📝 Guest Post: Retrieval Augmented Generation on Notion Docs via LangChain*
Was this email forwarded to you? Sign up here In this guest post, Yujian Tang, a developer advocate at Zilliz, explores how to enhance Notion documents with language model interactions using LangChain and Milvus. He lays out a step-by-step guide to build a basic retrieval augmented generation (RAG) system, covering everything from ingestion to querying. A comprehensive read for those keen on bridging Notion with cutting-edge tech. Let's dive in. Do you have Notion docs you want to ask a language model to query for you? Let’s build a basic retrieval augmented generation (RAG) type app using LangChain and Milvus. We use LangChain for the operational framework and Milvus as the similarity engine. You can find the notebook for this blog on colab. In this tutorial we go through the following:
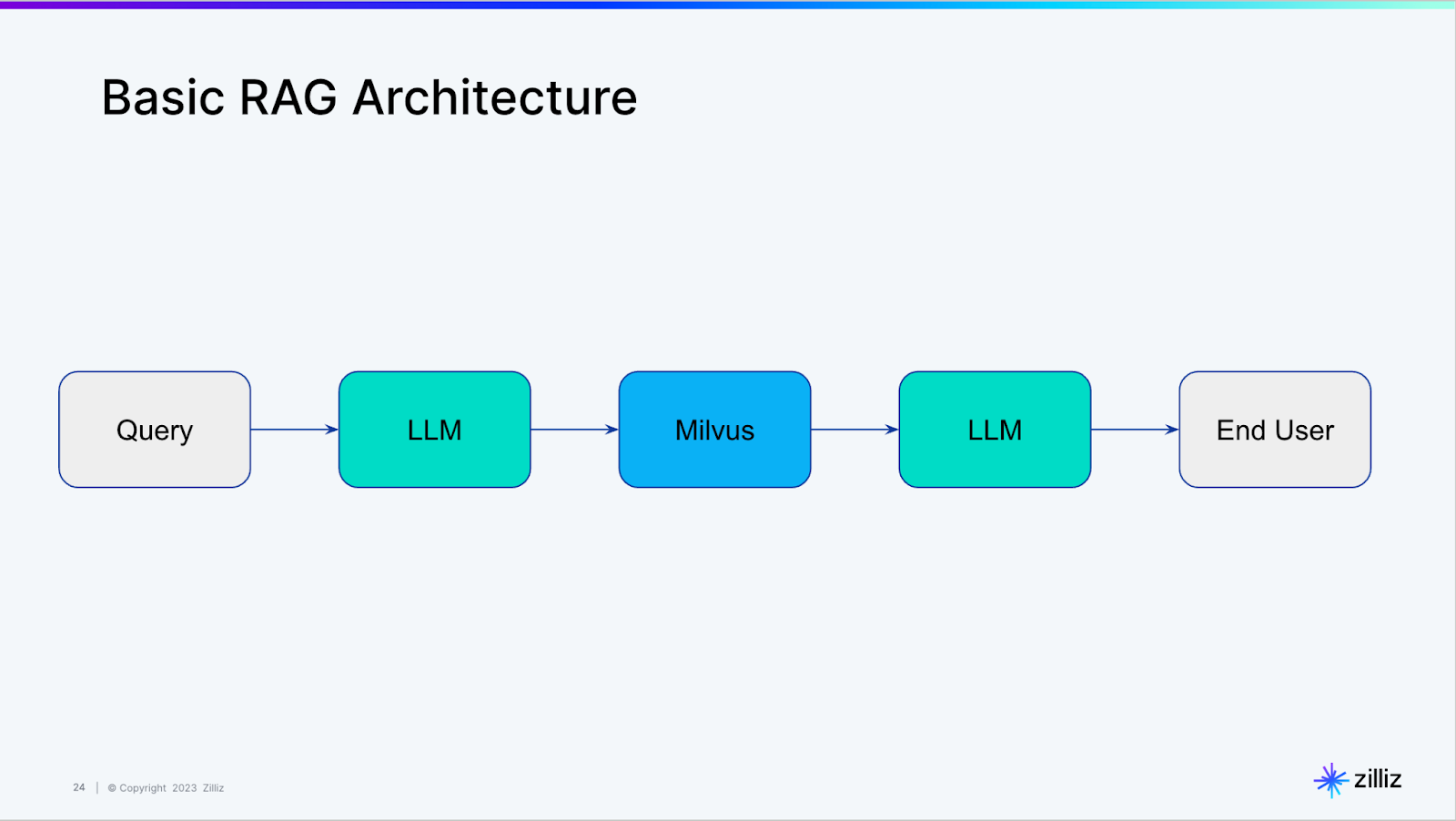
Review of LangChain Self QueryingWe recently covered how to use LangChain to query a vector database, an introduction to what LangChain dubs “self-querying”. Behind the scenes, the self-querying functionality in LangChain is constructing a basic RAG architecture like the one shown below.
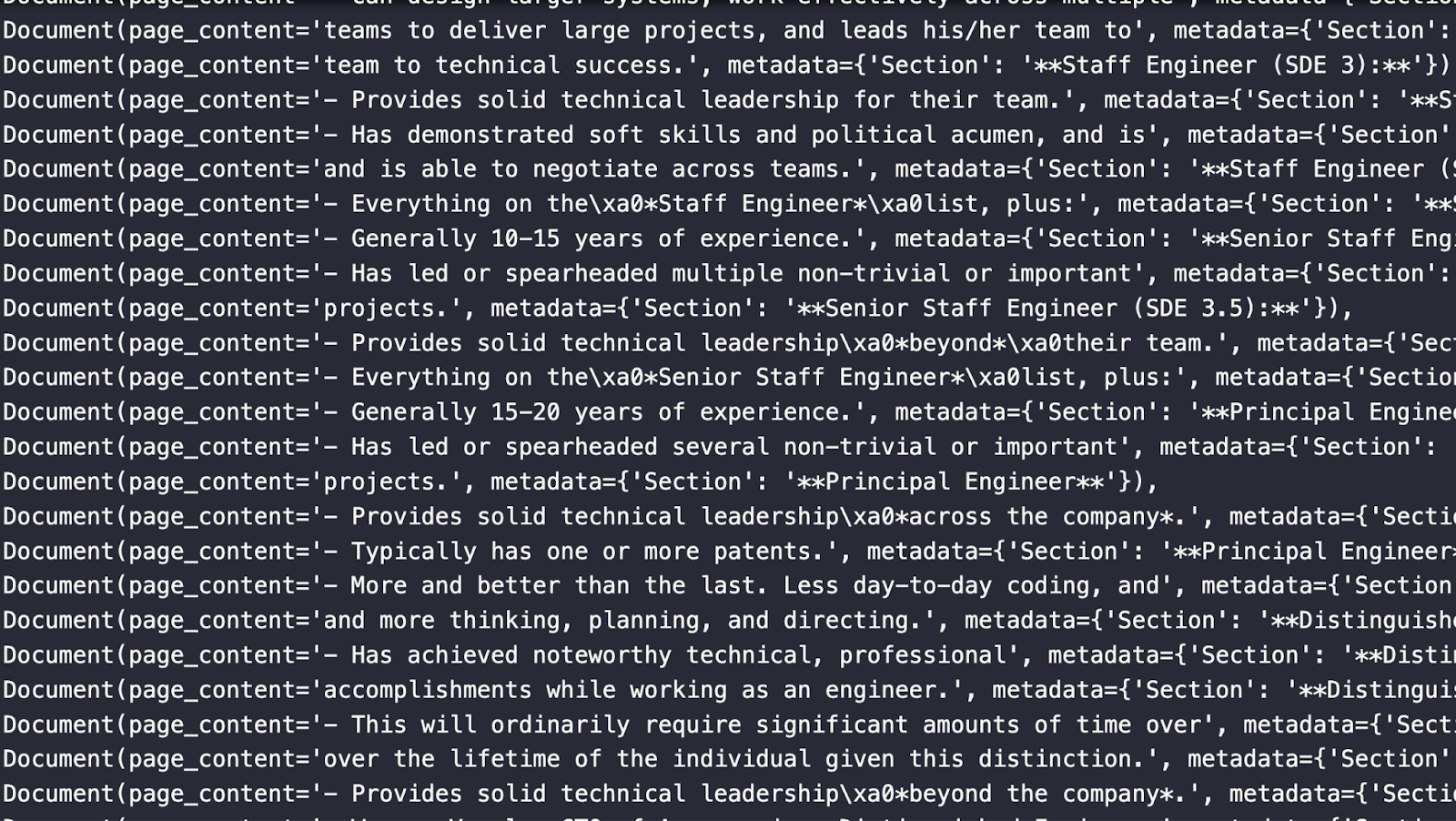
Working with Notion Docs in LangChainI will to split this into three steps: ingesting, storing, and querying. Ingestion covers getting your Notion documents and loading the contents into memory. Storage covers spinning up a vector database (Milvus), vectorizing the documents, putting them into the vector database, and querying covers asking a question about your Notion documents. Ingesting Your Notion DocumentsWe use the `NotionDirectoryLoader` from LangChain to load the documents into memory. We provide the path to our docs and call the `load` function to get them. Once the documents are loaded in memory, we grab the markdown file, in this case, just one. Next, we use the markdown header text splitter from LangChain. We feed it a list of dividers to split on and then pass the previously named `md_file` to get our splits. When you define your `headers_to_split_on` list, make sure you use the headers you use in your Notion doc, not just the examples I provided. In the code below, we perform and examine our splits. We use LangChain’s `RecursiveCharacterTextSplitter`, which tests some different characters to split on. The four default characters to check are a newline, a double newline, a space, or no space. You can also opt to pass on your own with a `separators` parameter, which we did not use this time. The two essential hyperparameters to define when chunking your Notion doc are the chunk size and the chunk overlap. For this example, we use a chunk size of 64 and an overlap of 8. In the future, we will cover testing these values and finding good values. Once we define the text splitter, we call its `split_documents` functions to get all our Document splits. The image below shows some `Document` objects from the split above. Notice that it includes the page content and the metadata which includes the section that the content is pulled from.
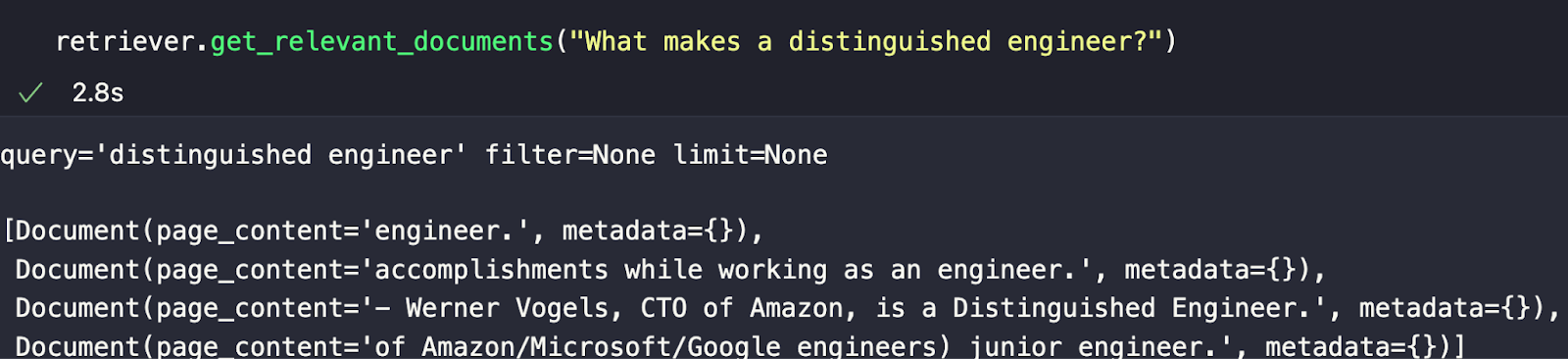
Storing Your Notion DocumentsWith all the documents loaded and split, it’s time to store those splits. First, we spin up our vector database directly in our notebook using Milvus Lite. We also need to get the necessary LangChain modules - `Milvus` and `OpenAIEmbeddings`. After the imports and standing up the vector database, we use LangChain’s Milvus module to create a collection from our documents. We need to pass it the document list, the embeddings to use, the connection parameters, and (optionally) a collection name. Querying Your Notion DocumentsEverything is set up and ready for querying. For this section, we need three more imports from LangChain - OpenAI for accessing GPT, the `SelfQueryRetriever` to make our basic RAG, and the “Attribute info” object to pass the metadata. To kick it off, we define some metadata. For this example, just the sections that we’ve been using so far. We also give the self-query retriever a description of the documents. In this case, simply “major sections of the document”. Right before we instantiate our self-query retriever, we set a 0 temperature version of GPT to an `llm` variable. With the LLM, the vector database, the document description, and the metadata fields ready, we define the self-query retriever. My chosen example is “What makes a distinguished engineer?” From the response in the image below, we can see the most semantically similar chunks returned. As we can see, just because they are the most semantically similar responses doesn’t mean they’re the right ones. In future pieces, we will cover how to experiment with chunking and other techniques to improve our responses.
Summary of Querying Notion Docs in LangChainIn this tutorial, we covered how to load and parse a Notion doc into sections to query in a basic RAG architecture. We used LangChain as the orchestration framework and Milvus as our vector database. LangChain puts the pieces together, and Milvus drives the similarity search. To take this tutorial further, there are many things we can test. Examples of two hyperparameters to check are the chunk size and the overlap size between chunks. We can use these to tune our responses and what they look like. Aside from tuning, we also need to evaluate the responses. In future tutorials, we will look at different chunking strategies. Not only that, but we will also take deeper looks into embeddings, splitting strategies, and evaluation. *This post was written by Yujian Tang, a developer advocate at Zilliz. We thank Zilliz for their ongoing support of TheSequence.You’re on the free list for TheSequence Scope and TheSequence Chat. For the full experience, become a paying subscriber to TheSequence Edge. Trusted by thousands of subscribers from the leading AI labs and universities.
|


Older messages
Edge 335: LoRA Fine-Tuning and Low-Rank Adaptation Methods
Thursday, October 19, 2023
Diving into one of the most popular fine-tuning techniques for foundation models.
The Sequence Chat: Shreya Rajpal, Co-Founder and CEO, Guardrails AI About Ensuring the Safety and Robustness of LL…
Thursday, October 19, 2023
The co-creator of one of the most important LLM guardrails frameworks shares her perspectives on building safe, robust and efficient LLM applications, the architecture of Guardrails AI and more.
Edge 333: Understanding Parameter Efficient Fine Tuning
Tuesday, October 10, 2023
An overview of PEFT, one of the most important fine-tuning methods ever created;
📡 WEBINAR: Unraveling prompt engineering
Monday, October 9, 2023
You can't talk about LLMs without talking about prompt engineering – and at first glance, prompting may appear intuitive and straightforward, but well, it ain't. Join us for the next webinar of
The Most Obvious Secret in AI: Every Tech Giant Will Build Its Own Chips
Sunday, October 8, 2023
Sundays, The Sequence Scope brings a summary of the most important research papers, technology releases and VC funding deals in the artificial intelligence space.
You Might Also Like
Import AI 399: 1,000 samples to make a reasoning model; DeepSeek proliferation; Apple's self-driving car simulator
Friday, February 14, 2025
What came before the golem? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
Defining Your Paranoia Level: Navigating Change Without the Overkill
Friday, February 14, 2025
We've all been there: trying to learn something new, only to find our old habits holding us back. We discussed today how our gut feelings about solving problems can sometimes be our own worst enemy
5 ways AI can help with taxes 🪄
Friday, February 14, 2025
Remotely control an iPhone; 💸 50+ early Presidents' Day deals -- ZDNET ZDNET Tech Today - US February 10, 2025 5 ways AI can help you with your taxes (and what not to use it for) 5 ways AI can help
Recurring Automations + Secret Updates
Friday, February 14, 2025
Smarter automations, better templates, and hidden updates to explore 👀 ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
The First Provable AI-Proof Game: Introducing Butterfly Wings 4
Friday, February 14, 2025
Top Tech Content sent at Noon! Boost Your Article on HackerNoon for $159.99! Read this email in your browser How are you, @newsletterest1? undefined The Market Today #01 Instagram (Meta) 714.52 -0.32%
GCP Newsletter #437
Friday, February 14, 2025
Welcome to issue #437 February 10th, 2025 News BigQuery Cloud Marketplace Official Blog Partners BigQuery datasets now available on Google Cloud Marketplace - Google Cloud Marketplace now offers
Charted | The 1%'s Share of U.S. Wealth Over Time (1989-2024) 💰
Friday, February 14, 2025
Discover how the share of US wealth held by the top 1% has evolved from 1989 to 2024 in this infographic. View Online | Subscribe | Download Our App Download our app to see thousands of new charts from
The Great Social Media Diaspora & Tapestry is here
Friday, February 14, 2025
Apple introduces new app called 'Apple Invites', The Iconfactory launches Tapestry, beyond the traditional portfolio, and more in this week's issue of Creativerly. Creativerly The Great
Daily Coding Problem: Problem #1689 [Medium]
Friday, February 14, 2025
Daily Coding Problem Good morning! Here's your coding interview problem for today. This problem was asked by Google. Given a linked list, sort it in O(n log n) time and constant space. For example,
📧 Stop Conflating CQRS and MediatR
Friday, February 14, 2025
Stop Conflating CQRS and MediatR Read on: my website / Read time: 4 minutes The .NET Weekly is brought to you by: Step right up to the Generative AI Use Cases Repository! See how MongoDB powers your