This is a tale of two open source data 🦄 - Cloudera and Confluent, both classic Silicon Valley open source infrastructure success stories born out of web scale needs at the biggest Internet companies. Cloudera, founded in 2008 by 3 engineers from Google, Yahoo, and Facebook, was one of the fastest growing and early open source data success stories as Yahoo was one of the first companies to use Hadoop for data analysis along with Facebook. It's first round was aised in 2009, hit $116M subscription revenue by 2016, went public, but eventually struggled as Apache Spark and Databricks grew over time. This past week Cloudera was taken private at $5.3B (more from CNBC). While a huge initial success, Cloudera was not able to sustain its momentum.
Cloudera has struggled as a public company since holding its IPO in 2017. The company, along with Hortonworks, came to the market as a leader commercializing the open-source analytics technology called Hadoop. Cloudera and Hortonworks merged at the beginning of 2019 in what ended up as a $3 billion deal, well below where the companies had been valued years earlier.
Competition has ramped up in the cloud database and analytics market, both from infrastructure vendors like Amazon, Microsoft and Google and from emerging companies like Snowflake and Databricks.
Switching gears, Confluent just filed its S-1 and is another example of amazing OSS cos being born out of web scale pain, in this case Linkedin.
While there are other places to go for a full S-1 breakdown, I always love reading S-1s more for the story and how the bankers and companies take infrastructure software and simplify it for Wall Street into digestable soundbites. So here are some random thoughts:
Confluent S-1: open source mentioned 88x, developer 68x, cloud 391x, Gartner 25x, and on premise with 12x
Cloudera S-1 (March 2017): open source mentioned 195x, developer 13x, cloud 268x, on premise 0x
Even though the bulk of revenue for Confluent is not ☁️ yet, it’s clear that is part of the the IPO story.
Mission:
Set Data in Motion
Full Story:
We have pioneered a new category of data infrastructure designed to connect all the applications, systems, and data layers of a company around a real-time central nervous system. This new data infrastructure software has emerged as one of the most strategic parts of the next-generation technology stack, and using this stack to harness data in motion is critical to the success of modern companies as they strive to compete and win in the digital-first world.
Also paints picture of why real time
The operation of the business needs to happen in real-time and cut across infrastructure silos. Organizations can no longer have disconnected applications around the edges of their business with piles of data stored and siloed in separate databases. These sources of data need to integrate in real-time in order to be relevant, and applications need to be able to react continuously to everything happening in the business as it occurs.
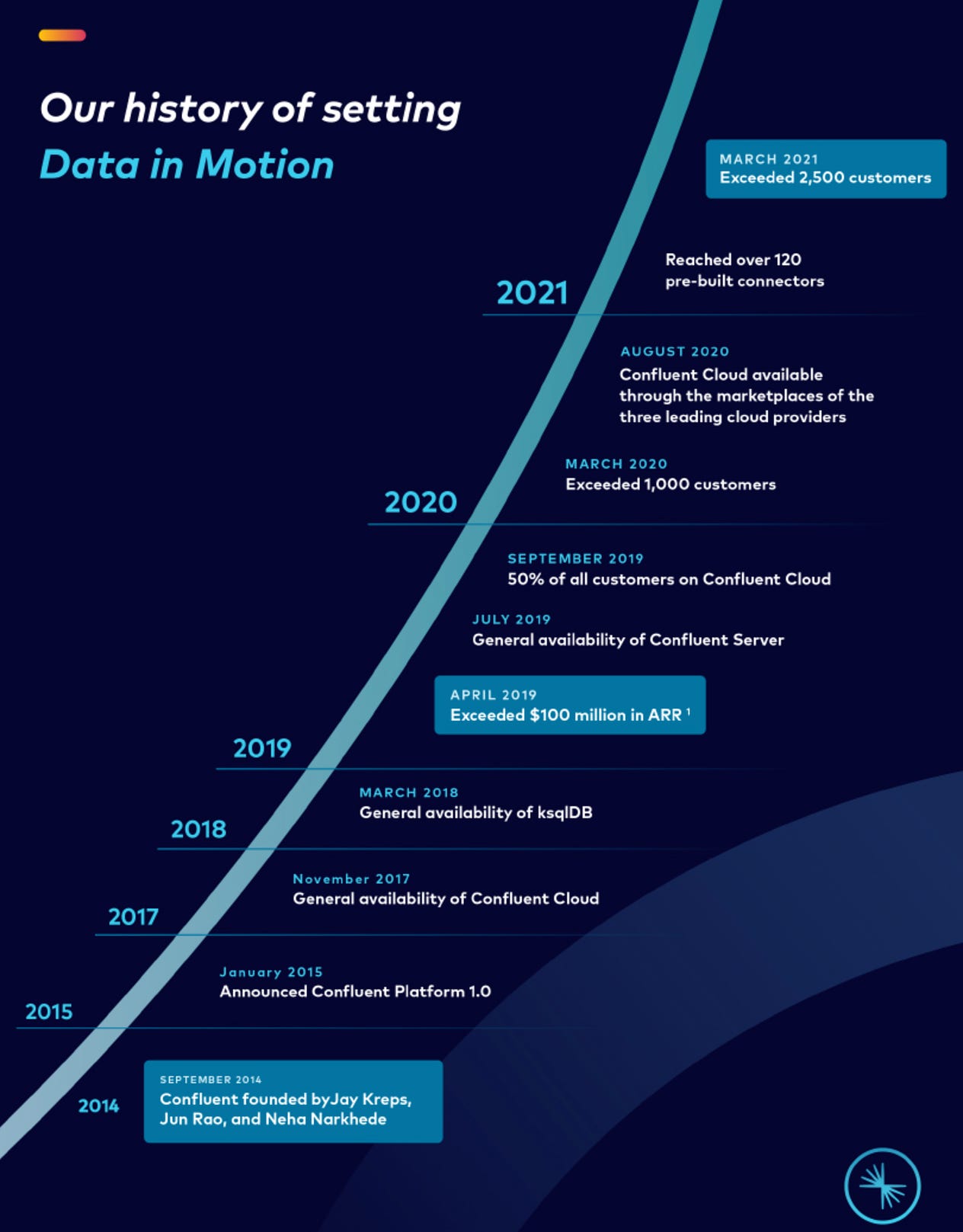
Amazing run from 2014 to 2021, about 5 years to get to $100M in ARR 😲
But notice in the highlights, $ based net retention not mentioned because frankly it is going down albeit on a higher base:
This expansion effect is reflected by our dollar-based net retention rate as of December 31, 2019 and 2020 and March 31, 2021 of 134%, 125%, and 117%, respectively.
Cloud offering is key piece of this story along with open source roots:
Our offering can be deployed either as a fully-managed, cloud-native SaaS offering available on all major cloud providers or an enterprise-ready, self-managed software offering. Our cloud-native offering works across multi-cloud and hybrid infrastructures, delivering massive scalability, elasticity, security, and global interconnectedness, enabling agile development.
Our open source roots are a key driver of our go-to-market success. Apache Kafka has become the industry standard for data in motion. It is one of the most successful open source projects, estimated to have been used by over 70% of the Fortune 500. Modern applications are expected to integrate with Apache Kafka, and the technical skill set for Kafka has become a critical requirement in the industry. Confluent’s products provide the capabilities of Apache Kafka but do so on a platform built for the cloud, complemented by connectivity to the larger enterprise, and with the ability to process and govern at scale. The developer community understands the benefits of a complete platform for data in motion. Consequently, software developers within our prospective customers’ engineering or IT departments are often very familiar with our underlying technology and value proposition and evangelize on our behalf.
From a revenue perspective, growth is still solid but slowing down so therefore the prospectus breaks down into different categories to show outperformance
Our revenue was $149.8 million and $236.6 million in 2019 and 2020, respectively, representing year-over-year growth of 58%, and $50.9 million and $77.0 million for the three months ended March 31, 2020 and 2021, respectively, representing year-over-year growth of 51%.
The ☁️ is the future and but the numbers are still so small as a relative percentage of the overall numbers. However, this could be a Mongo Atlas story where the cloud overtook the on premise version in a matter of years.
Increasing Adoption of Confluent Cloud
We believe our cloud-native Confluent Cloud offering represents an important growth opportunity for our business. Organizations are increasingly looking for a fully-managed offering to seamlessly leverage data in motion across a variety of environments. In some cases, customers that have been self-managing deployments through Confluent Platform subsequently have become Confluent Cloud customers. We offer customers a free cloud trial and a pay-as-you-go arrangement to encourage adoption and usage over time. We will continue to leverage our cloud-native differentiation to drive our growth. We expect Confluent Cloud’s contribution to our subscription revenue to increase over time. Our Confluent Cloud revenue grew 454% from $2.6 million in 2018 to $14.4 million in 2019, 117% from $14.4 million in 2019 to $31.4 million in 2020, and 124% from $6.2 million during the three months ended March 31, 2020 to $13.9 million during the three months ended March 31, 2021.
In risk factors, Confluent further highlights dependence on the enterprise ready, self managed software offering.
Our business is substantially dependent on Confluent Platform, our enterprise-ready, self-managed software offering. Confluent Platform contributed 89% and 85% of our subscription revenue for the years ended December 31, 2019 and 2020, respectively, and 86% and 80% of our subscription revenue for the three months ended March 31, 2020 and 2021, respectively. We expect to continue to rely on customer adoption and expansion of Confluent Platform as a component of our future growth.
The developer first gotomarket along with the moat of community and open source is super important:
End-to-End Approach to Go-To-Market Built for the Unique Customer Journey of Data in Motion.
Data in motion has a unique customer adoption and expansion journey within organizations and our go-to-market mirrors this distinct journey. The widespread adoption of Apache Kafka by developers, and the self-service adoption possible with our cloud product and community downloads, ensure that awareness, mindshare, and adoption begin as new applications are conceived, often long before our sales efforts begin. Our enterprise sales force takes these many initial engagements and helps them progress to production use cases and paying customers with a committed contract. We then drive expansion across the company and help the platform transition from serving individual disconnected projects to being used as a cross-enterprise platform. We believe our expertise is vital to companies who wish to successfully navigate this transition as they reorient their business for data in motion.
Our approach to supporting this end-to-end customer journey is a significant competitive moat for us. Legacy technology vendors cannot easily rebuild their go-to-market to support high volume, low-friction open source and SaaS lands. Startup companies cannot muster the full spectrum of go-to-market tactics and resources needed to support this journey or the heavy investment in customer success required to take customers to scale. Even though large cloud providers have broad go-to-market capabilities, these capabilities are generally focused on the broader transition to the cloud addressing hundreds of products and services. We believe they take a broad but shallow approach that is not built to focus and support the specifics of the data-in-motion customer adoption journey and cannot easily be repurposed without a larger remaking of their go-to-market strategy.
Amazing that this all happened this past week as it shows that sometimes early success does not mean enduring success and that open source is here to stay! Now let’s keep an eye out for Databricks which is supposedly filing soon.
As always, 🙏🏼 for reading and please share with your friends and colleagues.
P.S. We’re hiring an Associate at boldstart ventures!
Scaling Startups
Creating new categories is not for the faint of heart - read 🧵
Anatomy of a pivot - great 🧵
PLG and time to value often go hand in hand but Jon Lai talks about ‘time to fun’- so many great ideas borrowed from video games
like Rahul from Superhuman (a port co) discussing how game design can be weaved into enterprise software (must see YouTube)
High conviction first matters.
Summer slowdown? No signs post Memorial Day
Enterprise Tech
Sales intelligence and engagement space on 🔥 as Gong raised another $250M at over $7B valuation (tripling its valuation) from Franklin Templeton and insiders like Sequoia and Tiger and Outreach raised $200M at a $4.4B valuation from Premji, Steadfast and Tiger and Sequoia
Outreach - Close Deals Faster
Gong - Grow Your Revenue
Consolidation coming!
👇🏼 great rundown of Cloud IDEs from Sid at Gitlab, nice mention of Tilt.dev (a port co)
The Evolution of Chaos Engineering by Benjamin Wilms (Steadybit) TL;DR
Chaos Engineering is just the beginning and the evolution towards Resilience Engineering has just begun.
Balance between reliability and engineering velocity
Together, we must be able to learn from mistakes more easily and continuously. Mistakes are part of life. To blindly and untruthfully improve everything now and make even the last small service highly available is not the right decision and leads to even more unnecessary complexity. We need a guide through our complex systems that helps us better assess risk. An overview of the current resilience, vulnerabilities and what impact they can have is necessary to set the right priority. Today the impact of failures can be mitigated and we as developers, SRE and Ops can all learn to get consistently better at this
Developers, developers, developers (more from Stack blog) as it is acquired for $1.8B by Prosus
Our intention is for our public platform to be an invaluable resource for developers and technologists everywhere and for our SaaS collaboration and knowledge management platform, Stack Overflow for Teams, to reach thousands more global enterprises, allowing them to accelerate product innovation and increase productivity by unlocking institutional knowledge.
🤯 Celonis, process mining software, now valued at $11B - amazing that in the early days it was one of the few startups to be on SAP’s price list, the SOLEX program, and much of the early ARR was SAP dependent but the company has done an amazing job over time diversifying that base and growing - great story by Alex Konrad (Forbes)
Founded in 2011 as a way to bring more data-driven rigor to the consulting work that Rinke and his co-founders were taking up, Celonis got its start when its founders looked to incorporate a then somewhat obscure method of scanning IT log data to map out a company’s processes, called process mining, into their student consulting work.
Shunned by venture capitalists for its first five years due in part to the somnific powers of the phrase “process mining,” Celonis built up a clientele of other European heavyweights before raising a Series A of $27.5 million in 2016…
👇🏼💯 good reminder for new dev first companies
This is always a huge milestone for any company whether you are bottoms up or top down. As the enterprise dollars get bigger, appearance on the Gartner Magic Quadrant matters. Also if you see above, Gartner, along with IDC, is one of the key firms used to quantify market sizes for IPO prospectuses. So this can be a whole post unto itself (see a 2010 blog post from yours truly) but suffice to say, talking to analysts when creating a new market is a waste of time in early days. But once you get a dozen customers then you can start prepping them for your way of thinking and make them feel like it is their own. You then need to figure out if a “new category” or part of an existing one but regardless, startups are expected to be a Visionary on the far right and only over time do you rise to top right with revenue scale. Anyway, huge congrats to Snyk (a portfolio co) as they are a Visionary and also scored highest where it wanted it to in 3 critical capabilities: developer enablement, software composition analysis (SCA), + container security.
Empowering devs!
Markets
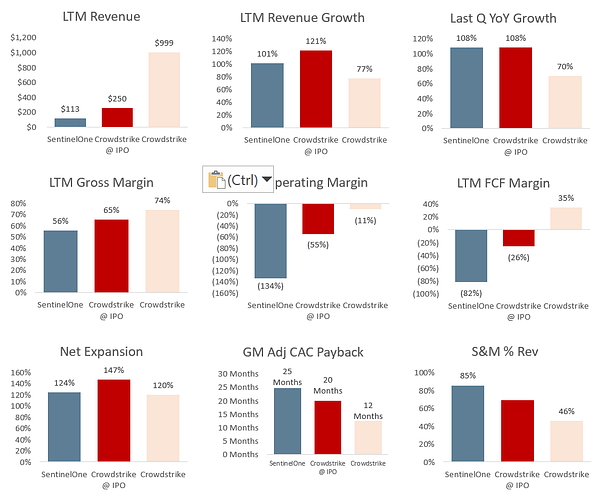
Security on🔥 - Sentinel One filed its S-1 - reminds me of the Crowdstrike platform approach to show massive TAM (see newsletter from April)
We pioneered the world’s first purpose-built AI-powered extended detection and response, or XDR, platform to make cybersecurity defense truly autonomous, from the endpoint and beyond. Our Singularity Platform instantly defends against cyberattacks - performing at a faster speed, greater scale, and higher accuracy than possible from any single human or even a crowd.
Key stats - $161M ARR (run rate at end of Q1), 116% YoY Growth, 124% Net $ Retention, 4700 customers. Recognized revenue for 2021 was $96M and gross margin only 51%
And Jamin Ball shows the Crowdstrike comparison: