Top of the lyne - Generative AI: Why now?
Hey there on a Saturday! 👋🏻 In working with a bunch of Generative AI companies at Toplyne, we’ve started to see some patterns emerge. (How do you like that, transformers?) Thanks for reading Top of the Lyne! Subscribe for free to receive new posts and support my work. Gold rushes of this scale come around once in a generation. And therefore, while most of them are product-led, their GTM challenges - in differentiation, retention, moats for growth - are all brand new, fully unique, and vastly unexplored. This is a three-part series on the Generative AI landscape, and we’re coming to you first with a taste of how we’ve found ourselves in this beautiful madness. In the immortal words of Ne-Yo, let’s go.
In Alphabet’s earnings call yesterday, Google CEO Sundar Pichai announced their planned roll-out of LaMDA (Language Model for Dialogue Applications) within the "coming weeks and months.” LaMDA. Where have we heard that name before?
LaMDA is Google’s chosen fighter against ChatGPT. Back in June 2022, Blake Lemoine, a Google engineer working on its development released the contents of his interview with Google’s own language model - covering ground ranging from the themes in Les Miserables to Kantian ethics, religion, and spirituality. He was convinced that LaMDA was sentient.
Can you blame him? The interview caused some stir and dominated the front page of reddit for a few days, but what many of us failed to notice at the time was that this was a canary in the coal-mine for the biggest tectonic tech shift of our generation. While tech had conquered the frontiers of systems of record, analysis, and prediction - there was one world left completely untouched, standing between it and ubiquity: creation.
A modern renaissance that promises to push the envelope and test the limits of human creativity beckons us from not so far. And in damning evidence that perhaps as a race, it was time we sought out help on this whole creativity thing, we decided to call it: Generative Artificial Intelligence. Gen-AI. Yuck. Why now?From Alan Turing breaking the Enigma code to Deep Blue kicking Garry Kasparov’s ass in the late 90’s, Google’s Deep Mind beating Lee Sedol at Go and perhaps most importantly, influencers dropping the “I see a little silhouetto of a man” prompt on an unsuspecting Siri - AI has been around for decades. But until now, the trifecta of machine learning - models, data, compute - has always been in dissonance. History will remember this last decade as the decade when, for the first time in history, we finally have models that are efficient, compute that’s powerful enough to run them, and data that’s large enough for them to learn from. For the first time in history, we have resonance.
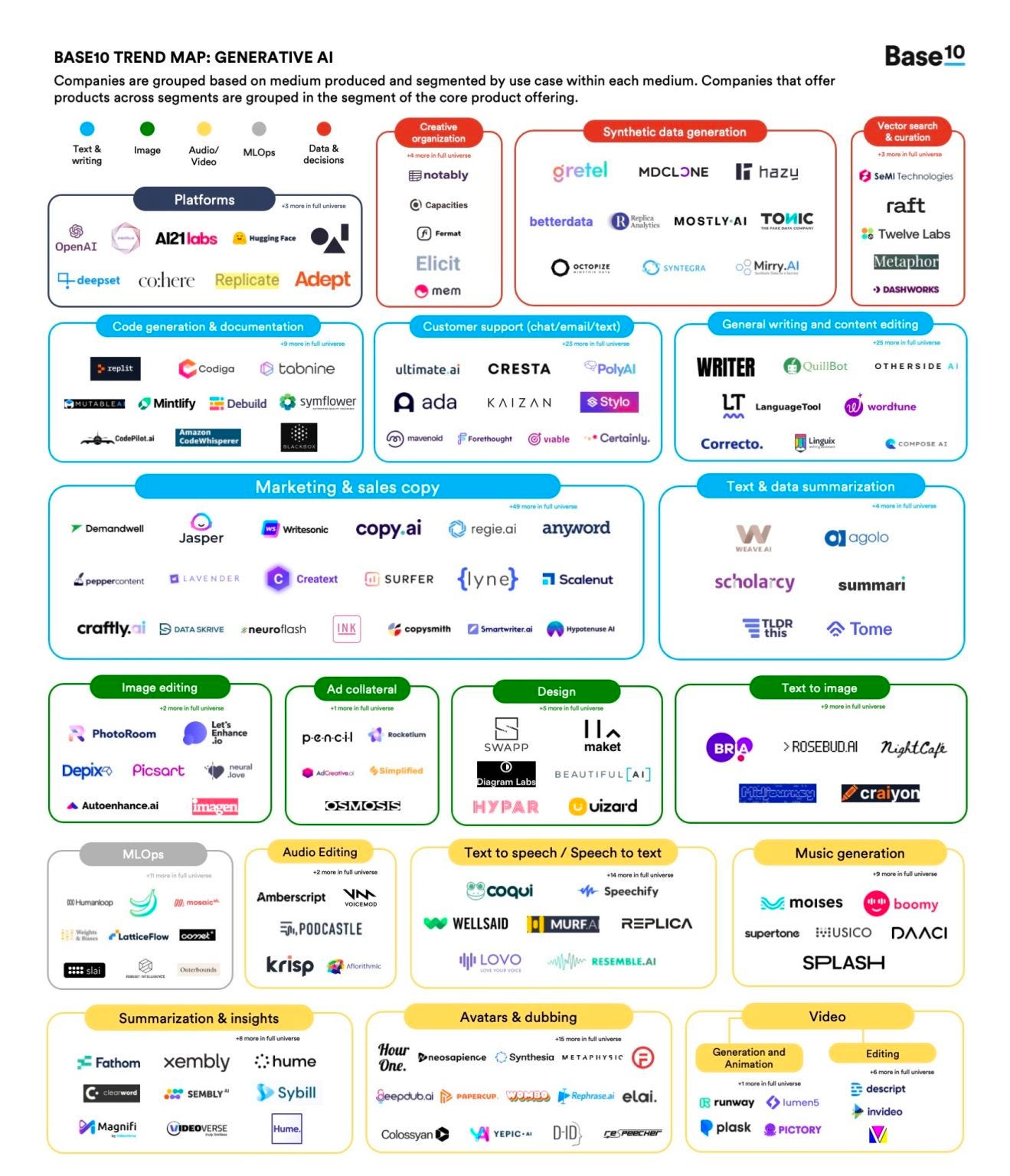
We’re now at the precipice of AI touching a whole previously untouched world of creative work, with the potential to unlock trillions of dollars of economic value. How did this gold rush come about? This resonance was no fluke. Behind all of the unsolicited ChatGPT screenshots spamming your social media feeds are a sequence of frequently spaced out inflection points that have all led to this point of resonance. This is an ode to those inflection points. Let’s roll the tape. Chihuahuas and muffins 🐶Until the early 2010s, we had neither the data nor the compute power to run the only thing that AI had going: Convolutional Neural Networks (CNNs). Two things changed that.
With the data and compute boxes now checked, CNNs suddenly became practical. And so in 2012, AlexNet brought the trifecta together to create the most powerful image classifier known to man at the time. It could *checks notes* tell chihuahuas from muffins.
That doesn’t sound like much, but what wasn’t obvious at the time was that the ability to tell chihuahuas from muffins was indicative of a much broader theme in applied machine learning. The dog/baked good dichotomy also meant that we had now solved voice recognition, entiment analysis - and in turn, fraud detection, and a whole class of new problem statements. This was 2013. Natural language processing (NLP) was still weak. The world was waiting on a new model that could take advantage of the leap in compute and the vast swathes of data that was widely available on the interwebs. Turns out, all we needed was attention. Are you paying attention? 🧐Thanks to Nvidia, we had compute, and thanks to the internet, we had the data. And now we needed a new model. Enter Google Brain. In a 2017 paper titled “Attention is all you need”, researchers at Google Brain introduced the “transformer” model - the greatest thing to happen to Natural Language Processing/Understanding (NLP/U) since sliced bread.
Transformers were groundbreaking in three specific ways.
The fill-in-the-blanks approach to learning meant that transformers could be unleashed on the internet to train on its own, and post graduation, it would be capable of generating net new fills for the blanks. This is the point when “generative” begins to become the operative word. And so in the late 2010s, OpenAI sat down and decided to go HAM on this. In 2019, they released the GPT-2 - the Generative Pre-Trained Transformer-2. Immediately followed by something 100x bigger: GPT-3. With GPT-3, OpenAI had also unlocked a new skill: Without retraining the model, GPT-3 could be prompted to expose itself to subsets of its training data to alter its output. Or to put it simply, it could now write your thesis on the “Role of Gala in Dali’s Life and Work.” in the style of Ron Swanson.
Companies like Copy.ai, Jasper, Writesonic, and many others began to emerge from OpenAI granting beta access to GPT3. There were signs of life in text. But a Cambrian explosion was just around the corner. Transformers transform 🦾Around 540 million years ago, the Cambrian explosion or the “Biological Big Bang” resulted in the vast divergence of single-celled mostly aquatic organisms into the vast diversity of biospheres occupied by life today. A couple of years ago, transformer models looked at the Cambrian explosion and said “I could do that.”
Because they were originally built for translation, transformers were highly proficient at moving between languages. They were agnostic to “language.” Theoretically, images, code, and even DNA sequences could be scaled down to be represented on a similar dimension as text, and the general purpose nature of transformers could allow interoperability with well new modals of content. Like images, code, and DNA sequences. Deep learning breakthroughs bringing “latent space” representations of higher/different fidelity content to lower dimensions made them compatible with transformers and powered a new Cambrian explosion. One that brought us DALL-E, Co-pilot, and AlphaFold. Images, code, and DNA/protein sequences. The state of creativity 👨🏻🎨And that brings us to today, when the trifecta of compute, models, and data are in near-perfect harmony. Compute is now cheaper than ever. The biggest winner of this gold rush as with all gold rushes are the ones who sell the shovels. Nvidia reported $3.8 billion of data center GPU revenue Q3 of fiscal year 2023, with a meaningful portion attributed to generative AI use cases. The models are getting better. Brand new models like diffusion models are cheaper and more efficient. Developer access went from closed-beta to open-beta to open-source. + There’s no shortage of training data. Front-end applications are beginning to evolve like metazoan phyla began to appear on land (and fossil records) during the original Cambrian explosion.
What next? 🔮In this interview with Reid Hoffman, Sam Altman makes three high-certainty predictions of where this “Big Bang” is headed next:
Through the rest of this series on Generative AI, we cover the highs, lows, and caveats of building a company in a gold-rush: GTM, distribution, growth moats, differentiation, sales, and why we think lessons from other product-led growth gold-rushes - the so called “old rules” still apply. More on that through the rest of the series. A lot would have changed by then. That’s just the nature of Cambrian explosions.
Until then, a gentle reminder to not hurt or disrespect our AI overlords. And whatever you do, do not google ‘Roko’s basilisk.’
Thanks for reading Top of the Lyne! Subscribe for free to receive new posts and support my work.
Read Top of the Lyne in the app Listen to posts, join subscriber chats, and never miss an update from Rahul Krishnan, Ruchin Kulkarni, and Poojit Rohra.
|










Older messages
It's time to send in the cavalry
Tuesday, January 24, 2023
Part 3/3 of the Expansion Manifesto
The key ingredients of organic expansion
Thursday, January 5, 2023
Part 2 of the Expansion Manifesto: How the most viral products expand within accounts
2022 Wrapped in Memes
Tuesday, December 27, 2022
The dankest moments of 2022 from the world of SaaS and product-led growth
The Expansion Manifesto: Part 1/3
Friday, December 16, 2022
What SaaS can learn about expansion from cats
Meet the hottest speech AI tool in town: Deepgram
Tuesday, December 6, 2022
Hot off a $72M Series B in a market where Amazon Alexa is on pace to lose $10B and Google is eyeing cuts to Google Assistant
You Might Also Like
Animal Shine And Doctor Stein 🐇
Monday, March 3, 2025
And another non-unique app͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
upcoming analyst-led events
Monday, March 3, 2025
the future of the customer journey, tech M&A predictions, and the industrial AI arms race. CB-Insights-Logo-light copy Upcoming analyst-led webinars Highlights: The future of the customer journey,
last call...
Monday, March 3, 2025
are you ready? ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
🦄 Dimmable window technology
Monday, March 3, 2025
Miru is creating windows that uniformly tint—usable in cars, homes, and more.
Lopsided AI Revenues
Monday, March 3, 2025
Tomasz Tunguz Venture Capitalist If you were forwarded this newsletter, and you'd like to receive it in the future, subscribe here. Lopsided AI Revenues Which is the best business in AI at the
📂 NEW: 140 SaaS Marketing Ideas eBook 📕
Monday, March 3, 2025
Most SaaS marketing follows the same playbook. The same channels. The same tactics. The same results. But the biggest wins? They come from smart risks, creative experiments, and ideas you
17 Silicon Valley Startups Raised $633Million - Week of March 3, 2025
Monday, March 3, 2025
🌴 Upfront Summit 2025 Recap 💰 Why Is Warren Buffett Hoarding $300B in Cash 💰 US Crypto Strategic Reserve ⚡ Blackstone / QTS AI Power Strains 🇨🇳 Wan 2.1 - Sora of China ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
⛔ STOP paying suppliers upfront - even if they offer a cheaper price in return!
Monday, March 3, 2025
You're not really saving money if all your cash is stuck in inventory. Hey Friend , A lot of ecommerce founders think paying upfront for inventory at a lower price is a smart move. Not always!
13 Content & Media Deals 💰
Monday, March 3, 2025
Follow the money in media ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏ ͏
📂 EXACTLY how Teachable got the first $1M ARR
Monday, March 3, 2025
Here's what the founder of Teachable, Ankur Nagpal, said about growing Teachable to their first $1M in ARR. Later, they'd sell for $250M! Fall 2013 I was 24 years old and had just moved