| Recent events have highlighted both the potential and pitfalls of AI integration in search technology. Google's new AI Overviews feature, intended to generate AI-based responses for user queries, has produced some absurd and incorrect answers, like suggesting users add glue to their pizza to keep the cheese from falling off. Despite these missteps, giants like Microsoft and Apple are also working on integrating AI into their search engines. | With so much focus on US companies, it's easy to overlook developments in countries like China, India, and Russia. LLMs built for these languages are distinct from their English equivalents and deserve attention. Today, we speak with Petr Ermakov, who will share how Russia's biggest search engine, Yandex, has journeyed in developing powerful AI models, the challenges they've overcome, how they see AI integration in search engines, and their vision for the future of search. | Hi Petr, thanks for joining us today! Most of the LLMs we hear about are in English, but there are so many other languages out there, like Chinese and Russian. Tell us about your experience creating YandexGPT. | As one of the biggest search engines, we had a unique position to build our own LLM. YandexGPT was trained on vast amounts of Russian and English texts, with smaller amounts of text in other languages also incorporated into the training. | For YandexGPT we chose the transformer architecture, with a three-stage training process: | Pre-training stage: YandexGPT was trained on 20TB of text data. Alignment stage: YandexGPT was fine-tuned using 10,000 questions and answers written by 300 AI trainers. Reinforced learning (RL) stage: the model was further trained on 30,000 ranked YandexGPT answers.
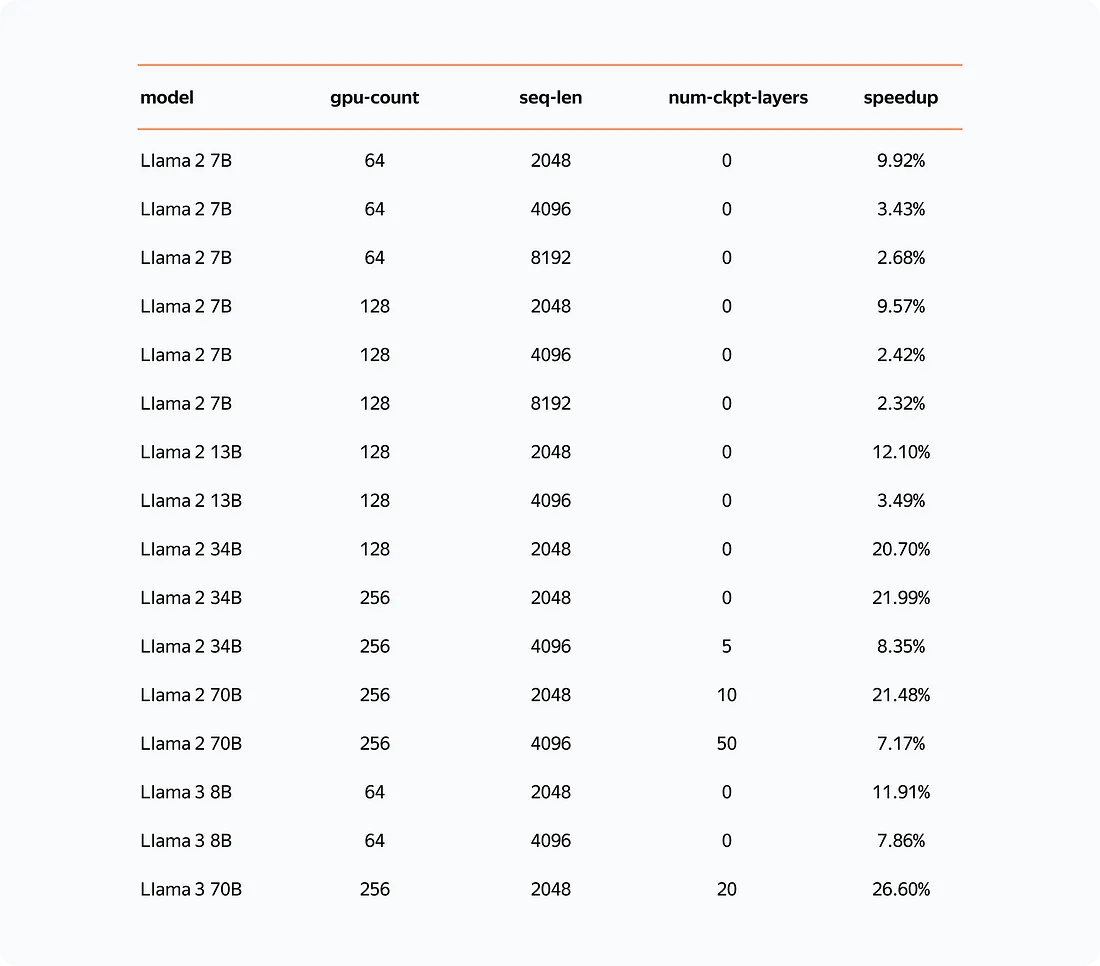
| For the pre-training stage, we used a dataset that included texts from diverse sources such as books, magazines, newspapers, and open-source internet content. For the alignment and reinforced learning stages, a team of over 300 AI trainers collected question-answer pairs and ranked model responses. Additionally, we analyzed potential applications of the LLM in our company’s business cases and created sets of potential questions for the model. | When testing the LLM internally, we focused on the performance of YandexGPT on internal benchmarks in both Russian and English. To assess the performance of YandexGPT 3 Pro, the latest version of our LLM, our developers used multiple tests. One of them is YaMMLU_ru, a localized version of the international MMLU benchmark. We also monitor its performance in the languages of our other products. We also observe a positive side effect in the quality of our language model's performance in most of the languages that were included in its training.We used the side by side (SBS) testing method to assess how the new model handles simple user requests and complex tasks, such as generating ideas, creating content, as well as summing up and classifying information, and discovered that, on average, YandexGPT Pro performed better than YandexGPT 2 and ChatGPT 3.5 67% and 64% of the time, respectively. | What were the challenges? | One of the challenges in this process was selecting a high-quality text dataset. To address this, we leveraged all our experience and assembled a high-quality text filtering pipeline for the pre-training model. | Another challenge was related to GPU optimization. | As you know, LLM training relies on numerous GPUs organized into clusters — arrays of interconnected graphics processors that can perform the vast number of calculations necessary to train models with billions of parameters. Distributing computations among processors within a cluster requires constant communication, which often becomes a "bottleneck", slowing the training process and resulting in inefficient use of computing power. | We faced this issue when developing YandexGPT 3, our latest large language model. To overcome this bottleneck and make LLM training more efficient, we created YaFSDP, a library that improves GPU communication and optimizes learning speed and performance. When combined with our other performance-enhancing solutions, the library accelerated the training process by up to 45% for some of our models. | | In our AI 101 series, we actually covered FSDP and YaFSDP in detail. Can you give us a short overview of how YaFSDP works? | YaFSDP works by eliminating GPU communication inefficiencies, ensuring that training requires only necessary processor memory and making GPU interactions uninterrupted. The tool optimizes learning speed and performance, enabling AI developers to use less computing power and GPU resources when training their models. | Here is the speed gain achieved by YaFSDP on Llama 2 and Llama 3 compared to FSDP: | | Now to the world of other search engines! What do you think about Google's recent AI Overview failure? Do you see it as a sign of bigger issues in developing AI for search? | We believe in healthy competition and never wish failure upon our rivals. For us, public criticism of some AI functions of competitors highlighted the importance of additional testing of such functionalities and the responsibility of companies providing AI tools. For instance, when introducing Neuro, our AI product that integrates search and generative AI, we paid special attention to the reliability and accuracy of its responses. | Yandex is often called Russia's Google, and the financial model of the search engine is pretty similar, right? How does AI impact Yandex’s business model? | Big tech companies like Yandex and Google offer a wide array of technology products. While they compete directly in some areas such as search, browsers, maps, and email, Yandex also provides technological products where Google does not have alternatives, such as taxi services, ready-to-eat food delivery, and online video streaming services. | As for the impact of AI on Yandex's products and technologies, it's difficult to find a single project in our company where AI technologies are not utilized — from recommendation systems and personalization to big data processing, large language models, speech technologies — we’ve been using them extensively for a long time and lately we’ve doubled down on making our efforts in AI more publicly available and transparent. | OpenAI is working on integrating AI with search features. How do you see this development affecting the competitive landscape for search engines? | Search engines serve as one of the primary gateways to the internet, operating as high load systems with some of the highest number of requests per second. Companies that seek to completely replace traditional search engines with LLM-based search will encounter significant challenges related to both resource requirements (such as GPU resources) and the potential for LLM hallucination. With almost 27 years of experience in search engine development, our company believes that the optimal approach will involve a balanced combination of traditional search and LLM-powered search. | With the latest advancements from OpenAI and Google in multimodal models, does Yandex plan adding multimodal capabilities to its AI models? | We are actively developing multimodal models and have recently launched Neuro, an AI product that can process multiple modalities: text, image, and audio. Our “superpower” in developing multimodal models is our extensive experience in each individual modality: for text, we’ve developed advanced search engine technologies; for images, we’ve created the YandexArt text-to-image generative model and an image search system, highlighting our strong optical character recognition (OCR) expertise; and for audio, we’ve developed our own multilingual voice assistant, Alice. | The primary challenge in multimodal model development lies in mastering each modality and creating high-quality training datasets. | | What other research areas, apart from your everyday job, are you following closely and think are essential for moving the AI industry forward? | We have a team of ML and AI experts with diverse interests who closely monitor the whole field. I'd like to highlight the following areas that our team is currently focused on: | Deep learning for tabular data. Quantization in large language models. Speculative decoding for interactive LLM inference. Fine-tuning text-to-image diffusion models with Reinforcement Learning from Human Feedback (RLHF) to align generated images with human preferences.
| What book would you recommend to aspiring data scientists/ML engineers? (It doesn’t necessarily have to be about ML!) | As data scientists, our work is often about exploring new frontiers in various domains. I recommend that aspiring data scientists — and perhaps even all readers of this article — revisit The Little Prince by Antoine de Saint-Exupéry. This book serves as a reminder that imagination and bold dreams are the fuel for our field's progress. | Thank you for reading! if you find it interesting, please do share or upgrade to Premium to support our effort 🤍 | |
|