|
Next Week in Turing Post: |
Wednesday, Token 1.18: Optimizing ML Inference Friday: We start new series about AI Infrastructure Unicorns!
|
Turing Post is a reader-supported publication. To have full access to our most interesting articles and investigations, become a paid subscriber → | |
|
|
It feels like the last year was all about the race of commercial LLMs. Though the LLaMa leakage and further Meta actions on the open-source front were significant, and Hugging Face kept blooming as a platform for open source, this year starts with a powerful player stepping in with a real open-source approach. We speak, of course, about OLMo: Accelerating the Science of Language Model released by the Allen Institute for Artificial Intelligence. Newsletters such as AlphaSignal, TheSequence, Data Machina, Smol Talk, and Interconnects (Nathan Lambert is one of the authors of the OLMo paper) explained pretty well what’s the difference between almost open source and truly open source models.* |
The gist of it is that truly open source means that not only the weights of the model and inference code are released but truly the whole package: the training data, training and evaluation code, and a comprehensive framework for studying language modeling.
|
Who is behind OLMo? |
What I found interesting is who stands behind the release. While EleutherAI’s Pythia and Big Science’s BLOOM previously set a precedent for releasing fully open-source models, the distinction with OLMo is its release by a true nonprofit organization – the Allen Institute for AI (AI2). AI2 was founded in 2014 by philanthropist and Microsoft co-founder Paul G. Allen, with a commitment to conducting high-impact research and engineering in the field of artificial intelligence. He was also very interested in teaching machines “common sense.” |
And he funded this cause well. Once, I had a conversation with one of the top executives of AI2; the person said that, thanks to Paul Allen's structure of financing, AI2 is well-funded, they have no influence from large companies, and no pressure to make money. |
AI2 is famous for not only conducting cutting-edge research in AI but also aiming to influence the broader AI research community by releasing open-source software, datasets, and research findings. Projects like the Semantic Scholar academic search engine democratize access to information and accelerate scientific breakthroughs. |
Why OLMo is special |
The OLMo framework includes multiple training checkpoints, logs, exact datasets used, and a permissive license, establishing a new standard for openness in the field. They also don’t mind this model being used for commercial purposes. Unlike others, the researchers readily embrace openness, believing it outweighs the low misuse risk, as their models, not designed as chatbots, contribute to science rather than commercial products. |
Furthermore, they released 'Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research.' According to Luca Soldani, 'the name of the pretraining corpus, "Dolma," stands for Data to feed OLMo’s Appetite.' |
What also surprised me was that the authors highlight the environmental impact of training large LMs, providing estimates of power consumption and carbon emissions. They advocate for transparency in reporting these impacts and emphasize the potential for open models like OLMo to mitigate future emissions by minimizing redundant model training. |
Great start to the year of open-source! |
|
 | 8 open-source tools for foundation model deployment | Join over 42,000 readers for in-depth knowledge and forward-thinking analysis, to make smarter decisions about AI & ML. Save time. Gain wisdom. Stay ahead. | www.turingpost.com/p/tools-for-model-deployment |
| |
|
|
|
News from The Usual Suspects © |
Hugging Face |
 | Julien Chaumond @julien_c |  |
| |
Ten days ago I posted about GPT Store being a bit sad 😢: What if we could build an open source alternative, with the full power of the Community? So last Friday we launched Hugging Chat Assistants, and the adoption has been impressive:
- 4,000 Assistants have been created on… twitter.com/i/web/status/1… |  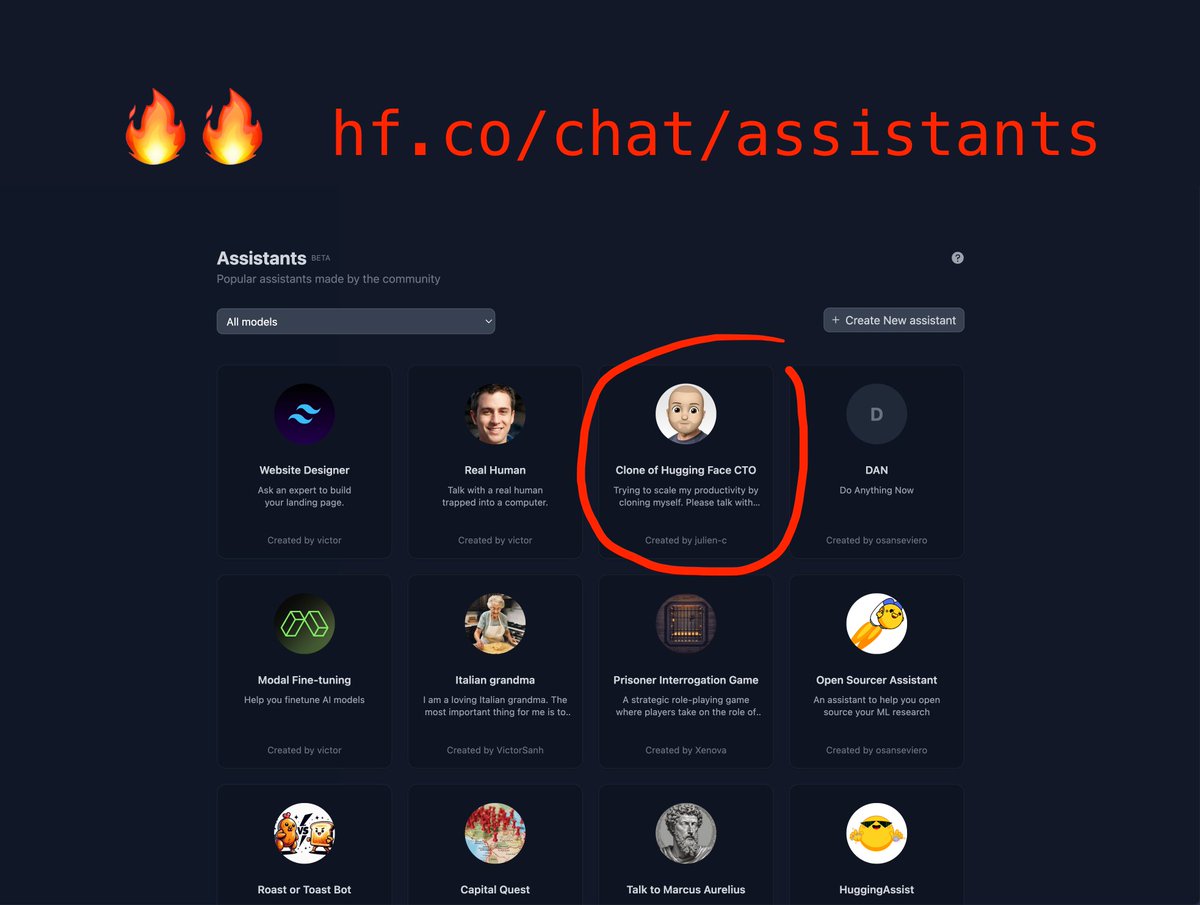  | | | Feb 5, 2024 | | |  | | | 595 Likes 108 Retweets 31 Replies |
|
|
Google |
In their blog post, Google announced MobileDiffusion, a new approach for sub-second text-to-image generation on mobile devices, addressing the efficiency challenges of current large models. This model combines a pre-trained diffusion model with a GAN to enable one-step sampling during inference, resulting in a compact model size of 520M parameters capable of generating high-quality images rapidly on iOS and Android devices. The research includes an in-depth exploration of model architecture, optimizing for mobile deployment while maintaining image quality.
|
Meta |
|
“There are several strategic benefits. First, open source software is typically safer and more secure, as well as more compute efficient to operate due to all the ongoing feedback, scrutiny, and development from the community. This is a big deal because safety is one of the most important issues in AI. Efficiency improvements and lowering the compute costs also benefit everyone including us. Second, open source software often becomes an industry standard, and when companies standardize on building with our stack, that then becomes easier to integrate new innovations into our products. That’s subtle, but the ability to learn and improve quickly is a huge advantage and being an industry standard enables that. Third, open source is hugely popular with developers and researchers. We know that people want to work on open systems that will be widely adopted, so this helps us recruit the best people at Meta, which is a very big deal for leading in any new technology area. And again, we typically have unique data and build unique product integrations anyway, so providing infrastructure like Llama as open source doesn’t reduce our main advantages. This is why our long-standing strategy has been to open source general infrastructure and why I expect it to continue to be the right approach for us going forward.” | | | | Mark Zuckerberg |
|
|
The freshest research papers, categorized for your convenience |
Language Modeling and Efficiency |
Large Language Models for Mathematical Reasoning: Progresses and Challenges: Examines LLMs in mathematical reasoning, highlighting capabilities and challenges. read the paper Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens: Introduces an ∞-gram model for extensive text analysis. read the paper Scavenging Hyena: Distilling Transformers into Long Convolution Models: Proposes a sustainable and efficient LLM pre-training method. read the paper Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling: Presents a strategy for efficient LLM pre-training using rephrased web documents. read the paper
|
Advanced Reasoning and Contextual Understanding |
Efficient Tool Use with Chain-of-Abstraction Reasoning: Enhances multi-step reasoning in LLMs for improved accuracy and efficiency. read the paper RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval: Improves performance on complex reasoning tasks through hierarchical text summarization. read the paper Can Large Language Models Understand Context?: Investigates LLMs' contextual understanding and the impact of compression techniques. read the paper
|
Enhancements in AI Frameworks and Methodologies |
SymbolicAI: A framework for logic-based approaches combining generative models and solvers: Merges generative models with solvers for advanced concept learning. read the paper Efficient Exploration for LLMs: Demonstrates the benefits of efficient exploration in LLM training. read the paper Transforming and Combining Rewards for Aligning Large Language Models: Discusses methods for improving LLM alignment with human preferences. read the paper MoE-LLaVA: Mixture of Experts for Large Vision-Language Models: Introduces a MoE approach for efficient multi-modal learning in LVLMs. read the paper
|
Novel Applications and Security Insights |
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception: Develops an autonomous agent for mobile devices using visual perception. read the paper Transfer Learning for Text Diffusion Models: Explores text diffusion as a competitive method for LLMs. read the paper Weak-to-Strong Jailbreaking on Large Language Models: Identifies a security issue in LLMs and proposes initial defense strategies. read the paper
|
In other newsletters |
A very interesting read about a new trend: VCs backing companies where the majority of revenues come from government contracts by Newcomer The research report gives interesting details about the types of security assessments Chinese AI labs are implementing to comply with generative AI regulations by ChinAI ML Engineer Newsletter celebrates a large milestone towards democratising AI inference with their Vulkan Kompute project that was adopted as one of the backends for the LLama.cpp and GPT4ALL frameworks.
|
We are watching |
 | Apple Vision Pro Review: Tomorrow's Ideas... Today's Tech! |
|
|
And reading this: |
 | Andrej Karpathy @karpathy | |
| |
Early thoughts on the Apple Vision Pro (I ended up buying directly in store last evening). I'm about 3 hours in, between late last night and this morning. The first major thing that must be said is WOW - the visual clarity is way beyond anything that came before. But, a bit… twitter.com/i/web/status/1… | | | Feb 3, 2024 | | | | | | 5.79K Likes 425 Retweets 247 Replies |
|
|
If you decide to become a Premium subscriber, remember, that in most cases, you can expense this subscription through your company! Join our community of forward-thinking professionals. Please also send this newsletter to your colleagues if it can help them enhance their understanding of AI and stay ahead of the curve. 🤍 Thank you for reading |
|
|
|
How was today's FOD?Please give us some constructive feedback |
|
|
|


