⚡️ Changes on Turing Post ⚡️ | Good times, dear readers. It’s September, and we’re approaching some exciting months filled with ML and AI developments. We hope you had a restful summer because we’re ready to offer more insights into machine learning – not just the AGI conversation, but the technology behind it. At Turing Post, we aim to support your learning by blending history, key terms, and storytelling, hoping to inspire new, practical ideas. | To understand AGI, it’s essential to grasp the foundational technology behind it. Our AI 101 series on Wednesdays is designed with this in mind, providing clarity amidst the often inconsistent use of terminology. We’ll focus on three main areas: | | While there may be overlaps between these categories, models and methods will be explained in detail, and fundamental concepts will be presented in concise, easy-to-understand formats. | Fridays will be divided between two series: | | Agentic Workflows is an enormous topic with a lot happening right now. We will guide you through it, learning together along the way. | Hope you’ll find it useful (your feedback and sharing are the most valuable support. Please don’t hesitate to do it 🙏) | This week on Turing Post | Tuesday, Guest Post: Optimizing Multi-agent Systems with Mistral Large, Mistral Nemo, and Llama-agents (practical!) Wednesday, AI 101<>Method/Technique: What is Chain-of-Knowledge (for those interested in enhancing the reasoning capabilities of LLMs) Friday, AI Unicorn: a fascinating story of 01.AI and her leader, a legendary Kai-Fu Lee.
| Turing Post is a reader-supported publication, please consider becoming a paid subscriber. You get full access to all our articles, investigations, and tech series immediately → | |
|
| | Editorial | Have you heard of Jevons' Paradox? It's a paradox discovered by British economist William Stanley Jevons (1835-1882) during the Industrial Revolution in 1865. After James Watt introduced an efficient steam engine that required much less coal than previous methods, people assumed that Watt's engine would eventually reduce the total amount of coal consumed. But the exact opposite happened! Coal consumption in the UK skyrocketed. This is the phenomenon of how increasing the efficiency of a resource as technology continues to advance does not lead to less use of that resource, but rather more. | In the generative AI space, the token cost of using LLMs is rapidly decreasing, especially as LLM technology development accelerates and open-source LLMs proliferate. Professor Andrew Ng wrote a piece a few days ago about the rapid decline in token costs, why it's happening, and what AI companies should be thinking about going forward. Here's a quick summary of his thoughts: | The LLM token price has been declining at a significant rate of almost 80% per year.
From $36 per million tokens at the launch of GPT-4 in March 2023, the price of GPT-4o tokens has recently been reduced by OpenAI to $4 per million, and the new Batch API is available for an even lower price of $2 per million. The sharp drop in token price is attributed to the launch of the open-weight model and innovations in hardware.
There are many reasons for this, but with the release of great open-weight models like Meta's Llama 3.1, we're seeing a steady stream of mature, usable LLMs of all sizes, allowing startups like Anyscale, Fireworks, Together.ai, and large cloud service providers to compete directly on factors like price and speed without the burden of having to recoup ‘model development costs’.
And the ongoing hardware innovation from startups like Groq, Samba Nova (which delivers Llama 3.1 405B tokens at 114 per second), Cerebras, and the likes of Nvidia, AMD, and others will further accelerate price reductions going forward. Recommendations for AI Companies Developing LLM Applications:
Given the projected decline in token prices, focus on creating valuable applications rather than solely optimizing costs. Even if current costs seem high, pursue aggressive development and deployment with an eye on future price drops. Regularly review and switch to different models or providers as new options become available.
| Paradigms of generative AI development
I also believe that the sharp decline in token prices will definitely contribute to more experimentation, development, and deployment of LLM and generative AI applications. The real winners will be operators with multi-LLM architectures who can rapidly deploy new applications that leverage AI's generative capabilities. | While cost is a factor, the key lies in balancing 'Utility vs. Cost,' a challenging task in generative AI. Best practices for killer applications are still emerging, and risks like 'illusion,' 'bias,' and 'privacy leakage' must be managed. These risks can impact AI companies and society if not handled welll. | I believe that the companies that will be leaders in the ‘generative AI’ market will be those that take advantage of the ‘falling cost’ of LLM technology and create and operate applications that maximize the features and benefits of this technology quickly and with good risk management. I call this the “risk-based generative AI paradigm”. | What perspectives do you think are needed in the generative AI market, including LLMs, to allow for more experimentation, development, and deployment, like Jevons' paradox? | | It’s Labor Day in the US, and I, Ksenia, am navigating a family invasion. Today's editorial is brought to you by Ben Sum, our dedicated Korean partner at Turing Post. Thanks to him, Turing Post Korea thrives (subscribe here), and he'll be contributing more insightful opinion pieces to the main Turing Post as well. | | |
 | 10 Newest Ways for Efficient Processing of Long Context in LLMs | Handling long context remains a challenging issue for LLMs and other AI system | www.turingpost.com/p/10-ways-to-process-long-context |
| |
|
| Weekly recommendation from AI practitioner👍🏼: | Check OpenRouter and Not Diamond. They allow manage access to different AI models. OpenRouter simplifies using various large language models through a single API, while Not Diamond helps connect and route between multiple AI models, supporting a more interconnected AI environment.
| | News from The Usual Suspects © | | | | | We are watching/reading | | | The freshest research papers, categorized for your convenience | Our top |  | Ksenia Se @Kseniase_ |  |
| |
Can a neural model run a complex game with real-time simulation? Researchers from @GoogleDeepMind, @Google Research and Tel Aviv University answer yes! They created GameNGen, the first game engine powered by a diffusion model and using a game-playing agent. Worth exploring👇 | | 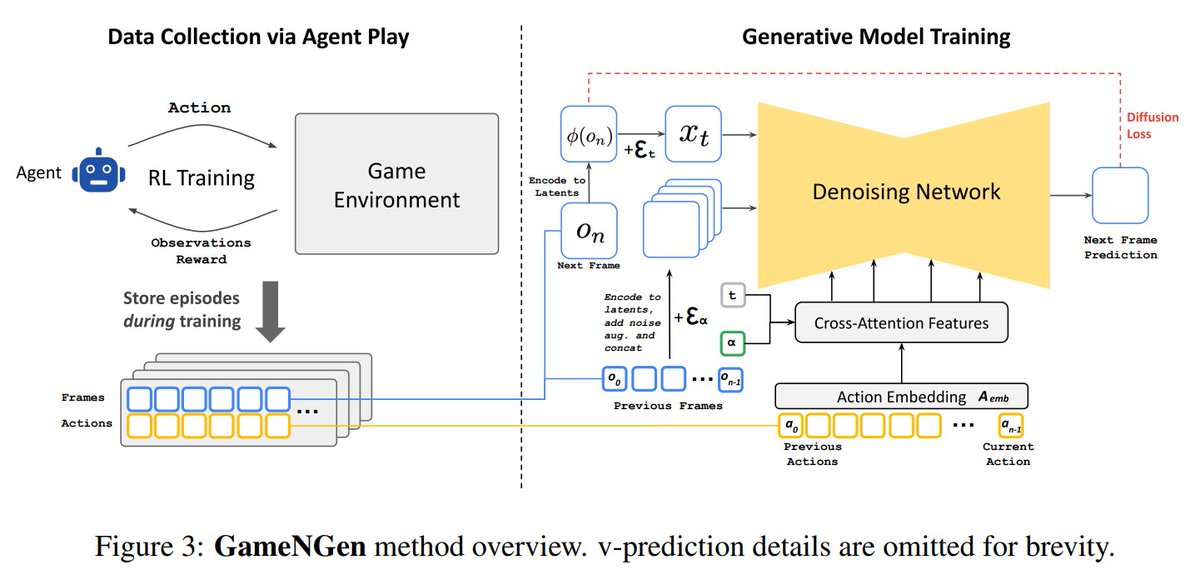  | | | 5:00 PM • Sep 1, 2024 | | | | | | 6 Likes 0 Retweets | 1 Reply |
|
| GameNGen can simulate the game DOOM at over 20 FPS on a single TPU. It achieves next-frame prediction with a PSNR of 29.4, akin to lossy JPEG compression. Human raters struggled to distinguish between real and simulated short game clips, highlighting the model's high visual fidelity and interaction quality. GameNGen is a big deal because it shows how AI could take over game creation, making endless, interactive worlds that are generated on the fly. Imagine games that build themselves! →read the paper Foundation Models for Music: A Survey Just a great review of foundation models (FMs) for music, covering areas like representation learning, generative learning, and multimodal learning. The study highlights the underexplored potential of FMs in diverse music applications, emphasizing instruction tuning, long-sequence modeling, and self-supervised learning (SSL). FMs can improve music understanding and generation while addressing dataset limitations →read the paper A Web-Based Solution for Federated Learning with LLM-Based Automation Researchers from the University of Oulu propose a web-based solution to simplify Federated Learning (FL) by integrating LLM-based automation. This platform supports the Federated Averaging (FedAvg) algorithm, model compression, and scheduling, enhancing FL performance. A fine-tuned LLM allows FL tasks via high-level prompts, achieving similar accuracy to traditional methods but with 64% fewer transferred bytes and 46% less CPU time. Additionally, Neural Architecture Search (NAS) and Hyperparameter Optimization (HPO) using LLMs improve test accuracy by 10-20% →read the paper
| Large Language Models and Optimization Techniques | NanoFlow: Optimizes the inference process of large language models by improving throughput through nano-batching and efficient resource co-scheduling within GPUs. Read the paper. Smaller, Weaker, Yet Better: Investigates using cheaper, weaker models to generate synthetic training data for stronger language models, optimizing compute usage for training. Read the paper. LlamaDuo: Introduces a pipeline for migrating from large, cloud-based language models to smaller, local models while maintaining performance through iterative tuning with synthetic data. Read the paper. Efficient LLM Scheduling by Learning to Rank: Proposes a scheduling method to enhance LLM latency and throughput by predicting and optimizing task output length. Read the paper. MobileQuant: Offers a quantization technique for efficient on-device deployment of language models, optimizing for mobile hardware. Read the paper.
| Multimodal Models and Vision-Language Integration | Generative Inbetweening: Adapts image-to-video models to interpolate keyframes, producing smooth, coherent motion in videos. Read the paper. EAGLE: Explores multimodal LLMs using a mixture of vision encoders to enhance visual perception and reduce hallucinations. Read the paper. CogVLM2: Introduces models that integrate image and video understanding, achieving state-of-the-art results in visual-language tasks. Read the paper. Building and Better Understanding Vision-Language Models: Provides insights into the development and optimization of vision-language models, introducing the Idefics3-8B model. Read the paper.
| Knowledge Integration and Task-Specific Enhancements | Leveraging Open Knowledge: Enhances task-specific expertise in LLMs by integrating diverse open-source models and datasets. Read the paper. Text2SQL is Not Enough: Proposes Table-Augmented Generation (TAG) for handling complex natural language queries over databases, integrating language models with traditional database systems. Read the paper. Knowledge Navigator: Develops a framework for exploring scientific literature using LLMs to organize topics hierarchically, improving search and discovery. Read the paper.
| Efficient Model Training and Knowledge Distillation | LLAVA-MOD: Introduces a knowledge distillation framework for training small-scale multimodal language models efficiently using a sparse Mixture of Experts architecture. Read the paper. The Mamba in the Llama: Explores converting large transformer models into efficient hybrid models using distillation techniques, enhancing performance while reducing computational complexity. Read the paper.
| Novel Computational Approaches and Theoretical Insights | Dolphin: Treats long contextual information as a modality, improving energy efficiency and latency in on-device language models. Read the paper. Meta Flow Matching: Introduces a method for learning dynamics in interacting systems using vector fields on the Wasserstein manifold, with applications in personalized medicine. Read the paper. Physics of Language Models: Explores training language models on error-correction data to improve reasoning accuracy and error correction during generation. Read the paper.
| Theoretical Frameworks and Vision Representation | Law of Vision Representation in MLLMs: Introduces a method to quantify cross-modal alignment in multimodal language models, predicting model performance and optimizing visual representations. Read the paper. Auxiliary-Loss-Free Load Balancing: Presents a strategy for balancing expert load in Mixture-of-Experts models without auxiliary loss, enhancing performance and preventing routing collapse. Read the paper.
| | Leave a review! | | Please send this newsletter to your colleagues if it can help them enhance their understanding of AI and stay ahead of the curve. You will get a 1-month subscription! |
|
| |
|



