| Introduction | The Mamba architecture, introduced in December 2023, has become a significant development in sequence modeling. We briefly discussed it previously in our weekly digest, asking, "What is Mamba and can it beat Transformers?" | This article, part of our AI 101 series, explores Mamba's origins, the issues it addresses, and goes deeper in why it might be a better alternative to transformer models. With its efficient scaling of context length and linear computational costs, Mamba offers a promising solution for handling large-scale data challenges in AI. | In today’s episode, we will cover: | Sequence modeling, transformers, and foundation models What’s wrong with transformers? Here come SSMs and Mamba Why is Mamba getting attention? Conclusion Bonus: Mamba-related research papers worth reading:
| Sequence modeling, transformers, and foundation models | First, let's understand the context of foundation models, transformers, and related concepts. It’s called sequence modeling, an area of research driven by sequential data, meaning it has some inherent order inside. It can be text sentences, images, speech, audio, time series, genomics, etc. | In the 1990s and 2000s, sequence modeling advanced significantly due to the rise of neural network architectures and increased computing power. Models like Long Short-Term Memory (LSTM) and recurrent neural networks (RNNs) became the standards. These models are excellent at handling variable-length sequences and capturing long-term dependencies. However, their sequential data processing nature makes it challenging to parallelize operations within a single training example. | | In 2017, the introduction of the transformer architecture marked a significant change in sequence data processing. Transformers use attention mechanisms, eliminating the need for the recurrence or convolution used in earlier models. This design enhances parallelization during training, making transformers more efficient and scalable for handling large datasets. | | The self-attention mechanism in transformers computes the relevance of all other parts of the input sequence to a particular part. This is done for all parts of the sequence simultaneously, which is inherently parallelizable. Each attention head can independently calculate the attention scores for all positions in the input sequence, making these operations run concurrently. This differs drastically from RNNs where outputs are computed one after the other. This results in markedly faster training times and the ability to handle larger datasets more efficiently. | Okay, so Transformers really became backbone of modern foundation models. As ChatGPT would say, they really propelled their development! But transformers are not the only one in sequence modeling, and it turned out they have some problems with long context. So it’s time to turn to our main topic – Mamba. | What’s wrong with transformers? | The rest of this article, with detailed explanations and best library of relevant resources, is available to our Premium users only –> | |
|
| While transformers have many advantages, they are not without drawbacks. One limitation lies in the mechanism of self-attention, which necessitates choosing a finite, or limited, context window. Self-attention enables each segment of the sequence to consider other relevant segments, yet its scope is inherently restricted. Each element can only interact with a specified range of nearby elements, rather than the entire sequence simultaneously. This is what we now call a “context window.” |  | Image Credit: Stanford University course "Natural Language Processing
with Deep Learning CS224N/Ling284 |
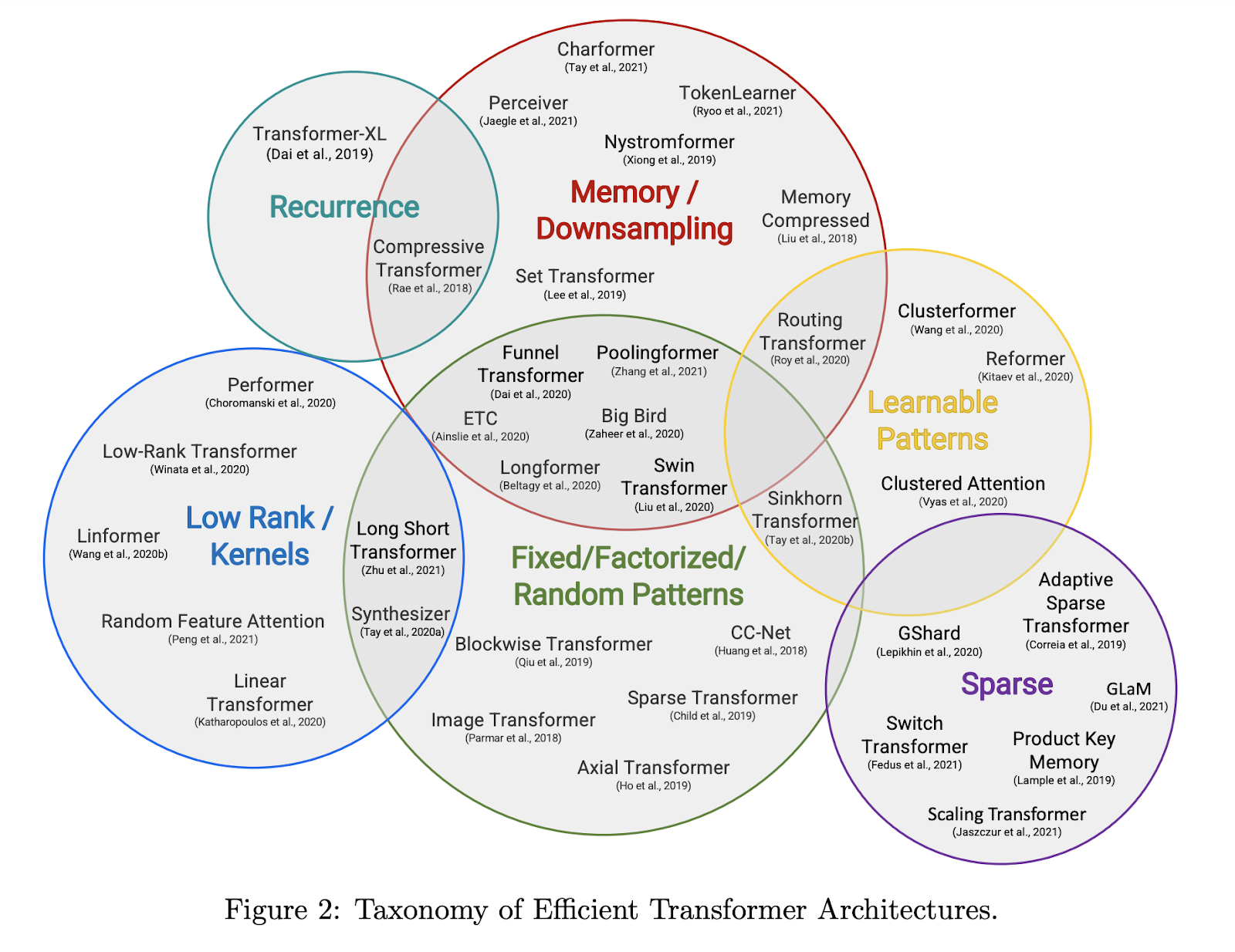
| Moreover, increasing the size of this context window exacerbates computational demands, leading to quadratic scaling with respect to the window length. Specifically, if the context length is x, the computational resources required to scale is x2. | That’s a lot. | Here come SSMs and Mamba | Recently, state space sequence models (SSMs), including a variant known as Mamba, have emerged as potential successors to transformers in sequence modeling. These models address some of the fundamental limitations inherent to transformers. | It's important to recognize that SSMs like Mamba specifically tackle certain constraints of transformers, yet many other approaches also seek to enhance transformer efficiency. The paper "Efficient Transformers: A Survey" extensively discusses these methodologies and illustrates them in the image below. For example, last time, we talked about Mixture-of-Experts (MoE), categorized under "Sparse" models in the provided Venn diagram. | | State space models (SSMs) | Overall, the approach of using state space models draws us back to dynamic systems which are described using differential equations. A dynamic system is any system, man-made, physical, or biological, that changes in time. Think of the Space Shuttle in orbit around the earth, an ecosystem with competing species, the nervous system of a simple organism, or the expanding universe, these are all systems. |  | Introduction to State-Space Equations | State Space, Part 1 |
|
| State space models are extensively used in many other sciences but are relatively overlooked in machine learning. It was because they struggled even on simple tasks before introducing special state matrices*. With these matrices, state space models achieve exceptional performance. | *State matrices are fundamental components of state-space models. These matrices form part of a mathematical framework that describes how the state of a system evolves over time in response to inputs.
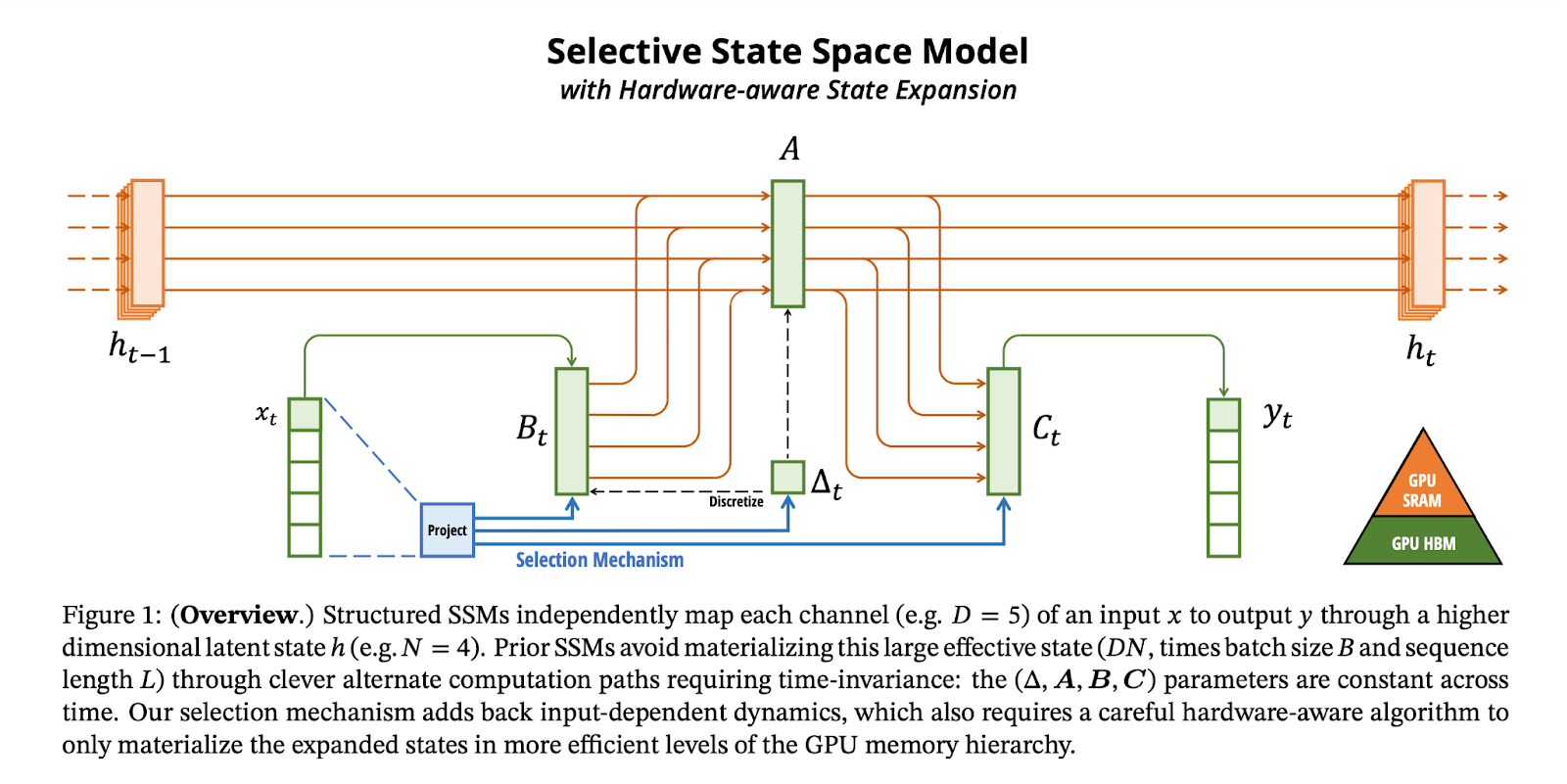
| Structured state space sequence models were proposed in 2021 by three researchers from Stanford University: Albert Gu, Karan Goel, and Christopher Ré, and were an extension of their previous work. These models blend elements from recurrent neural networks (RNNs) and convolutional neural networks (CNNs), drawing from classical state space principles. Nonetheless, they tend to underperform with discrete, dense data like text. | Mamba | As a response to early SSMs, researchers from Carnegie Mellon University and Princeton introduced the Mamba model, an innovative selective state space model that overcomes the drawbacks of both Transformers and traditional SSMs. | | The Mamba architecture incorporates selective state space models into a neural network framework to eliminate traditional components such as attention and Multilayer Perceptron (MLP) blocks. | Key features of the Mamba architecture: | Selective SSMs: Similar to structured SSMs, selective SSMs in Mamba are standalone sequence transformations integrated into neural networks. These SSMs allow parameters to adapt based on input, optimizing information propagation throughout the sequence. This feature supports Mamba's capacity for high-efficiency content-based reasoning across diverse modalities such as language, audio, and genomics. Simplified structure: Mamba simplifies traditional complexity by merging the linear attention and MLP blocks into the "Mamba block." The architecture simplifies further by using several identical Mamba blocks stacked one after another instead of mixing different types of blocks. This uniformity contributes to the simplicity and efficiency of the model. See the diagram above. Hardware-aware algorithm: To tackle the computational inefficiencies caused by SSMs, researchers came up with a clever hardware-aware parallel algorithm. Instead of using convolution, this algorithm uses a scan operation, which helps in managing state expansion within the memory hierarchy of modern GPUs. This boosts speed and cuts down on memory overhead.
| Why is Mamba getting attention? | The short answer is: larger context window. Recently, we observed a race to scale the context length of the large language models (LLMs) by main LLM providers. One of the prominent examples is Chinese Moonshot AI which made lossless long context part of their strategy. With its linear-time complexity, Mamba architecture is a great candidate to scale the context length efficiently. | Despite its simplified structure, Mamba achieves state-of-the-art performance, demonstrating capabilities that are superior to or comparable with Transformers twice its size in tasks like language modeling. | Its main advantages: | Linear-time complexity: The system is designed to ensure that both the cost of computation and memory usage increase proportionally with the length of the input sequence. This is an improvement over traditional models like Transformers, which have a quadratic scaling. High throughput and performance: Mamba simplifies the computational process and improves throughput, achieving up to 5 times higher performance than Transformers. It maintains its ability to handle dense and complex modalities like language, genomics, and audio. On real datasets, it shows improvements for sequences of up to one million elements. Selective SSMs integration: Selective SSMs are fully recurrent models that offer strong performance benefits due to their selectivity. They are well-suited as a general foundation model for various sequence-based applications.
| Conclusion | The advent of the Mamba architecture is a fascinating update to transformers integrating state space models into sequence modeling. It’s a promising approach that could potentially allow us to achieve new levels of efficiency and scalability in foundation models. And it demonstrates again: the innovation are based on the previous research and it’s important to know your ML history. | Bonus: Mamba-related research papers worth reading: | | How did you like it? | |
|
| Thank you for reading! Share this article with three friends and get a 1-month subscription free! 🤍 | |
|
|
|