| In JC’s Newsletter, I share the articles, documentaries, and books I enjoyed the most in the last week, with some comments on how we relate to them at Alan. I do not endorse all the articles I share, they are up for debate. I’m doing it because a) I love reading, it is the way that I get most of my ideas, b) I’m already sharing those ideas with my team, and c) I would love to get your perspective on those. If you are not subscribed yet, it's right here! If you like it, please share it on social networks! Share 💡JC's Newsletter
👉 Hey Tech, It’s Time To Build. In Healthcare. (Andreessen Horowitz) ❓ Why am I sharing this article? We don’t necessarily need more science in tech, we need to make it accessible to everyone with better consumer engagement and better product. This is what Alan is building. Healthcare is where AI is going to have the most impact. Why Alan is one of the most important mission on earth
The United States healthcare market is five times the size of the global advertising market in which the majority of the major tech companies operate. The American healthcare market could support dozens of FAANG (Facebook, Amazon, Apple, Netflix, Google)-scale companies, but today only one exists (UnitedHealth Group). To start, healthcare needs tech. While the PhDs developing novel cancer drugs and diagnostics are incredibly important, they are just a tiny part of this market. Even if we cure all cancer, Americans’ lifespan would just increase by three years. Instead, some of the biggest problems in healthcare are going to be solved by technology. Healthcare at its core is (1) a data, operations, and logistics problem, and (2) a consumer experience and engagement problem. Both are areas where the tech world excels.
When it comes to consumer engagement, we’ve written before about how poor consumer engagement, caused by poor consumer experience, is one of the biggest problems in healthcare. Most poor health outcomes and deaths are caused by diseases that we know how to prevent or cure. What’s needed in these scenarios is not more science. In addition to cultural change and policy change, what’s needed is people who can build better experiences to engage patients in their health–whether it’s eating healthier, exercising, going to the doctor, or taking their medication. No one is better suited to solve these problems than the technologists who have excelled at consumer engagement in tech.
Moreover, healthcare provides the best opportunity out there to use the hottest tools in tech–especially AI–to displace huge incumbents. As we’ve written about recently, deploying AI in traditional tech software businesses presents a number of challenges, namely that AI has lower gross margins than SaaS due to heavy cloud infrastructure usage and ongoing human support. In healthcare, this situation is the opposite. Most of the healthcare industry is services, which have low gross margins. In healthcare, AI stands to dramatically improve the previously unpleasant economics, making building in the industry far more compelling.
Furthermore, human-driven services tend to scale linearly with each incremental human added, but AI-driven services can scale exponentially. And while margins are nice, mission is nicer. When you think about the limited number of days you have on this planet and the insane number of hours you’ll pour into building a startup, wouldn’t it be great if you were working on something that really mattered? You don’t have to be a doctor or cancer researcher to save lives. A company detecting medical errors or helping people afford medical care might save countless lives.
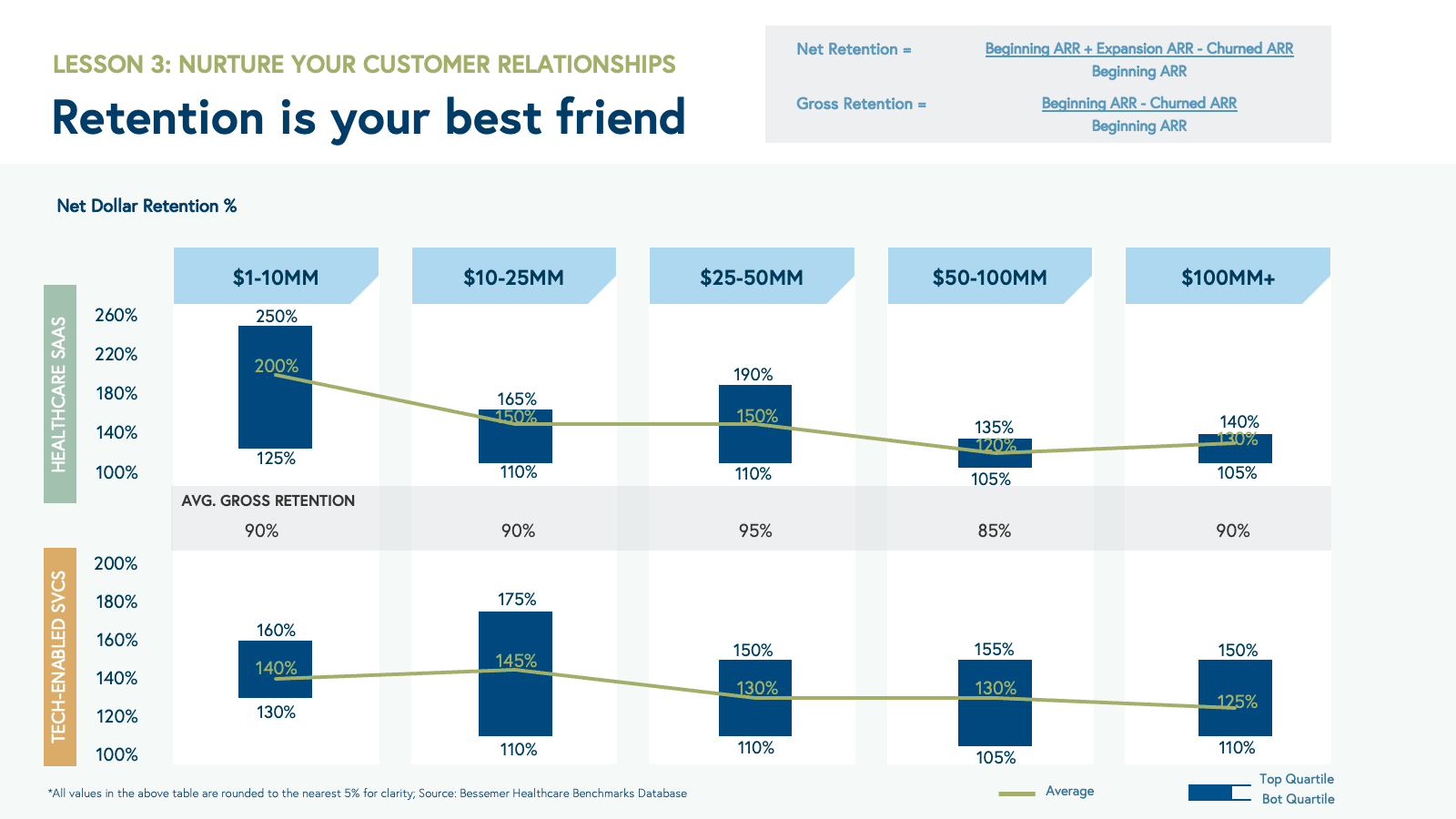
👉 How to scale a health teach business to $100 million ARR and beyond (Bessemer Venture Partners) ❓ Why am I sharing this article? The top-quartile tech-enabled services businesses with over $100 million of ARR have gross margins over 65%, including firms such as Livongo, Teladoc, and BVP portfolio company Headspace Health. This steady progression from 25% gross margins to over 60% is driven by several factors: 1. The ability to command a higher service price over time with strong clinical outcomes and well-defined financial ROI for your customers. 2. Leveraging technology that enables clinicians to provide better care and omnichannel member experiences. 3. Managing more efficient provider panels (i.e., increasing the number of patients per provider over time) with better processes and technology, as well as utilizing different types of providers operating at top of the license (i.e., coaches, nurse practitioners).
Prove your worth: financial and clinical ROI Financial ROI refers to the financial benefit delivered by your solution (e.g., emergency room visits prevented or clinician hours saved but also incremental revenue generated) compared to your customer’s spend on the solution you provide, while clinical ROI can refer to clinical outcomes offered by your solution more broadly. Both of these metrics are calculated from your customer’s perspective and require a clear articulation of why such value should be attributed to your product or service in a short time period (often <12 months).
We encourage portfolio companies to invest early in measuring clinical and financial ROI Clear proof of these metrics requires time and dollars invested, but will pay future dividends. For example, Oshi Health, a Bessemer portfolio company that provides virtual whole-person gastrointestinal care, invested 12 months in running a clinical trial alongside a national health plan to recruit and treat 332 patients suffering from IBS, IBD, and other GI conditions. By carefully designing the trial to measure commonly used GI endpoints, Oshi demonstrated 92% symptom improvement, 98% patient satisfaction, and statistically significant savings of $6.7K per patient from GI-related costs. These well-validated financial and clinical outcomes unlocked better pricing, several state contracts with health plan partners, and drove inbound interest from dozens of other health plans and employers looking to contract with Oshi.
👉 Apple Plans iPhone Journaling App in Expansion of Health Initiatives (The Wall Street Journal) ❓ Why am I sharing this article? The Apple journaling app, code-named Jurassic, is designed to help users keep track of their daily lives, according to the documents describing the software. The app will analyze the users’ behavior to determine what a typical day is like, including how much time is spent at home compared with elsewhere, and whether a certain day included something outside the norm, according to the documents. A personalization feature will highlight potential topics for users to write about, such as a workout, the documents show. The app is expected to offer “All Day People Discovery” to detect a user’s physical proximity to other people, and Apple will seek to distinguish between friends outside work and colleagues.
👉 iOS 17 to Include Mood Tracker and Health App for iPad, AI-Based Health Coaching Service Coming in 2024 (Mac Rumors) ❓ Why am I sharing this article? Apple plans to introduce a new emotion tracker, which will let users keep track of their mood, answer questions about their day, and view the results over time. The mood tracking function that Apple has in mind for the Health app in iOS 17 will be separate from the journaling app that was rumored last week. Next year, Apple will expand its health offerings with a new health coaching service. Codenamed Quartz, the AI-based service will help encourage users to exercise, improve their eating habits, and take steps to improve their sleep. The service will use data from the Apple Watch to make personalized suggestions and create tailored coaching programs, with Apple planning to charge a monthly fee. While the service is planned for 2024, Gurman cautions that it could be "canceled or postponed."
👉 ChatGPT Will See You Now: Doctors Using AI to Answer Patient Questions (The Wall Street Journal) ❓ Why am I sharing this article? A team of five medical professionals graded the AI responses for quality and empathy against those written by doctors on Reddit. Without knowing who wrote which, the evaluators gave “good” or “very good” ratings to four times as many ChatGPT responses as physician posts. Also, only 4.6% of doctors’ posts were graded as “empathetic” or “very empathetic,” compared with 45%—10 times as many—ChatGPT posts.
👉 Thread by Greg Mushen: using chatGPT to lose weight (PingThread) ❓ Why am I sharing this article? I love the prompt about acting as a dual PhD Start with extremely small steps Can we build similar programs very easily? Can you test?
Backstory: I gained 26 lbs during the pandemic. I decided it was time to do something about it. What if I could trick myself into becoming addicted to running? That would be the ultimate hack! I asked ChatGPT to devise a plan to get me addicted to running. After about 8-10 follow-up prompts, I had a solid plan in front of me. However, it looked really strange, and I was really skeptical that it would work. It started with really small steps. The first day was putting my running shoes in a place where I could see them. The next day was another small task. I believe it was putting an appointment in my calendar for the run. The 3rd day was my first run. However, it was only for five minutes, and I don’t think it even took me around the block. The first run was super easy, and I felt like I could do more. I realized that I felt really accomplished for doing that run, even though it around the block. The next day was a rest day. The following day was a six day run. I noticed something around this point. Each run was well within my skill level. I was supposed to go at my all day pace. After each run I started to feel accomplished, and because I hadn’t exceeded my ability, I always felt like I could do more. I really started looking forward to my runs because I knew it wasn’t going to be miserable. It felt like I was checking something off the list. It felt great. I think by about day 30, I ran my first mile. To my surprise, I really enjoyed it. I couldn’t wait to do another run. Meanwhile, I started to lose weight from the added exercise. This made me feel great, and also motivated me to make other changes in my lifestyle using the same principles. I used ChatGPT to help me make changes in my diet. I eliminated sugar and alcohol, and asked ChatGPT to create healthy recipes for me. I also had ChatGPT help me with my sleep hygiene, and the combination of all the changes had me sleeping like a baby.
👉 Foundation models for generalist medical artificial intelligence (Nature) ❓ Why am I sharing this article? The exceptionally rapid development of highly flexible, reusable artificial intelligence (AI) models is likely to usher in newfound capabilities in medicine. We propose a new paradigm for medical AI, which we refer to as generalist medical AI (GMAI). GMAI models will be capable of carrying out a diverse set of tasks using very little or no task-specific labelled data. Built through self-supervision on large, diverse datasets, GMAI will flexibly interpret different combinations of medical modalities, including data from imaging, electronic health records, laboratory results, genomics, graphs or medical text. Models will in turn produce expressive outputs such as free-text explanations, spoken recommendations or image annotations that demonstrate advanced medical reasoning abilities.
GMAI models can address these shortcomings by formally representing medical knowledge. For example, structures such as knowledge graphs can allow models to reason about medical concepts and relationships between them. Furthermore, building on recent retrieval-based approaches, GMAI can retrieve relevant context from existing databases, in the form of articles, images or entire previous cases.
👉 MedGPT – Could we revolutionise healthcare? (Inside My Head) ❓ Why am I sharing this article? Let’s imagine MedGPT trained to be as smart as GPT4, but fine-tuned and purposefully aligned to do medical diagnosis. We can do this, by importing and synthetically creating hundreds of millions of medical cases, and have the model train on that. Second layer, add RLHF (Reinforcement Learning from Human Feedback). The aligners should be doctors with a lot of expertise. This should give us a super aligned model for medical diagnosis purposes.
We can assume the model to be truly multimodal (as GPT4) with the ability to interact using natural language as well as consume images or perhaps even videos as input and then have the ability to properly analyse what it sees. It’s given the patient's entire medical history by default as long term context. On top of that it’s getting the latest real-time information that has been gathered at the point of interaction, either at home in a proactive manner, or at the medical facility in a reactive/proactive scenario. This can include selfassessment, Apple Health data for a specific time period, or your entire recorded Apple Health data. It can include images, video and audio too.
We can imagine the model being either multi-modal (as mentioned above), or having a huggingGPT like router, that can patch in any specific model to complete a goal/task. If it needs to analyse a chest x-ray, it uses a specific model for that. Or if it needs to listen to an audio recording of a heart, it uses another model. The output of the combined efforts of the different models could then be as simple as “Everything is fine. You are healthy, and should not seek medical attention” to something like this: “this patient has a stroke and needs emergency treatment”. For example every year tens of thousands of patients are misdiagnosed for stroke and sepsis.
👉 Weekly Health Tech Reads 4/9 (Health Tech Nerds) ❓ Why am I sharing this article? Stanford’s take on GPT-4 performance: Stanford’s Human Centered Artificial Intelligence (HAI) group explored how safely and accurately GPT-4 could be used to provide curbside consults for providers, 90%+ of the time, the GPT-4 responses to questions were considered “safe” by a group of 12 Stanford providers who reviewed the responses.
👉 OpenAI’s Losses Doubled to $540 Million as It Developed ChatGPT (The Information) ❓ Why am I sharing this article? OpenAI’s losses roughly doubled to around $540 million last year as it developed ChatGPT and hired key employees from Google, according to three people with knowledge of the startup’s financials. Even as revenue has picked up—reaching an annual pace of hundreds of millions of dollars just weeks after OpenAI launched a paid version of the chatbot in February. CEO Sam Altman has privately suggested OpenAI may try to raise as much as $100 billion in the coming years. The startup was on track to spend at least $75 million on Google Cloud in 2020 before transitioning more of its computing to Microsoft’s Azure cloud. OpenAI’s computing requirements have exploded since then, people close to the company have said.
👉 Google “We Have No Moat, And Neither Does OpenAI” (Semi Analysis) ❓ Why am I sharing this article? The uncomfortable truth is, we aren’t positioned to win this arms race and neither is OpenAI. While we’ve been squabbling, a third faction has been quietly eating our lunch. I’m talking, of course, about open source. Plainly put, they are lapping us. Things we consider “major open problems” are solved and in people’s hands today. Just to name a few: While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. This has profound implications for us: We have no secret sauce. Our best hope is to learn from and collaborate with what others are doing outside Google. We should prioritize enabling 3P integrations. People will not pay for a restricted model when free, unrestricted alternatives are comparable in quality. We should consider where our value add really is.
Giant models are slowing us down. In the long run, the best models are the ones which can be iterated upon quickly. We should make small variants more than an afterthought, now that we know what is possible in the <20B parameter regime.
https://lmsys.org/blog/2023-03-30-vicuna/
At the beginning of March the open source community got their hands on their first really capable foundation model, as Meta’s LLaMA was leaked to the public. It had no instruction or conversation tuning, and no RLHF. Nonetheless, the community immediately understood the significance of what they had been given.
A tremendous outpouring of innovation followed, with just days between major developments (see The Timeline for the full breakdown). Here we are, barely a month later, and there are variants with instruction tuning, quantization, quality improvements, human evals, multimodality, RLHF, etc. etc. many of which build on each other.
The barrier to entry for training and experimentation has dropped from the total output of a major research organization to one person, an evening, and a beefy laptop. Large models arenʼt more capable in the long run if we can iterate faster on small models. LoRA updates are very cheap to produce (~$100) for the most popular model sizes. This means that almost anyone with an idea can generate one and distribute it. Training times under a day are the norm. At that pace, it doesn’t take long before the cumulative effect of all of these fine-tunings overcomes starting off at a size disadvantage. Data quality scales better than data size - Many of these projects are saving time by training on small, highly curated datasets. The value of owning the ecosystem cannot be overstated. The more tightly we control our models, the more attractive we make open alternatives. And in the end, OpenAI doesn’t matter. They are making the same mistakes we are in their posture relative to open source, and their ability to maintain an edge is necessarily in question. Open source alternatives can and will eventually eclipse them unless they change their stance. In this respect, at least, we can make the first move. April 3, 2023 - Real Humans Canʼt Tell the Difference Between a 13B Open Model and ChatGPT. Berkeley launches Koala, a dialogue model trained entirely using freely available data. They take the crucial step of measuring real human preferences between their model and ChatGPT. While ChatGPT still holds a slight edge, more than 50% of the time users either prefer Koala or have no preference. Training Cost: $100. April 15, 2023 - Open Source RLHF at ChatGPT Levels. Open Assistant launches a model and, more importantly, a dataset for Alignment via RLHF. Their model is close (48.3% vs. 51.7%) to ChatGPT in terms of human preference. In addition to LLaMA, they show that this dataset can be applied to Pythia-12B, giving people the option to use a fully open stack to run the model. Moreover, because the dataset is publicly available, it takes RLHF from unachievable to cheap and easy for small experimenters.
👉 AutoGPT’s – Everything you need to know (Inside My Head) ❓ Why am I sharing this article?
👉 Can Snap snap back? (Platformer)
👉 Fair Use and Model Training, Getty Images vs. Stable Diffusion, Adobe’s Regulatory Capture Bet (Stratechery) ❓ Why am I sharing this article? It’s not at all clear to me that there is anything illegal about using copyrighted material for model training, as it very well may fall under the fair use exception to copyright. This takes on all four factors: Getty Images is accusing Stability AI of taking its images and captions as is (the purpose and character of use), precisely because it is unique and descriptive (the nature of the copyrighted work), in totality (the amount and substantiality of the portion taken), with the explicit goal of disrupting Getty Images (the effect of the use upon the potential market). I do for the most part side with Stability AI in the case; I do think that using images for model training, which does not entail reproducing a single pixel in terms of the final product, is fair use. Where I do think that Getty Images has a legitimate complaint is in the oddity I mentioned above, in which Stability AI reproduces garbled versions of the Getty Images watermark. That is, per yesterday’s Article, Getty Images’ name, image, and likeness, and Stability AI should have taken care to exclude it from output.
It’s already over! Please share JC’s Newsletter with your friends, and subscribe 👇 Let’s talk about this together on LinkedIn or on Twitter. Have a good week! | |