sponsor Games right for me?”
Friday, February 14, 2025
yes, duh ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏